對於C++默認構造函數,我曾經有兩點誤解:
類如果沒有定義任何的構造函數,那麼編譯器(一定會!)將為類定義一個合成的默認構造函數。
合成默認構造函數會初始化類中所有的數據成員。
第一個誤解來自於我學習C++的第一本書 《C++ Primer》,在書中392頁:“只有當一個類沒有定義構造函數時,編譯器才會自動生成一個默認構造函數”。
實際上這句話也沒有說錯,它說明了默認構造函數定義的必要非充分條件,然而卻給當時初學C++的我造成了一定的誤解。
第二個誤解依舊來自於Primer中的一句話:“合成的默認構造函數使用與變量初始化相同的規則來初始化成員。具有類類型的成員通過運行各自的默認構造函數來進行初始化”。然而這也是我理解的片面,因為Primer也說到了:“如果類包含內置或復合類型的成員,則該類不應該依賴於合成的默認構造函數”,言下之意就是合成的默認構造函數並不會初始化內置或復合類型的成員。
總結了我有這些誤解的原因,第一是初學時知識體系沒形成,對Primer中所說的內容沒有真正的理解,第二就是Primer在某種程度上的確不是C++初學者能看懂的書,或許看時覺得懂了,卻是遺漏了很多知識。也說明了Primer 是座寶庫,常常回顧將會有新的感悟。
讓我對上面兩個觀點產生疑惑,是在看《Effective C++》時,條款05《了解C++默認編寫並調用哪些函數》中說到“….惟有當這些函數被需要(被調用),它們才會被編譯器創建出來。” (“這些函數“指的是編譯器版本的復制構造函數、賦值操作符和析構函數,還包括了默認構造函數。)也就是說,默認構造函數“被需要”的時候編譯器才會幫我們合成,那什麼情況才是默認構造函數”被需要“呢?這個問題《Effective C++》並沒有給出答案,直到看了《深度探索C++對象模型》,才明白了編譯器何時才會幫我們合成一個默認構造函數。
我寫這篇文章的目的是給和我有同樣誤解或疑惑的C++初學者看的,如果你對合成默認構造函數已有充分的認識,請忽略本文的內容。
默認構造函數是可以不用實參進行調用的構造函數,它包括了以下兩種情況:
沒有帶明顯形參的構造函數。
提供了默認實參的構造函數。
類設計者可以自己寫一個默認構造函數。編譯器幫我們寫的默認構造函數,稱為“合成的默認構造函數”。強調“沒有帶明顯形參”的原因是,編譯器總是會為我們的構造函數形參表插入一個隱含的this指針,所以”本質上”是沒有不帶形參的構造函數的,只有不帶明顯形參的構造函數,它就是默認構造函數。
如果定義一個對象時沒有提供初始化式,就使用默認構造函數。例如:
class A
{
public:
A(bool _isTrue= true, int _num=10){ isTrue = isTrue; num = _num; }; //默認構造函數
bool isTrue;
int num;
};
int main()
{
A a; //調用類A的默認構造函數
}
前面提到在《Effective C++》中指出惟有默認構造函數”被需要“的時候編譯器才會合成默認構造函數。關鍵字眼是”被需要“。被誰需要?做什麼事情?像下面這段代碼,默認構造函數”被需要“了嗎?
class A
{
public:
bool isTrue;
int num;
};
int main()
{
A a;
if (a.isTrue)
cout << a.num;
return 0;
}
你可能認為這裡定義類對象a的時候沒有提供參數且A沒有定義默認構造函數,編譯器肯定是合成了一個默認構造函數並調用它來初始化A的數據成員,實則不是。當你試圖查看合成默認構造函數把數據成員num初始化為什麼值的時候,你會發現編譯器甚至都讓你運行不了程序:

當類只含有內置類型或復合類型的成員時,編譯器是不會為類合成默認構造函數的,這種類並不符合”被需要“的條件,甚至當類滿足“被需要”條件,編譯器合成了默認構造函數時,類中內置類型與復合類型數據成員依然不會在默認構造函數中進行初始化。Primer中也有提到:“如果類包含內置或復合類型的成員,則該類不應該依賴於合成的默認構造函數“。
上面代碼中,默認構造函數”被需要“是對程序來說的,程序需要isTrue被初始化以便可以進行條件判斷,需要num被初始化以便可以輸出。然而這種需要並不會促使編譯器合成默認構造函數。惟有被編譯器所需要時,編譯器才會合成默認構造函數。那怎樣的類才是編譯器需要合成默認構造函數的呢?
總結:
合成默認構造函數總是不會初始化類的內置類型及復合類型的數據成員。
分清楚默認構造函數被程序需要與被編譯器需要,只有被編譯器需要的默認構造函數,編譯器才會合成它。
以下四種情況的類,編譯器總是需要默認構造函數完成某些工作:
1. 含有類對象數據成員,該類對象類型有默認構造函數。
如果一個類沒有任何構造函數,但是它含有一個類對象數據成員,且該類對象類型有默認構造函數,那麼編譯器就會為該類合成一個默認構造函數,不過這個合成操作只有在構造函數真正需要被調用的時候才會發生。舉個例子,編譯器將為類B合成一個默認構造函數:
class A
{
public:
A(bool _isTrue=true, int _num = 0){ isTrue = _isTrue; num = _num; }; //默認構造函數
bool isTrue;
int num;
};
class B
{
public:
A a;//類A含有默認構造函數
int b;
//...
};
int main()
{
B b; //編譯至此時,編譯器將為B合成默認構造函數
return 0;
}
被合成的默認構造函數做了什麼事情?大概如下面這樣:
B::B()
{
a.A::A();
}
被合成的默認構造函數內只含必要的代碼,它完成了對數據成員a的初始化,但不產生任何代碼來初始化B::b。正如上面所說,初始化類的內置類型或復合類型成員是程序的責任而不是編譯器的責任。為了滿足程序的需要,我們一般會自己寫構造函數來對B::b進行初始化,像這樣:
B::B()
{
a.A::A(); //編譯器插入的代碼
b = 0; //顯示定義的代碼
}
如果類中有多種類對象成員,則編譯器按照這些類對象成員聲明的順序,在構造函數按順序插入調用各個類默認構造函數的代碼。
當一個類派生自一個含有默認構造函數的基類時,該類也符合編譯器需要合成默認構造函數的條件。編譯器合成的默認構造函數將根據基類聲明順序調用上層的基類默認構造函數。同樣的道理,如果設計者定義了多個構造函數,編譯器將不會重新定義一個合成默認構造函數,而是把合成默認構造函數的內容插入到每一個構造函數中去。
類帶有虛函數可以分為兩種情況:
類本身定義了自己的虛函數
類從繼承體系中繼承了虛函數(成員函數一旦被聲明為虛函數,繼承不會改變虛函數的”虛性質“)。
這兩種情況都使一個類成為帶有虛函數的類。這樣的類也滿足編譯器需要合成默認構造函數的類,原因是含有虛函數的類對象都含有一個虛表指針vptr,編譯器需要對vptr設置初值以滿足虛函數機制的正確運行,編譯器會把這個設置初值的操作放在默認構造函數中。如果設計者沒有定義任何一個默認構造函數,則編譯器會合成一個默認構造函數完成上述操作,否則,編譯器將在每一個構造函數中插入代碼來完成相同的事情。
虛基類的概念是存在於類與類之間的,是一種相對的概念。例如類A虛繼承於類X,則對於A來說,類X是類A的虛基類,而不能說類X就是一個虛基類。虛基類是為了解決多重繼承下確保子類對象中每個父類只含有一個副本的問題,比如菱形繼承。如下圖:
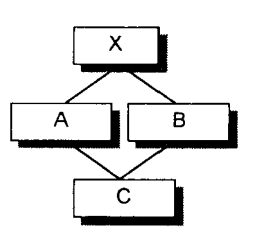
於是,類A對象中含有一份類X對象,類C中也含有一份類X對象,當我們遇上如下代碼時:
class X { public: int i; };
class A : public virtual X{ public:int j; };
class B : public virtual X{ public:double d; };
class C : public A, public B{ public: int k; };
void function(A *pa)
{
pa->i = 1000;
}
int main()
{
A *a= new A();
C *c= new C();
function(a); //關注重點在這裡
function(c); //關注重點在這裡
return 0;
}
函數function參數pa的真正類型是可以改變的,既可以把A對象指針賦值給pa,也可以把對象指針賦值給pa,在編譯階段並無法確定pa存儲的i是屬於A還是C的虛基類對象。為了解決這問題,編譯器將產生一個指向虛基類X的指針,使得程序得以在運行期確定經由pa而存取的X::i的實際存儲位置。這個指針的安插,編譯器將會在合成默認構造函數中完成,同樣的,如果設計者已經寫了多個構造函數,那麼編譯器不會重新寫默認構造函數,而是把虛基類指針的安插代碼插入已有的構造函數中。
總結
重新強調文章開篇所提,以下兩個觀點都是誤解:
a) 任何類如果沒有定義構造函數,則編譯器會幫我們合成一個默認構造函數。
b) 合成默認構造函數會對類中的每一個數據成員進行初始化。
只有在編譯器需要默認構造函數來完成編譯任務的時候,編譯器才會為沒有任何構造函數的類合成一個默認構造函數,或者是把這些操作插入到已有的構造函數中去。
編譯器需要默認構造函數的四種情況,總結起來就是:
a) 調用對象成員或基類的默認構造函數。
b) 為對象初始化虛表指針與虛基類指針。
PS:如果本文哪個地方闡述不清楚或者錯誤,十分期待指出,多謝!
來源:http://www.cnblogs.com/QG-whz/p/4676481.html