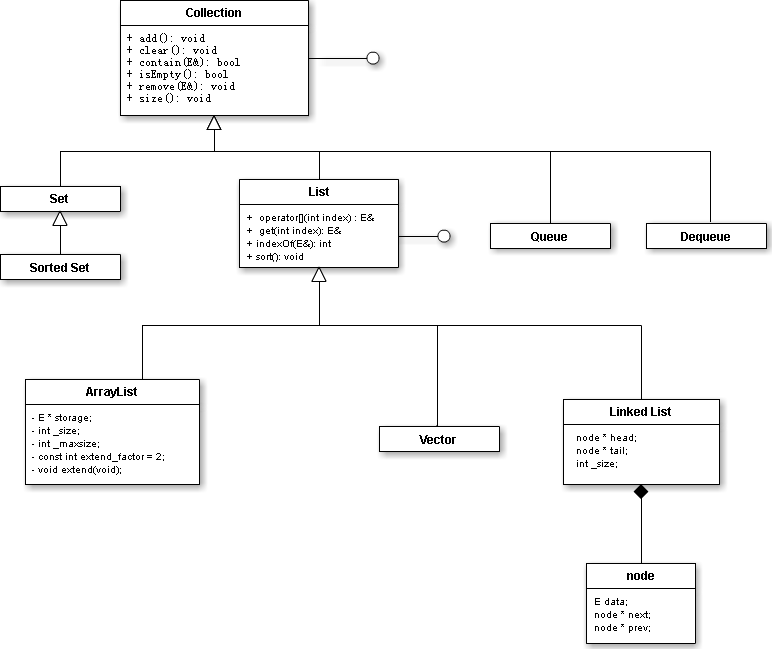
每個成員函數都有一個額外的隱含的形參,這個參數就是this指針,它指向調用對象的地址。默認情況下,this的類型是指向類類型非常量版本的常量指針。可以表示成如下偽代碼形式:
/* 假設現在有一個類Sales_data,以及其非常量Sales_data類型對象,則該隱式的this指針可以寫成如下偽代碼形式 */ Sales_data *const this = &total;
this指針一般用於解決重名問題和返回自身的值或者引用。例如:
struct A{
int a;
void test(int a){
this->a = a;
}
};
test函數的形參a和類成員a成名,根據就近原則,直接使用a,調用的是形參a,那麼如何使用被屏蔽的成員a呢,這裡就是采用this指針。
緊隨參數列表之後的const關鍵字作用為:修改隱式this指針所指向的對象的類型,如下:
/* 假設現在有一個類Sales_data,以及Sales_data類型對象,則在const成員函數中隱式的this指針可以寫成如下偽代碼形式 */ const Sales_data *const this = &total;
這裡加const的含義是,這個函數不能修改本對象,其實就是函數體內不得對類的成員進行修改。const主要起到保護的作用。
注意以下幾點:
a)非const對象可以調用const成員函數,也可以調用非const成員函數,但是const對象只能調用const成員函數。並且,非const對象優先調用非const成員函數。
b)const成員函數只可以返回本對象的常量引用,如下寫法會報錯:
Student &print(ostream &os) const
{
os << id_ << " " << name_ << " " << age_ << endl;
return *this;
}
報錯提示:
clang下:error: binding of reference to type 'Student' to a value of type 'const Student' drops qualifiers
return *this;
g++下:error: invalid initialization of reference of type ‘Student&’ from e
return *this;
最後記住:構造函數不能為const。如果為const,怎麼完成初始化工作?!
到此為止,構成函數重載的要素有:類的名稱、函數名、函數形參表以及成員函數的const屬性。事實上,函數簽名就是由這幾個部分構成。
在這裡我們解釋一個問題: 為什麼C語言裡面沒有函數重載? 因為在編譯器編譯C程序時會維護一張符號表,C語言在記載函數的時候就是簡單的記錄函數的名字,所以函數名就是C函數的唯一標識。當我們試圖定義兩個名字相同的函數時,就發生了重定義。
C++是怎麼做的呢? 很顯然,對於普通函數,它的符號(唯一標識)是根據函數名和參數列表生成的,對於類的成員函數,還要加上類名和const屬性,所以我們進行函數重載的時候,這些函數在符號表中的標識是不相同的。 C++正是通過這種機制實現了函數的重載。
注意:C++編譯器生成函數符號的時候沒有考慮返回值,這也是函數重載和返回值無關的原因。
構造函數有一個特殊的地方,就是它可以包含一個構造函數初始化列表,如下:
Person(int id, const string &name, int age)
:_id(id), _name(name), _age(age){
}
雖然以下形式,也完全可以達到目的:
Person(int id, const string &name, int age){
_id = id;
_name = name;
_age = age;
}
但兩者是不同的。第一種形式帶構造函數初始值列表,執行的是真正的初始化工作;而第二種形式,進行的是賦值操作。
注意,即使構造函數沒有構造函數初始值列表(更確切的說是構造函數初始值列表為空),那麼類中的成員變量將會執行默認初始化。因此在以下情況我們必須使用構造函數默認初始化列表:
a)const內置類型變量以及沒有顯示定義默認構造函數的const類類型變量(可以參考該博文合成的默認構造函數定義為delete的一種情況)
b)引用類型成員
c)沒有默認構造函數的類類型變量
其本質是因為,const內置類型變量和引用類型必須初始化;而對於類類型對象,可以通過默認構造函數進行默認初始化(非const類類型對象只要有默認構造函數就可以默認初始化,而const類類型對象必須有顯示定義的默認構造函數才可以執行默認初始化)
考慮下面的類:
class X {
int i;
int j;
public:
X(int val) :
j(val), i(j) {
}
};
我們的設想是這樣的,用val初始化j,用j的值初始化i,然而這裡初始化的次序是先i然後j。
記住:類成員初始化的順序是它們在類中聲明的順序,而不是初始化列表中列出的順序!
與構造函數一樣,析構函數也是一種特殊的函數。構造函數在對象被創建時調用,析構函數則是在對象被銷毀時被調用。構造函數與構造函數一樣,同樣沒有返回值,並且析構函數沒有任何參數。如下:
~Person(){
}
需要引起注意的是:
a)對於類類型對象foo的析構函數只是在它生命期的最後一刻的回調罷了,管不了foo自己所占的內存,就像自己沒法給自己收屍一樣。
b)對於堆上的類類型對象:free 干的事情是釋放內存。delete 干的事情是調用析構函數,然後釋放內存,注意是delete釋放的內存空間,而不是析構函數釋放的。對於棧上的類類型對象,退出作用域時會自動調用析構函數,然後釋放內存。
總結:對於棧上的類類型對象其實和內置類型變量一樣,退出作用域後都是由系統自動釋放內存的。實際上無論是棧空間,還是堆空間,內置類型對象和類類型對象銷毀時的區別,在於類對象會在銷毀前調用析構函數。
不用於普通的數據成員,static 數據成員獨立於該類的任何一個對象而存在,每個static數據成員是與類關聯,並不與該類的對象相關聯。
正如類可以定義共享的 static 數據成員一樣,類也可以定義 static 成員函數。static 成員函數沒有 this 形參(因為static成員不屬於任何一個對象),它可以直接訪問所屬類的 static 成員,但不能直接使用非 static 成員(因為沒有this指針)。當我們在類的外部定義 static 成員時,無須重復指定 static 保留字,該保留字只出現在類定義體內部的聲明處即可。
小結:
a)static 成員是類的組成部分但不是任何對象的組成部分,因此,static 成員函數沒有 this 指針。
b)因為 static 成員不是任何對象的組成部分,所以 static 成員函數不能是const成員函數。因為,將成員函數聲明為 const 就是承諾不會修改該函數所屬的對象,而 static 成員不是任何對象的組成部分。
c)static 函數只能使用 static 成員,而不能直接調用普通成員(方法+數據成員),當然如果這樣寫,static void print(Test &t) 誰也擋不住其調用對象t的普通成員。
d)static 成員一般在類內聲明,類外定義。注意,當我們在類的外部定義 static 成員時,無須重復指定 static 保留字,該保留字只出現在類定義體內部的聲明處即可。
1. 必須先定義包含成員函數的類,才能將這個類的成員函數設置為另外一個類的友元。
2. 不必預先聲明類和非成員函數來將它們設為友元。
#include <iostream>
#include <string>
#include <vector>
using namespace std;
class Test
{
public:
friend class Other; //聲明某個類是Test的朋友
friend void bar(const Test &t); //聲明某個函數是Test的朋友
private:
int x_;
int y_;
};
class Other
{
public:
void foo(Test &t)
{
t.x_ = 10;
t.y_ = 20;
}
};
void bar(const Test &t)
{
cout << t.x_ << endl;
}
int main(int argc, const char *argv[])
{
Test t;
return 0;
}
注意:友元關系是單向的,以上例子中Test並不是Other的朋友,因此Test不能訪問Other的private成員。(tmd,這不就是在告訴我們,你的是我的,我的還是我的)。順便黑一下C++:
C++ is a modern language where your parent can't touch your privates but your friends can.
多麼痛的領悟。
順序容器主要是vector和list,他們的初始化方式有以下五種:
1. 直接初始化一個空的容器
2. 用一個容器去初始化另一個容器
3. 指定容器的初始大小
4. 指定容器的初始大小和初始值
5. 用一對迭代器范圍去初始化容器
第2種和第5種初始化方式的區別在於:第2種不僅要求容器類型相同,還要求容器元素類型完全一致,而第5種不要求容器相同,對於容器元素,要求能相互兼容即可。
指針可以當做迭代器,所以可以這樣做:
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main(int argc, char **argv) {
const size_t MAX_SIZE = 3;
string arr[MAX_SIZE] = { "hello", "world", "foobar" };
vector<string> vec(arr, arr + MAX_SIZE);
return 0;
}
注意,凡是傳入迭代器作為指定范圍的參數,可以使用指針代替。
凡是放入vector中的元素,必須具備復制和賦值的能力,因為放入vector中的元素只是一份拷貝。下例會報錯。
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//Test不支持復制和賦值。所以不能放入vector
class Test
{
public:
Test() {}
private:
//設為私有,禁用了Test的復制和賦值能力
Test(const Test &); //用於復制(拷貝構造函數)
void operator=(const Test &); //用於賦值(賦值運算符)
};
int main(int argc, const char *argv[])
{
vector<Test> vec;
Test t;
vec.push_back(t);
return 0;
}
有四個特殊的迭代器:
c.begin() //指向容器C的第一個元素
C.end() //指向最後一個元素的下一個位置
C.rbegin() //返回一個逆序迭代器,指向容器c的最後一個元素
C.rend() //返回一個逆序迭代器,指向容器c的第一個元素的前面的位置
分別去順序迭代和逆序迭代容器,例如:
#include <iostream>
#include <string>
#include <vector>
#include <list>
using namespace std;
int main(int argc, char **argv) {
vector<string> vec;
vec.push_back("beijing");
vec.push_back("shanghai");
vec.push_back("guangzhou");
vec.push_back("shenzhen");
for (vector<string>::iterator iter = vec.begin(); iter != vec.end();
++iter) {
cout << *iter << endl;
}
for (vector<string>::reverse_iterator iter = vec.rbegin();
iter != vec.rend(); ++iter) {
cout << *iter << endl;
}
return 0;
}
/*
output:
beijing
shanghai
guangzhou
shenzhen
shenzhen
guangzhou
shanghai
beijing
*/
1. vector沒有push_front(vectoe內部實現是數組)。list有push_front。
2. 針對List
a)可以使用insert(p, t) 在指定位置元素之前添加元素,其中p是迭代器,t時元素的值
b)Insert(p, n, t) 在迭代器p指向的位置之前插入n個元素,初始值為t
c)Insert(p, b, e) 在迭代器p指向的位置之前插入迭代器b和迭代器e之間的元素
d)可是使用push_front 頭插
1. 刪第一個或最後一個元素
類似與插入元素,pop_front或者pop_back可以刪除第一個或者最後一個元素
2. 刪除容器的一個元素
與insert對應,刪除采用的是erase操作,該操作有兩個版本:刪除由一個迭代器指向的元素,或者刪除由一對迭代器標記的一段元素。刪除元素需要接收返回值,防止迭代器失效,最好使用while循環。
vector與容量有關的函數:
a)size 元素數目,類似於會議室中人的數目
b)resize 調整元素數目,類似於調整函數
c)capacity 可容納數目,類似於會議室中的座位數量
d)reserve 告訴vector容器應該預留多少個元素的存儲空間
任何insert或者push操作都可能導致迭代器失效。當編寫循環將元素插入到vector或list容器中時,程序必須確保迭代器在每次循環後都得到更新。
vector迭代器持續有效,除非:
1. 使用者在較小的索引位置插入或者刪除元素。
2. 由於容量的變化引起的內存重新分配。
list迭代器持續有效,除非:
將it指向的元素刪除,那麼it則失效(list內部實現是鏈表,it指向的元素刪了就是沒有了,再用it訪問直接段錯誤。vector也有可能失效,只不過後面的元素會往前移,再用it訪問可能不會產生段錯誤)。
刪除元素需要接收返回值,最好使用while循環。例如刪除下例刪除偶數:
vector<int>::iterator it = vec.begin();
while(it != vec.end())
{
if(*it % 2 == 0)
//vec.erase(it);
it = vec.erase(it);
else
++it;
}
遍歷vector方法:
1. 下標
2. 迭代器
3. for_each
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
void print(int i)
{
cout << i << endl;
}
int main(int argc, const char *argv[])
{
vector<int> vec;
vec.push_back(12);
vec.push_back(23);
vec.push_back(45);
vec.push_back(56);
vec.push_back(221);
vec.push_back(35);
vec.push_back(129);
for_each(vec.begin(), vec.end(), print);
return 0;
}
/*
output:
12
23
45
56
221
35
129
*/
a) vector采用數組實現,list采用鏈表。
b) vector支持隨機訪問,list不提供下標。
c) 大量增加刪除的操作適合使用list。
例子如下:
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main(int argc, const char *argv[])
{
string s = "helloworldfoo";
string s2 = s.substr(1, 4); //ello
cout << s2 << endl;
return 0;
}
注意,迭代器一般是取基地址到尾後地址的一段范圍。而下標操作,通常是基地址+長度。
#include <iostream>
#include <string>
#include <vector>
#include <stack>
using namespace std;
int main(int argc, const char *argv[])
{
stack<int> s;
s.push(10);
s.push(22);
s.push(23);
s.push(1);
s.push(8);
s.push(99);
s.push(14);
while(!s.empty())
{
cout << s.top() << endl;
s.pop();
}
return 0;
}
/*
輸出如下:
14
99
8
1
23
22
10
*/
#include <iostream>
#include <string>
#include <vector>
#include <queue>
using namespace std;
int main(int argc, const char *argv[])
{
queue<int> q;
q.push(12);
q.push(23);
q.push(4);
q.push(5);
q.push(7);
while(!q.empty())
{
cout << q.front() << endl;
q.pop();
}
return 0;
}
/*
輸出:
12
23
4
5
7
*/
例1:
#include <iostream>
#include <string>
#include <vector>
#include <queue>
using namespace std;
int main(int argc, const char *argv[])
{
priority_queue<int> q;
q.push(12);
q.push(99);
q.push(23);
q.push(123);
while(!q.empty())
{
cout << q.top() << endl;
q.pop();
}
return 0;
}
/*
output:
123
99
23
12
*/
例2:
#include <iostream>
#include <string>
#include <vector>
#include <queue>
using namespace std;
int main(int argc, const char *argv[])
{
priority_queue<int, vector<int>, greater<int> > q;
q.push(12);
q.push(99);
q.push(23);
q.push(123);
while(!q.empty())
{
cout << q.top() << endl;
q.pop();
}
return 0;
}
/*
output:
12
23
99
123
*/
#include <iostream>
#include <string>
#include <vector>
#include <queue>
using namespace std;
int main(int argc, const char *argv[])
{
priority_queue<int, vector<int>, less<int> > q;
q.push(12);
q.push(99);
q.push(23);
q.push(123);
while(!q.empty())
{
cout << q.top() << endl;
q.pop();
}
return 0;
}
/*
output:
123
99
23
12
*/
例3:傳入函數對象
#include <iostream>
#include <string>
#include <vector>
#include <queue>
using namespace std;
struct Score
{
int score_;
string name_;
Score(int score, const string name)
:score_(score), name_(name)
{ }
};
class Cmp
{
public:
bool operator() (const Score &s1, const Score &s2)
{
return s1.score_ < s2.score_;
}
};
// Cmp p;
// p(s1, s2)
int main(int argc, const char *argv[])
{
priority_queue<Score, vector<Score>, Cmp> q;
q.push(Score(67, "zhangsan"));
q.push(Score(88, "lisi"));
q.push(Score(34, "wangwu"));
q.push(Score(99, "foo"));
q.push(Score(0, "bar"));
while(!q.empty())
{
cout << q.top().name_ << " : " << q.top().score_ << endl;
q.pop();
}
return 0;
}
/*
output:
foo : 99
lisi : 88
zhangsan : 67
wangwu : 34
bar : 0
*/
反向迭代器邏輯上指向的元素是物理上指向元素的下一個元素。
在實際(物理)實現上,rbegin()指向最後一個元素的下一個位置,rend()指向第一個元素。但是在邏輯上,rbegin()指向最後一個元素,rend()指向第一個元素的前一個位置。
注意:reverse迭代器不能用於erase函數。刪除的正確方式是:it = string::reverse_iterator(s.erase((++it).base()));(見示例3)
示例1:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(int argc, const char *argv[])
{
vector<int> coll;
for (int i = 0; i <= 9 ; i++) // 0 1 2 3 4 5 6 7 8 9
{
coll.push_back(i);
}
vector<int>::iterator pos;
pos = find(coll.begin(), coll.end(), 5); // 此時pos物理指向的元素就是5
cout << "pos: " << *pos << endl; // 輸出5
vector<int>::reverse_iterator rpos(pos); // 反向迭代器物理上指向的元素確實是5
cout << "rpos: " << *rpos << endl; // 但是邏輯上指向的元素是它的下一個元素,在此處即為4
}
/*
output:
pos: 5
rpos: 4
*/
示例2:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
void print(int i)
{
cout << i << " ";
}
int main(int argc, const char *argv[])
{
vector<int> coll;
for (int i = 0; i <= 9 ; i++) // 0 1 2 3 4 5 6 7 8 9
{
coll.push_back(i);
}
vector<int>::iterator pos1;
pos1 = find(coll.begin(), coll.end(), 2); // pos1指向2
vector<int>::iterator pos2;
pos2 = find(coll.begin(), coll.end(), 7); // pos2指向7
for_each(pos1, pos2, print); // 輸出2 3 4 5 6
cout << endl;
vector<int>::reverse_iterator rpos1(pos1); // rpos1物理指向2,邏輯指向1
vector<int>::reverse_iterator rpos2(pos2); // rpos2物理指向7,邏輯指向6
for_each(rpos2, rpos1, print); // 輸出6 5 4 3 2
cout << endl;
}
/*
output:
2 3 4 5 6
6 5 4 3 2
*/
示例3:
#include <iostream>
#include <string>
#include <vector>
using namespace std;
int main(int argc, const char *argv[])
{
string s = "helloworld";
string::reverse_iterator it = s.rbegin(); // s.rbegin物理指向的元素最後一個元素之後的位置,邏輯指向的是最後一個元素
while(it != s.rend())
{
if(*it == 'r')
{
string::iterator tmp = (++it).base(); // 由於earse()參數不能是刪除反向迭代器,因此需要將其轉換為正向迭代器
tmp = s.erase(tmp); // 而it此時物理指向的元素並不是'r',++it後才物理指向‘r’,此時經base()轉換為正向迭代器後刪除
it = string::reverse_iterator(tmp); // 之後將正向迭代器轉換成反向迭代器
//it = string::reverse_iterator(s.erase((++it).base()));
}
else
++it;
}
cout << s << endl;
}
/*
output:
hellowold
*/
Pair是一種簡單的關聯類型。注意:pair不是容器,而是代表一個key-value鍵值對。
示例1:
#include <iostream>
#include <string>
#include <utility>
using namespace std;
int main(int argc, const char *argv[])
{
pair<int, int> p1;
p1.first = 10;
p1.second = 12;
pair<int, string> p2;
p2.first = 12;
p2.second = "hello";
pair<string, string> p3;
}示例2:
#include <iostream>
#include <string>
#include <vector>
using namespace std;
//生成pair對象的三種方法
int main(int argc, const char *argv[])
{
vector<pair<string, int> > vec;
pair<string, int> word;
word.first = "hello";
word.second = 12;
vec.push_back(word);
pair<string, int> word2("world", 12);
vec.push_back(word2);
vec.push_back(make_pair("foo", 3));
}
示例3:vector中裝入pair,實現統計詞頻:
#include <iostream>
#include <string>
#include <vector>
#include <utility>
using namespace std;
typedef vector<pair<string, int> > Dict;
void makeDict(Dict &dict, const vector<string> &words);
void addWordToDict(Dict &dict, const string &word);
int main(int argc, const char *argv[])
{
vector<string> words;
string word;
while(cin >> word)
words.push_back(word);
Dict dict;
makeDict(dict, words);
for(const pair<string, int> &p : dict)
{
cout << p.first << " : " << p.second << endl;
}
return 0;
}
void makeDict(Dict &dict, const vector<string> &words)
{
dict.clear();
for(vector<string>::const_iterator it = words.begin();
it != words.end();
++it)
{
addWordToDict(dict, *it);
}
}
void addWordToDict(Dict &dict, const string &word)
{
Dict::iterator it;
for(it = dict.begin();
it != dict.end();
++it)
{
if(it->first == word)
{
++it->second;
break;
}
}
if(it == dict.end())
dict.push_back(make_pair(word, 1));
}
map可以看做是一種存儲pair類型的容器,內部采用二叉樹實現(編譯器實現為紅黑樹)。
1. pair不是容器,而是代表一個key-value鍵值對;而map則是一個容器,裡面存儲了pair對象,只是存儲的方式與vector<pair>這種連續存儲,有所不同,map采用的是二叉排序樹存儲pair,一般而言是紅黑樹,因此內部是有序的
2. 當map使用下標訪問時,如果key不存在,那麼會在map中添加一個新的pair,value為默認值
示例1:
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main(int argc, const char *argv[])
{
map<string, int> m;
m["beijing"] = 2000;
m["shenzhen"] = 1000;
m["shanghai"] = 1500;
m["hongkong"] = 500;
m["hangzhou"] = 880;
for(map<string, int>::const_iterator it = m.begin();
it != m.end();
++it)
{
//*it pair
cout << it->first << " : " << it->second << endl;
}
return 0;
}
/*
output:
beijing : 2000
hangzhou : 880
hongkong : 500
shanghai : 1500
shenzhen : 1000
*/// 由於key是string類型,因此輸出按字典序。
示例2:
#include <iostream>
#include <string>
#include <vector>
#include <map>
using namespace std;
int main(int argc, const char *argv[])
{
map<string, int> m;
m["beijing"] = 40;
m["shenzhen"] = 30;
m["guangzhou"] = 37;
cout << m.size() << endl; //3
cout << m["shanghai"] << endl;
cout << m.size() << endl;
return 0;
}
/*
output:
3
0
4
*/3. map 的 key 必須具有小於操作符 operator <
以下為錯誤代碼:
#include <iostream>
#include <map>
using namespace std;
struct Test
{
int a;
};
int main(int argc, const char *argv[])
{
map<Test, int> m;
Test t;
m[t] = 1;
}
/* 編譯報錯,因為Test對象在次數為key-value對中的key,但其並沒有定義 operator< 運算符,紅黑樹無法進行排序 */
4. map查找元素的效率是lgn,因為樹的高度不超過O(lgN)
示例:使用map,實現統計詞頻,如下:
#include <iostream>
#include <string>
#include <vector>
#include <map>
using namespace std;
int main(int argc, const char *argv[])
{
map<string, int> words;
string word;
/* 如果key(word)存在,則value++; 如果word不存在,此處會在map(words)中添加一個新的pair,value為默認值(此處為0),然後value++ */
while(cin >> word)
words[word]++;
for(const pair<string, int> &p : words)
cout << p.first << " : " << p.second << endl;
return 0;
}
5. 在map中添加元素
剛才我們看到,采用下標的方式,可以給map添加元素,但更好的做法時采用insert插入一個pair對象。
這裡值得注意的是insert的返回值,其返回了一個pair對象,第一個元素是指向該key所在的那個pair對象的的迭代器,第二個則表示插入是否成功。使用insert插入map元素時,如果失敗,則不會更新原來的值。看下面例子:
#include <iostream>
#include <string>
#include <vector>
#include <map>
using namespace std;
int main(int argc, const char *argv[])
{
map<string, int> m;
m.insert(make_pair("hello", 1));
m.insert(make_pair("foo", 1));
m.insert(make_pair("bar", 1));
m.insert(make_pair("hello", 1));
cout << "size : " << m.size() << endl;
/* insert的返回值:指向key所在pair的迭代器,以及表示插入是否成功的布爾值 */
pair<map<string, int>::iterator, bool> ret;
// 之前沒有這個key,插入成功
ret = m.insert(make_pair("fwfgwfg", 23));
cout << "ret = " << ret.second << endl;
// 之前已有的key,插入失敗。插入失敗的話,不會更新原來的value值
ret = m.insert(make_pair("hello", 25425));
cout << "ret = " << ret.second << endl;
cout << ret.first->second << endl;
return 0;
}
/*
output:
size : 3
ret = 1
ret = 0
1
*/
下面的程序仍然是實現統計詞頻:
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main(int argc, const char *argv[])
{
map<string, int> words;
string word;
pair<map<string, int>::iterator, bool> ret;
while(cin >> word)
{
ret = words.insert(make_pair(word, 1));
if(ret.second == false) //word已經存在
++ret.first->second;
}
for(const pair<string, int> &p : words)
cout << p.first << " : " << p.second << endl;
return 0;
}
綜上,在本章中我們已經使用三種方式,去統計詞頻了,分別是:vector中使用pair, map的下標訪問方式以及map的insert方式。
6. 在map中查找元素
剛才看到可以利用下標獲取value的值,但是這樣存在一個弊端,如果下標訪問的是不存在的元素,那麼會自動給map增加一個鍵值對,這顯然不是我們所預期的。
我們可以采用 count 和 find 來解決問題,其中 count 僅僅能得出該元素是否存在,而 find 能夠返回該元素的迭代器。
示例1:
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main(int argc, const char *argv[])
{
map<string, string> m;
m["beijing"] = "bad";
m["shanghai"] = "just soso";
m["shenzhen"] = "well";
m["hangzhou"] = "good";
cout << m.count("hangzhou") << endl;
cout << m.count("HK") << endl;
return 0;
}
/*
output:
1
0
*/
示例2:
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main(int argc, const char *argv[])
{
map<string, string> m;
m["beijing"] = "bad";
m["shanghai"] = "just soso";
m["shenzhen"] = "well";
m["hangzhou"] = "good";
// find的返回值
map<string, string>::iterator it = m.find("HK");
if(it == m.end())
cout << "不存在" << endl;
else
cout << it->first << " : " << it->second << endl;
return 0;
}
/*
output:
不存在
*/
Set類似於數學上的集合,僅僅表示某個元素在集合中是否存在,而不必關心它的具體位置。同樣,set中的元素互異,也就是無法兩次插入相同的元素。set 底層采用紅黑樹實現,按照值進行排序,map則按照key進行排序。使用方式和map類似,但是簡單很多。
示例1:
#include <iostream>
#include <string>
#include <set>
using namespace std;
int main(int argc, const char *argv[])
{
set<int> s;
// set不會插入重復的元素
for(int i = 0; i < 20 ; ++i)
{
s.insert(i);
s.insert(i);
}
cout << "size : " << s.size() << endl;
return 0;
}
/*
output:
size : 20
*/
示例2:
#include <iostream>
#include <string>
#include <vector>
#include <set>
#include <stdlib.h>
using namespace std;
int main(int argc, const char *argv[])
{
srand(10000);
set<int> s;
for(int i = 0; i < 40; ++i)
{
s.insert(rand() % 100);
}
// 注意是有序的
for(int i : s)
{
cout << i << " ";
}
cout << endl;
return 0;
}
/*
output:
4 5 8 12 13 15 16 20 21 22 24 25 27 32 38 39 42 43 46 50 54 57 59 63 66 72 78 82 85 93 94 96 98
*/
map 中key 的值是唯一的,set 中的元素都是唯一的。
1. map和set比較:
a) 二者均使用紅黑樹實現
b) key需要支持<操作
c) map側重於key-value的快速查找
d) set側重於查看元素是否存在
2. 用戶無法對map和set中的元素進行排序,不然會干擾map和set本身的實現。
最後注意:map 的 key 值是不可更改的。而 set 中的 value 雖然可以更改,但不建議這樣做,真有需求,直接刪除即可。
c++11標准添加了 std::unordered_map 與 std::unordered_map。
map采用二叉樹實現,hash_map采用hash表,那麼二者的使用上:
a) 當key本身需要排序時,使用map
b) 其他情況采用hash_map更佳(hash_map無序),但是采用map效率也是足夠的。
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
using namespace std;
int main(int argc, const char *argv[])
{
unordered_map<string, int> m;
m["beijing"] = 1;
m["shanghai"] = 2;
m["shenzhen"] = 3;
for(unordered_map<string, int>::const_iterator it = m.begin();
it != m.end();
++it)
{
cout << it->first << " : " << it->second << endl;
}
}
/*
output:
shenzhen : 3
shanghai : 2
beijing : 1
*/
以下只是對小部分常用算法進行了介紹,但具體用法大同小異。
template <class InputIterator, class Function> Function for_each (InputIterator first, InputIterator last, Function fn);Apply function to range
Applies function fn to each of the elements in the range
[first,last).
#include <iostream>
#include <string>
#include <vector>
#include <list>
#include <algorithm>
#include <ctype.h>
using namespace std;
void toUpper(string &s)
{
for(string::iterator it = s.begin();
it != s.end();
++it)
{
if(islower(*it))
*it = toupper(*it);
}
}
void print(const string &s)
{
cout << s << " ";
}
int main(int argc, const char *argv[])
{
vector<string> vec;
vec.push_back("beijing");
vec.push_back("changchun");
vec.push_back("shijiahzuang");
vec.push_back("shenyang");
vec.push_back("dalian");
vec.push_back("jinan");
vec.push_back("nanjing");
for_each(vec.begin(), vec.end(), toUpper);
for_each(vec.begin(), vec.end(), print);
}
/*
output:
BEIJING CHANGCHUN SHIJIAHZUANG SHENYANG DALIAN JINAN NANJING
*/
count
template <class InputIterator, class T> typename iterator_traits<InputIterator>::difference_type count (InputIterator first, InputIterator last, const T& val);Count appearances of value in range
Returns the number of elements in the range
[first,last)that compare equal to val.
The function usesoperator==to compare the individual elements to val.
示例:
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int main(int argc, const char *argv[])
{
int myints[] = {10,20,30,30,20,10,10,20};
int mycount = count(myints, myints+8, 10);
cout << "10 appears " << mycount << " times." << endl;
vector<int> myvector(myints, myints+8);
mycount = count(myvector.begin(), myvector.end(), 20);
cout << "20 appears " << mycount << " times." << endl;
}
/*
output:
10 appears 3 times.
20 appears 3 times.
*/
count_if
template <class InputIterator, class Predicate> typename iterator_traits<InputIterator>::difference_type count_if (InputIterator first, InputIterator last, UnaryPredicate pred);Return number of elements in range satisfying condition
Returns the number of elements in the range
[first,last)for which pred is true.
示例:
/* count_if example */
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
bool IsOdd(int i)
{
return i % 2 == 1;
}
int main(int argc, const char *argv[])
{
vector<int> vec;
for(int i = 1; i < 10; ++i)
{
vec.push_back(i); //vec: 1 2 3 4 5 6 7 8 9
}
int mycount = count_if(vec.begin(), vec.end(), IsOdd);
cout << "vec contains " << mycount << " odd values." << endl;
}
/*
output:
vec contains 5 odd values.
*/
default (1)
template <class ForwardIterator> ForwardIterator min_element (ForwardIterator first, ForwardIterator last);custom (2)
template <class ForwardIterator, class Compare> ForwardIterator min_element (ForwardIterator first, ForwardIterator last, Compare comp);Return smallest element in range
Returns an iterator pointing to the element with the smallest value in the range
[first,last).The comparisons are performed using either
operator<for the first version, or comp for the second; An element is the smallest if no other element compares less than it. If more than one element fulfills this condition, the iterator returned points to the first of such elements.
示例:
// min_element/max_element example
#include <iostream> // std::cout
#include <algorithm> // std::min_element, std::max_element
bool myfn(int i, int j)
{
return i<j;
}
struct myclass {
bool operator() (int i,int j) { return i<j; }
} myobj;
int main () {
int myints[] = {3,7,2,5,6,4,9};
// using default comparison:
std::cout << "The smallest element is " << *std::min_element(myints,myints+7) << '\n';
std::cout << "The largest element is " << *std::max_element(myints,myints+7) << '\n';
// using function myfn as comp:
std::cout << "The smallest element is " << *std::min_element(myints,myints+7,myfn) << '\n';
std::cout << "The largest element is " << *std::max_element(myints,myints+7,myfn) << '\n';
// using object myobj as comp:
std::cout << "The smallest element is " << *std::min_element(myints,myints+7,myobj) << '\n';
std::cout << "The largest element is " << *std::max_element(myints,myints+7,myobj) << '\n';
return 0;
}
/*
output:
The smallest element is 2
The largest element is 9
The smallest element is 2
The largest element is 9
The smallest element is 2
The largest element is 9
*/
find
template <class InputIterator, class T> InputIterator find (InputIterator first, InputIterator last, const T& val);Find value in range
Returns an iterator to the first element in the range
[first,last)that compares equal to val. If no such element is found, the function returns last.The function uses
operator==to compare the individual elements to val.
find_if
template <class InputIterator, class UnaryPredicate> InputIterator find_if (InputIterator first, InputIterator last, UnaryPredicate pred);Find element in range
Returns an iterator to the first element in the range
[first,last)for which pred returnstrue. If no such element is found, the function returns last.
示例:
#include <iostream>
#include <string>
#include <vector>
#include <list>
#include <algorithm>
#include <ctype.h>
using namespace std;
void print(const string &s)
{
cout << s << " ";
}
bool isShorter(const string &s)
{
return s.size() < 6;
}
int main(int argc, const char *argv[])
{
vector<string> vec;
vec.push_back("beijing");
vec.push_back("changchun");
vec.push_back("shijiahzuang");
vec.push_back("shenyang");
vec.push_back("dalian");
vec.push_back("jinan");
vec.push_back("nanjing");
vector<string>::iterator it =
std::find(vec.begin(), vec.end(), "dalian");
cout << *it << endl;
//find_if
it = std::find_if(vec.begin(), vec.end(), isShorter);
cout << *it << endl;
}
/*
output:
dalian
jinan
*/
template <class InputIterator, class OutputIterator> OutputIterator copy (InputIterator first, InputIterator last, OutputIterator result);Copy range of elements
Copies the elements in the range
[first,last)into the range beginning at result.The function returns an iterator to the end of the destination range (which points to the element following the last element copied).
The ranges shall not overlap in such a way that result points to an element in the range [first,last). For such cases, see copy_backward.
示例(注意插入迭代器的用法):
#include <iostream>
#include <string>
#include <vector>
#include <list>
#include <algorithm>
#include <ctype.h>
using namespace std;
void print(const string &s)
{
cout << s << " ";
}
int main(int argc, const char *argv[])
{
vector<string> vec;
vec.push_back("beijing");
vec.push_back("changchun");
vec.push_back("shijiahzuang");
vec.push_back("shenyang");
vec.push_back("dalian");
vec.push_back("jinan");
vec.push_back("nanjing");
list<string> lst;
std::copy(vec.begin(), vec.end(), back_inserter(lst)); //執行的是push_back。如果填寫lst.begin(),需要list<string> lst(7);
for_each(lst.begin(), lst.end(), print);
cout << endl;
lst.clear();
std::copy(vec.begin(), vec.end(), front_inserter(lst)); //執行的是push_front。如果填寫lst.rbegin(),需要list<string> lst(7);
for_each(lst.begin(), lst.end(), print);
cout << endl;
return 0;
}
/*
output:
beijing changchun shijiahzuang shenyang dalian jinan nanjing
nanjing jinan dalian shenyang shijiahzuang changchun beijing
*/
c++11中新增了lambda表達式。
簡單來說,編程中提到的 lambda 表達式,通常是在需要一個函數,但是又不想費神去命名一個函數的場合下使用,也就是指匿名函數。
示例:
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <ctype.h>
using namespace std;
void toUpper(string &s)
{
for(string::iterator it = s.begin();
it != s.end();
++it)
{
if(islower(*it))
*it = toupper(*it);
}
}
void print(const string &s)
{
cout << s << " ";
}
int main(int argc, const char *argv[])
{
vector<string> vec;
vec.push_back("beijing");
vec.push_back("changchun");
vec.push_back("shijiahzuang");
vec.push_back("shenyang");
vec.push_back("dalian");
vec.push_back("jinan");
vec.push_back("nanjing");
for_each(vec.begin(), vec.end(), toUpper);
for_each(vec.begin(), vec.end(), [](const string &s) { cout << s << " "; } );
}
/*
output:
BEIJING CHANGCHUN SHIJIAHZUANG SHENYANG DALIAN JINAN NANJING
*/
a)根據一個類去顯式或者隱式初始化一個對象
b)復制一個對象,將它作為實參傳給一個函數
c)從函數返回時復制一個對象
那麼如何完成對象復制的工作?這裡需要的就是拷貝構造函數。
只有單個形參,而且該形參是本類類型對象的引用(常用const修飾),這樣的構造函數成為復制控制函數。
復制構造函數調用的時機就是在對象復制的時候。
如果什麼也不做,編譯器會自動幫我們合成一個默認的復制構造函數。
那麼如果我們自己來定義復制構造函數,應該怎麼寫?示例如下:
#include <iostream>
#include <string>
#include <vector>
using namespace std;
class Student
{
public:
Student() {}
Student(int id, const string &name, int age)
:id_(id), name_(name), age_(age)
{ }
Student(const Student &other)
:id_(other.id_),
name_(other.name_),
age_(other.age_)
{
}
void print() const
{
cout << id_ << " : " << name_ << " : " << age_;
}
private:
int id_;
string name_;
int age_;
};
int main(int argc, const char *argv[])
{
Student s(11, "zhangsan", 23);
s.print();
cout << endl;
Student s2(s); // 調用拷貝構造函數
s2.print();
cout << endl;
}
/*
output:
11 : zhangsan : 23
11 : zhangsan : 23
*/
現在來思考一個問題,既然編譯器生成的拷貝構造函數工作正常,那麼什麼時候需要我們自己來編寫拷貝構造函數呢?這就是下面的深拷貝和淺拷貝的問題。
我們通過自己定義的string類來解釋深拷貝與淺拷貝的問題。先來看以下這個錯誤版本的string類:
_string.h
#ifndef _STRING_H_
#define _STRING_H_
#include <stddef.h>
namespace __str
{
class string
{
public:
string();
string(const char*);
void debug() const;
size_t size() const;
~string();
private:
char *_str;
};
} /* namespace __str */
#endif /*_STRING_H_*/_string.cpp
#include "_string.h"
#include <iostream>
#include <string.h>
using namespace std;
namespace __str
{
string::string()
:_str(new char[1])
{ _str[0] = 0; }
string::string(const char *s)
:_str(new char[strlen(s) + 1])
{ strcpy(_str, s); }
size_t string::size() const
{ return strlen(_str); }
void string::debug() const
{ cout << _str << endl; }
string::~string()
{ delete []_str; }
} /* namespace __str */
main.cpp
#include "_string.h"
using namespace __str;
int main(int argc, const char *argv[])
{
string s("hello"); // 調用一個參數的構造函數
s.debug();
string s2(s); // 調用系統合成的拷貝構造函數
s2.debug();}
程序運行後,輸出兩次 hello,直接直接掛掉。為什麼會這樣子呢?
因為系統合成的拷貝構造函數,在復制String對象時,只是簡單的復制其中的_str的值,這樣復制完畢後,就有兩個String中的_str指向同一個內存區域,當對象析構時,發生兩次delete,導致程序錯誤
如何解決?
方案很簡單,就是我們在復制String時,不去復制str的值,而是復制其指向的內存區域。
我們自定義拷貝構造函數如下:
string::string(const String &s)
:str_(new char[strlen(s.str_) + 1])
{ strcpy(str_, s.str_); }
如此程序就可以正常運行,輸出兩次hello。
含有指針成員變量的類在復制時,有兩種選擇:
a) 復制指針的值,這樣復制完畢後,兩個對象指向同一塊資源,這叫做淺拷貝 shallow copy
b) 復制指針所指向的資源,復制完畢後,兩個對象各自擁有自己的資源,這叫做深拷貝 deep copy
注意:編譯器默認的是淺拷貝,此時如果需要深拷貝,需要自己編寫拷貝構造函數。
前面的復制構造函數說的是對象的復制,對象的賦值調用的則是對象的賦值運算符。
對於我們自定義的類(例如Student),我們是無法進行比較操作的,因為我們自定義的類沒有內置比較運算符(<= < > >= == !=),此時我們就可以通過運算符重載的規則給這些類加上運算符,這裡我們需要重載的就是賦值運算符。
當然,如果我們什麼也不做,系統也會自動合成一個賦值運算符,但是什麼時候需要我們自己來重載賦值運算符呢,仍然是考慮深拷貝和淺拷貝的問題。
對於剛剛我們自定義的string類這個例子而言,如果我們使用系統自動合成的賦值運算符,那麼同樣會引起錯誤。因為當發生賦值時,兩個string對象的_str仍然會指向同一片內存空間,那麼當程序退出時,會析構兩次,發生錯誤。
因此,我們應該自己來定義string類的賦值運算符,如下:
string& string::operator=(const string &s)// 自定義賦值運算符
{
// 防止自賦值,這樣執行delete的時候,會沖掉原有內容
if(this == &s)
{
return *this;
}
// 釋放原來指向的內存空間
delete []_str;
_str = new char[strlen(s._str) + 1];
strcpy(_str, s._str);
return *this;
}
注意:賦值操作符,需要先釋放掉以前持有的資源,同時必須處理自賦值的問題。
如果想禁止復制一個類,應該怎麼辦?
顯然需要把類的復制構造函數設為private,但是這樣以來類的friend仍然可以復制該類,於是我們只聲明這個函數,而不去實現。另外,如果你不需要復制該類的對象,最好把賦值運算也一並禁用掉。
所以這裡的做法是:把復制構造函數和賦值運算符的聲明設為private而不去實現。
注意:如果一個類,不需要復制和賦值,那就禁用這種能力,這可以幫助避免大量潛在的bug。
示例:
class Test
{
public:
Test() {}
~Test() {}
private:
Test(const Test &t);
void operator=(const Test &t);
};
實際上,更通用的做法是寫一個類noncopyable,凡是繼承該類的任何類都無法復制和賦值。
而google開源項目風格指南建議的做法是使用 DISALLOW_COPY_AND_ASSIGN 宏:
// 禁止使用拷貝構造函數和 operator= 賦值操作的宏
// 應該類的 private: 中使用
#define DISALLOW_COPY_AND_ASSIGN(TypeName) \
TypeName(const TypeName&); \
void operator=(const TypeName&)在 class foo 中使用方式如下:
class Foo {
public:
Foo(int f);
~Foo();
private:
DISALLOW_COPY_AND_ASSIGN(Foo);
};絕大多數情況下都應使用 DISALLOW_COPY_AND_ASSIGN 宏。如果類確實需要可拷貝,應在該類的頭文件中說明原由,並合理的定義拷貝構造函數和賦值操作。注意在 operator= 中檢測自我賦值的情況。為了能作為 STL 容器的值,你可能有使類可拷貝的沖動。在大多數類似的情況下,真正該做的是把對象的指針放到 STL 容器中。可以考慮使用智能指針。
1. 復制構造函數、賦值運算符以及析構函數,稱為三法則,一旦提供了其中一個,務必提供其余兩個。以我們之前自定義的string類為例:
a) 涉及到深拷貝、淺拷貝問題,所以需要提供拷貝構造函數
b) 然後,為了保持一致,賦值運算符也應該實現深拷貝
c) 既然實現深拷貝,那麼必定申請了資源(例如內存),所以必然需要析構函數來手工釋放。
2. 一個空類,編譯器提供默認無參數構造函數、拷貝構造函數、賦值運算符以及析構函數,一共四個函數(針對03標准,c++11中還有移動構造函數和移動賦值運算符)。
3. 對於復制和賦值,請務必保證在程序的語義上具有一致性。
4. 如果一個類,實現了像value一樣的復制和賦值能力(意味著復制和賦值後,兩個對象沒有任何關聯,或者邏輯上看起來無任何關聯),那麼就稱這個類的對象為值語義(value semantics)。如果類不能復制,或者復制後對象之間的資源歸屬糾纏不清,那麼稱為對象語義(object semantics),或者引用語義(reference semantics)。
(待續)
你輸入的x,n是多少?太大了可能會堆棧溢出,因為使用了遞歸調用
cin>>x>>n>>endl;
改成
cin>>x>>n;
錯誤提示的意思是程序中使用的 T 沒有聲明,程序不知道它的類型(int型還是char型或者指針、結構體、宏定義、類等等),因此無法處理。C/C++ 標准庫中並沒有關於 T 這個字符的類型和函數的定義,即使在泛型編程中我們經常用 T 表示任意類型,它也是先由class聲明它表示任意類型。所以你的問題並不是需要加頭文件,而是需要對T進行聲明。