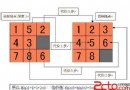
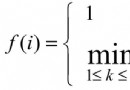OJ題目:click here~~ 題目分析:四柱漢諾
源碼下載:http://download.csdn.net
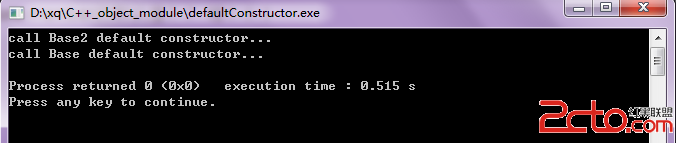
首先,本篇文章只講 “默認構造函數”,即如你所知,默認
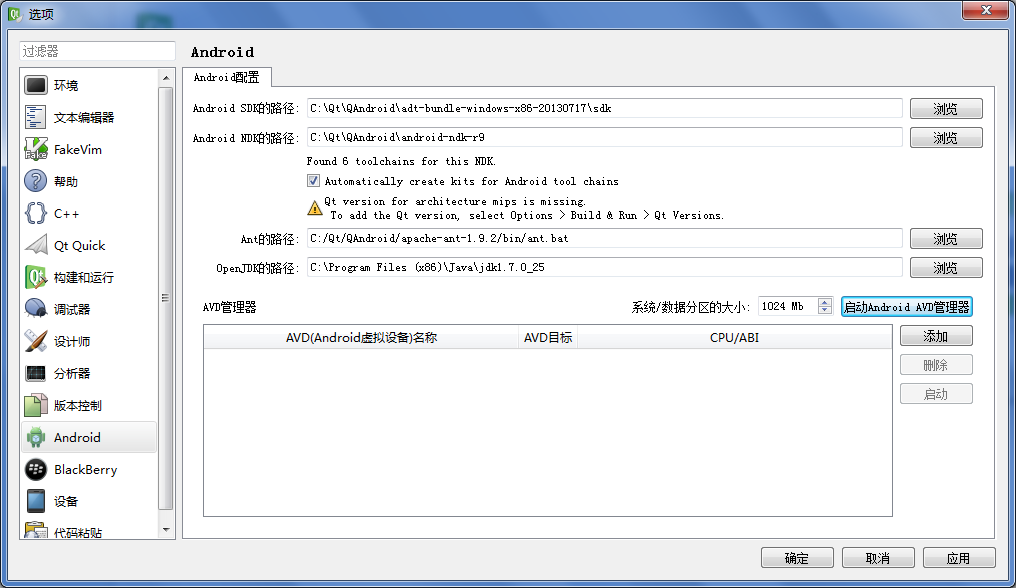
1.下載安裝Qt 5.1.0 for Android (Wi
想了挺久到底第一篇在這兒的博客寫什麼好,剛好這兩天又一次看到
Codeforces 527C Glass Carving(
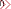 更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
以下是timer.h的內容 更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
遞歸遍歷的速度是最快的 更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
以下是timer.h的內容 更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
遞歸遍歷的速度是最快的 更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或
更多內容請看C/C++技術專題 數據結構 數據結構教程專題,或