初窺比較正經的項目,你會被那些眼花缭亂的不同的類型的字符串弄的頭昏腦漲嗎?什麼是Unicode,
什麼又是ANSI,下面就個人理解做一個比較深入的探討。
首先什麼是ANSI,American National Standards Institute美國國家標准協會,聽名字都知道,是制
定標准的機構,我們常用的記事本的默認編碼格式就是ANSI,這種編碼的特點是一個字符只有一個字
節,這讓我大中國等一些列東亞和阿拉伯國家情何以堪啊?我們的漢字可要兩個字節呢,或許是為了
適應國際化的需求,Unicode應運而生,Unicode有幾種不同的編碼格式,有UTF-8,UTF-16,UTF-32用
過QT的人應該對這些東西不陌生吧,但是又感覺很陌生,下面簡單說下UTF,Unicode Transformation Format(Unicode轉化格式),這裡UTF-8是將一些字符編碼為一字節,一些編碼為兩字節,一些編碼
為三字節,一些編碼為四字節。UTF-16是都編碼成兩接,UTF-32是都編碼成4字節。
有關編碼方式就說這麼多,為什麼Unicode好用大家也知道為什麼了,可能是為了迎合我大中國的獨特文字吧,就當這樣吧。
在讀程序的時候經常會看到這樣的頭文件
#ifdef UNICODE ... #else ... #endif
這裡的意思就是說,用UNICODE要執行...樣的操作,不定義又要執行什麼樣的操作。
先看一段比較簡單的代碼
typedef char CHAR typedef wchar_t WCHAR
這種定義應該還是能看懂的,就是char和wchar_t起個別名,分別叫CHAR和WCHAR,我們應該經常在程
序裡看到TCHAR這個東西,這裡應該就是執行了如下的定義
#ifdef UNICODE typedef WCHAR TCHAR #else typedef CHAR TCHAR #endif
這裡就是當使用Unicode編碼的時候TCHAR就代表WCHAR,使用其它的編碼方式的時候TCHAR就表示CHAR
這裡的TCHAR是個通用的表示方式,這裡應該注意的是CHAR是單字節字符,WCHAR是雙字節字符,所以
你在不同編碼方式下得到的sizeof(TCHAR)應該是不同的。
有了字符還不夠,我們要處理的是字符串啊,當然要有字符指針了,這個可以有,於是又有了如下的定義
typedef CHAR *PSTR, *LPSTR; typedef WCHAR *PWSTR, *LPWSTR;
這個看著就有點略暈了吧,那看這
typedef CHAR *PSTR typedef CHAR *LPSTR
這裡是把上面的第一行分解成兩行來寫的,也就是給CHAR *起個別名交PSTR,又給CHAR *起個別名叫
LPSTR,舉個例子,小張真名張三豐CHAR *),他媽給他起了個小名叫狗子(PSTR),上學的時候同學
又給起了個小名叫虎子(LPSTR),你叫狗子,虎子都是張三豐這個人。下面有關WCAHR的理解也是一樣
的,這裡有人可能會問為什麼起那麼多別名啊,這個是個歷史遺留問題,在以前的windows版本中,有
短指針和長指針之分 ,但在32位的版本中,已無此區分,但是已經成為習慣了,延續了下去,所以以
後看到P和LP是一樣的效果,就知道這東東是指針就行了。
這裡有人估計會聯想了,是不是要把這個CHAR *和WCHAR *也進行下統一啊,沒錯,是這樣的
#ifdef UNICODE typedef WCHAR *PTSRT, *LPSTR #else typedef CHAR *PTSTR, *LPSTR #endif
好了,管你UNICODE還是ANSI我只要加這樣的定義,以後就用LPSTR來表示字符指針了。
有人還不放過張三豐(CHAR *),上了班之後又有人給他起了個別名叫彪子(PTCHAR)
總結張三豐的一生,到目前有這麼多的外號:
typedef CHAR *PSTR, *LPSTR, *PTCHAR
當然最後這個是通用的形式,因為中間有T,應該是在ANSI編碼下進行這樣的定義,在Unicode編碼下
會有對應的一個WCHAR想對應
typedef WCHAR *PWSTR, *LPWSTR, *LPTSTR
有了這些還是不滿足,因為字符指針我怕做形參的時候裡面的數據被修改了啊,於是乎就有了常指
針,這個是不能改裡面的數據的,但是指針的指向是可以改變的。
const char *str = "123";
str就是一個常指針,裡面的數據“123”是不能改變的,但是可以改變str的指向。這就保證了數據的
安全,從此以後媽媽再也不用擔心我去做形參了。
系統為了怕大家寫著麻煩,就給這個常指針起了個別名
typedef CONST CHAR *PCSTR
只是在P後面多了個C,就表示是常的了,當然還是要進行統一化
#ifdef UNICODE typedef CONST WCHAR *PCTSTR, *LPCTSTR; #else typedef CONST CHAR *PCTSTR, *LPCTSTR; #endif
好了,這個常指針也被統一成PCTSTR或者LPCTSTR了。這下好了,有了這三種定義以後管你什麼編碼,
用字符我就用TCHAR, 用字符指針我就用PTSTR或者LPTSTR, 用常字符指針我就用PCTSTR或者
LPCTSTR,當我們查MSDN的時候會發現,輸入參數一般都是常指針,輸出一般都是普通指針,因為要是
輸出你給我常指針我就沒法修改了,帶不回去返回值了。
下面要說的就是重新認識下字符串,做個小結,來個練習
LONG WINAPI RegQueryValueEx( __in HKEY hKey, __in LPCTSTR lpValueName, LPDWORD lpReserved, __out LPDWORD lpType, __out LPBYTE lpData, __in_out LPDWORD lpcbData );
這裡來詳細講解下這個讀注冊表鍵值的函數,
hKey打開的注冊鍵的句柄,這裡就相當於是要打開一個存放鍵值的目錄,後面lpValueName是要查詢
的鍵的名字,這個名字是可以程序員自己起好的,當時創建的時候叫什麼,現在還應該叫什麼,作為
輸入數據這裡lpValueName毫不猶豫的選擇了LPCTSTR常指針,windows也怕程序員改裡面的東西
啊,後面的lpType和lpData是輸出,一個是輸出的類型,一個是輸出的數據,這裡注意了,lpData
是我們真正關心的東西,這裡的LPBYTE又是什麼呢?我們一探究竟
typedef BYTE far *LPBYTE; typedef unsigned char BYTE;
這裡的far是遠指針,但win32下的內存模式是平坦模式,所以無所謂遠近了,都一樣,在看下面的定
義,原來這個LPBYTE就是unsigned char *啊,無符號的字符指針,這裡定義一個無符號的字符數組,
再把數組名傳進去就可以了。
這裡還是給出簡單的調用的代碼
HKEY hResult;
RegOpenKey(HKEY_CURRENT_USER, STR_YY_REG_LOCATION, &hResult);
const int MaxResultLen = 1024;
TCHAR wideResult[MaxResultLen] = {0};
DWORD pcbData = sizeof(wideResult) - sizeof(TCHAR);
::RegQueryValueExW(hResult,STR_KEY_ROOT_PATH, NULL,NULL, (LPBYTE)wideResult, &pcbData);這裡的第三個參數是保留值,必須為NULL,至於為什麼就要問微軟了,最後一個參數要說明一下,是
一個DWORD的指針,指針裡面的地址指向的是要取出的緩沖區的大小,因此這個緩沖區的大小一定要超
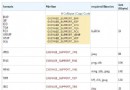
過要取的東西的長度,用一個圖來表示更清楚點。

這個wideResult是表示想要從緩沖區取回的數據的起始位置,而到底取多少,要lpcbData來告訴,這
裡形參lpcbData弄成了一個指針,那pcbData就要把要取多少先計算好,然後把地址傳過去就可以
COED了,這裡還有兩個問題:
1 為什麼要對pcbData進行一個-1字符的操作?我想可能是為了保證wideResult的安全,因為,試想
如果剛好pcbData的值和wideResult數組的大小相等,那麼wideResult就不能在尾部填‘\0’,這個
唯一標示字符串結束的標志了,這樣就可能造成內存上的危險。
2 wideResult為什麼要定義成TCHAR類型的數組?我想這裡可能是為了後續的處理方便,因為我們知
道,如果定義無符號的字符數組,取出來的字符串就要向TCHAR類型的字符串進行轉化,這裡就要用到
MulitiByteToWidChar()這個函數對數據進行轉化,這裡省去了這樣的麻煩,直接對輸入的數據進行
了強制轉化,這樣取回來的結果在不丟失精度的情況下完整的取出的數據,這裡相當於把每個字符是
兩字節的TCHAR降到了BYTE一個字節的數據,高位可能填0了,但是依然能夠保證取出的數據是和
BYTE數組取出的數據是一樣的。
本文出自 “賣萌程序員” 博客,請務必保留此出處http://7677869.blog.51cto.com/7667869/1289561