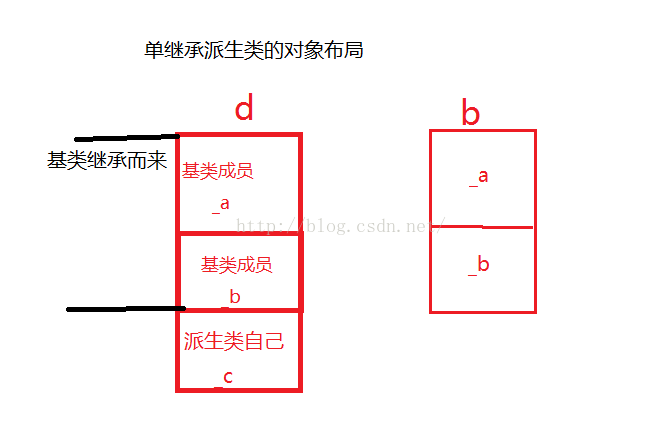
今天看數據結構的時候,因為是c語言版的,剛開始學的時候就對指針搞的焦頭爛額,今天,發現參數傳遞的時候,&符號也莫名其妙,搜了一篇好文,轉載下來。
一、函數參數傳遞機制的基本理論
函數參數傳遞機制問題在本質上是調用函數(過程)和被調用函數(過程)在調用發生時進行通信的方法問題。基本的參數傳遞機制有兩種:值傳遞和引用傳遞。以下討論稱調用其他函數的函數為主調函數,被調用的函數為被調函數。
值傳遞(passl-by-value)過程中,被調函數的形式參數作為被調函數的局部變量處理,即在堆棧中開辟了內存空間以存放由主調函數放進來的實參的值,從而成為了實參的一個副本。值傳遞的特點是被調函數對形式參數的任何操作都是作為局部變量進行,不會影響主調函數的實參變量的值。
引用傳遞(pass-by-reference)過程中,被調函數的形式參數雖然也作為局部變量在堆棧中開辟了內存空間,但是這時存放的是由主調函數放進來的實參變量的地址。被調函數對形參的任何操作都被處理成間接尋址,即通過堆棧中存放的地址訪問主調函數中的實參變量。正因為如此,被調函數對形參做的任何操作都影響了主調函數中的實參變量。
二、C語言中的函數參數傳遞機制
在C語言中,值傳遞是唯一可用的參數傳遞機制。但是據筆者所知,由於受指針變量作為函數參數的影響,有許多朋友還認為這種情況是引用傳遞。這是錯誤的。請看下面的代碼:
int swap(int *x, int *y)
{
int temp;
temp = *x; *x = *y; *y = temp;
return temp;
}
void main()
{
int a = 1, b = 2;
int *p1 = &a;
int *p2 = &b;
swap(p1, p2)
}
函數swap以兩個指針變量作為參數,當main()調用swap時,是以值傳遞的方式將指針變量p1、p2的值(也就是變量a、b的地址)放在了swap在堆棧中為形式參數x、y開辟的內存單元中。
這裡我們可以得到以下幾點:
1.進程的堆棧存儲區是主調函數和被調函數進行通信的主要區域。
2.C語言中參數是從右向左進棧的。
3.被調函數使用的堆棧區域結構為:
局部變量(如temp)
返回地址
函數參數
低地址
高地址
4.由主調函數在調用後清理堆棧。
5.函數的返回值一般是放在寄存器中的。
這裡尚需補充說明幾點:一是參數進棧的方式。對於內部類型,由於編譯器知道各類型變量使用的內存大小故直接使用push指令;對於自定義的類型(如structure),采用從源地址向目的(堆棧區)地址進行字節傳送的方式入棧。二是函數返回值為什麼一般放在寄存器中,這主要是為了支持中斷;如果放在堆棧中有可能因為中斷而被覆蓋。三是函數的返回值如果很大,則從堆棧向存放返回值的地址單元(由主調函數在調用前將此地址壓棧提供給被調函數)進行字節傳送,以達到返回的目的。對於第二和第三點,《Thinking in C++》一書在第10章有比較好的闡述。四是一個顯而易見的結論,如果在被調函數中返回局部變量的地址是毫無意義的;因為局部變量存於堆棧中,調用結束後堆棧將被清理,這些地址就變得無效了。
三、C++語言中的函數參數傳遞機制
眾所周知,在c++中調用函數時有三種參數傳遞方式:
(1)傳值調用;
(2)傳址調用(傳指針);
(3)引用傳遞;
實際上,還有一種參數傳遞方式,就是全局變量傳遞方式。這裡的“全局”變量並不見得就是真正的全局的,所有代碼都可以直接訪問的,只要這個變量的作用域足夠這兩個函數訪問就可以了,比如一個類中的兩個成員函數可以使用一個成員變量實現參數傳遞,或者使用static關鍵字定義,或者使用namespace進行限制等,而這裡的成員變量在這種意義上就可以稱作是“全局”變量(暫時還沒有其它比“全局”更好的詞來描述)。當然,可以使用一個類外的真正的全局變量來實現參數傳遞,但有時並沒有必要,從工程上講,作用域越小越好。這種方式有什麼優點呢?
效率高!
的確,這種效率是所有參數傳遞方式中效率最高的,比前面三種方式都要高,無論在什麼情況下。但這種方式有一個致命的弱點,那就是對多線程的支持不好,如果兩個進程同時調用同一個函數,而通過全局變量進行傳遞參數,該函數就不能夠總是得到想要的結果。
下面再分別討論上面三種函數傳遞方式。
1.從功能上。按值傳遞在傳遞的時候,實參被復制了一份,然後在函數體內使用,函數體內修改參數變量時修改的是實參的一份拷貝,而實參本身是沒有改變的,所以如果想在調用的函數中修改實參的值,使用值傳遞是不能達到目的的,這時只能使用引用或指針傳遞。例如,要實現兩個數值交換。
void swap(int aint b)
void main(){
int a=1b=2
swap(a b)
}
這樣,在main()函數中的a b值實際上並沒有交換,如果想要交換只能使用指針傳遞或引用傳遞,如:
void swap(int paint pb)
或
void swap(int&raint&rb)
2.從傳遞效率上。這裡所說傳遞效率,是說調用被調函數的代碼將實參傳遞到被調函數體內的過程,正如上面代碼中,這個過程就是函數main()中的a b傳遞到函數swap()中的過程。這個效率不能一概而論。對於內建的intcharshort long float等4字節或以下的數據類型而言,實際上傳遞時也只需要傳遞1-4個字節,而使用指針傳遞時在32位cpu中傳遞的是32位的指針,4個字節,都是一條指令,這種情況下值傳遞和指針傳遞的效率是一樣的,而傳遞doublelong long等8字節的數據時,在32位cpu中,其傳值效率比傳遞指針要慢,因為8個字節需要2次取完。而在64位的cpu上,傳值和傳址的效率是一樣的。再說引用傳遞,這個要看編譯器具體實現,引用傳遞最顯然的實現方式是使用指針,這種情況下與指針的效率是一樣的,而有些情況下編譯器是可以優化的,采用直接尋址的方式,這種情況下,效率比傳值調用和傳址調用都要快,與上面說的采用全局變量方式傳遞的效率相當。
再說自定義的數據類型,classstruct定義的數據類型。這些數據類型在進行傳值調用時生成臨時對象會執行構造函數,而且當臨時對象銷毀時會執行析構函數,如果構造函數和析構函數執行的任務比較多,或者傳遞的對象尺寸比較大,那麼傳值調用的消耗就比較大。這種情況下,采用傳址調用和采用傳引用調用的效率大多數下相當,正如上面所說,某些情況下引用傳遞可能被優化,總體效率稍高於傳址調用。
3.從執行效率上講。這裡所說的執行效率,是指在被調用的函數體內執行時的效率。因為傳值調用時,當值被傳到函數體內,臨時對象生成以後,所有的執行任務都是通過直接尋址的方式執行的,而指針和大多數情況下的引用則是以間接尋址的方式執行的,所以實際的執行效率會比傳值調用要低。如果函數體內對參數傳過來的變量進行操作比較頻繁,執行總次數又多的情況下,傳址調用和大多數情況下的引用參數傳遞會造成比較明顯的執行效率損失。
綜合2、3兩種情況,具體的執行效率要結合實際情況,通過比較傳遞過程的資源消耗和執行函數體消耗之和來選擇哪種情況比較合適。而就引用傳遞和指針傳遞的效率上比,引用傳遞的效率始終不低於指針傳遞,所以從這種意義上講,在c++中進行參數傳遞時優先使用引用傳遞而不是指針。
4.從類型安全上講。值傳遞與引用傳遞在參數傳遞過程中都執行強類型檢查,而指針傳遞的類型檢查較弱,特別地,如果參數被聲明為void,那麼它基本上沒有類型檢查,只要是指針,編譯器就認為是合法的,所以這給bug的產生制造了機會,使程序的健壯性稍差,如果沒有必要,就使用值傳遞和引用傳遞,最好不用指針傳遞,更好地利用編譯器的類型檢查,使得我們有更少的出錯機會,以增加代碼的健壯性。
這裡有個特殊情況,就是對於多態的情況,如果形參是父類,而實參是子類,在進行值傳遞的時候,臨時對象構造時只會構造父類的部分,是一個純粹的父類對象,而不會構造子類的任何特有的部分,因為辦有虛的析構函數,而沒有虛的構造函數,這一點是要注意的。如果想在被調函數中通過調用虛函數獲得一些子類特有的行為,這是不能實現的。
5.從參數檢查上講。一個健壯的函數,總會對傳遞來的參數進行參數檢查,保證輸入數據的合法性,以防止對數據的破壞並且更好地控制程序按期望的方向運行,在這種情況下使用值傳遞比使用指針傳遞要安全得多,因為你不可能傳一個不存在的值給值參數或引用參數,而使用指針就可能,很可能傳來的是一個非法的地址(沒有初始化,指向已經delete掉的對象的指針等)。所以使用值傳遞和引用傳遞會使你的代碼更健壯,具體是使用引用還是使用,最簡單的一個原則就是看傳遞的是不是內建的數據類型,對內建的數據類型優先使用值傳遞,而對於自定義的數據類型,特別是傳遞較大的對象,那麼請使用引用傳遞。
6.從靈活性上。無疑,指針是最靈活的,因為指針除了可以像值傳遞和引用傳遞那樣傳遞一個特定類型的對象外,還可以傳遞空指針,不傳遞任何對象。指針的這種優點使它大有用武之地,比如標准庫裡的time( )函數,你可以傳遞一個指針給它,把時間值填到指定的地址,你也可以傳遞一個空指針而只要返回值。
以上討論了四種參數傳遞方式的優缺點,下面再討論一下在參數傳遞過程中一些共同的有用的技術。
1. const關鍵字。當你的參數是作為輸入參數時,你總不希望你的輸入參數被修改,否則有可能產生邏輯錯誤,這時可以在聲明函數時在參數前加上const關鍵字,防止在實現時意外修改函數輸入,對於使用你的代碼的程序員也可以告訴他們這個參數是輸入,而不加const關鍵字的參數也可能是輸出。例如strlen,你可以這樣聲明
int strlen(char str)
功能上肯定沒有什麼問題,但是你想告訴使用該函數的人,參數str是一個輸入參數,它指向的數據是不能被修改的,這也是他們期望的,總不會有人希望在請人給他數錢的時候,裡面有張100的變成10塊的了,或者真鈔變成假鈔了,他們希望有一個保證,說該函數不會破壞你的任何數據,聲明按如下方式便可讓他們放心:
int strlen(const char str)
可不可以給str本身也加一個限制呢,如果把地址改了數得的結果不就錯了嗎?總得給人點兒自由吧,只要它幫你數錢就行了,何必介意他怎麼數呢?只要不破壞你的錢就ok了,如果給str一個限制,就會出現問題了,按照上面的聲明,可以這樣實現:
int strlen(const char str)
{int cnt
if( !str) return 0
cnt = 0
while( (str++) ){
++cnt
}
return cnt
}
可是,如果你硬要把聲明改成
int strlen(const char const str)
上面的函數肯定就運行不了了,只能改用其它的實現方式,但這個不是太有必要。只要我們保護好我們的錢就行了,如果它數不對,下次我次不讓它數,再換個人就是了。
對於成員函數,如果我們要顯示給客戶代碼說某個成員函數不會修改該對象的值,只會讀取某些內容,也可以在該函數聲明中加一個const.
classperson
{......
public:
unsigned char age( void ) const//看到const就放心了,這個函數肯定不會修改m_age
private:
unsigned char m_age//我認為這個類型已經足夠長了,如果覺得不改可以改為unsigned long
}
2.默認值。個人認為給參數添加一個默認值是一個很方便的特性,非常好用,這樣你就可以定義一個具有好幾個參數的函數,然後給那些不常用的參數一些默認值,客戶代碼如果認為那些默認值正是他們想要的,調用函數時只需要填一些必要的實參就行了,非常方便,這樣就省去了重載好幾個函數的麻煩。可是我不明白c#為什麼把這個特性給去掉了,可能是為了安全,這樣就要求每次調用函數時都要顯示地給函數賦實參。所以要注意,這可是個雙刃劍,如果想用使刀的招跟對手武斗,很可能傷到自己。
3.參數順序。當同個函數名有不同參數時,如果有相同的參數盡量要把參數放在同一位置上,以方便客戶端代碼。
c++中經常使用的是常量引用,如將swap2改為:
Swap2(const int& x; const int& y)
這時將不能在函數中修改引用地址所指向的內容,具體來說,x和y將不能出現在"="的左邊。