當前在網絡傳輸應用中,廣泛采用的是TCP/IP通信協議及其標准的socket應用開發編程接口(API)。TCP/IP傳輸層有兩個並列的協議:TCP和UDP。其中TCP(transport control protocol,傳輸控制協議)是面向連接的,提供高可靠性服務。UDP(user datagram protocol,用戶數據報協議)是無連接的,提供高效率服務。在實際工程應用中,對可靠性和效率的選擇取決於應用的環境和需求。一般情況下,普通數據的網絡傳輸采用高效率的udp,重要數據的網絡傳輸采用高可靠性的TCP。
在應用開發過程中,筆者發現基於TCP網絡傳輸的應用程序有時會出現粘包現象(即發送方發送的若干包數據到接收方接收時粘成一包)。針對這種情況,我們進行了專題研究與實驗。本文重點分析了TCP網絡粘包問題,並結合實驗結果提出了解決該問題的對策和方法,供有關工程技術人員參考。
一、TCP協議簡介TCP是一個面向連接的傳輸層協議,雖然TCP不屬於iso制定的協議集,但由於其在商業界和工業界的成功應用,它已成為事實上的網絡標准,廣泛應用於各種網絡主機間的通信。
作為一個面向連接的傳輸層協議,TCP的目標是為用戶提供可靠的端到端連接,保證信息有序無誤的傳輸。它除了提供基本的數據傳輸功能外,還為保證可靠性采用了數據編號、校驗和計算、數據確認等一系列措施。它對傳送的每個數據字節都進行編號,並請求接收方回傳確認信息(ack)。發送方如果在規定的時間內沒有收到數據確認,就重傳該數據。數據編號使接收方能夠處理數據的失序和重復問題。數據誤碼問題通過在每個傳輸的數據段中增加校驗和予以解決,接收方在接收到數據後檢查校驗和,若校驗和有誤,則丟棄該有誤碼的數據段,並要求發送方重傳。流量控制也是保證可靠性的一個重要措施,若無流控,可能會因接收緩沖區溢出而丟失大量數據,導致許多重傳,造成網絡擁塞惡性循環。TCP采用可變窗口進行流量控制,由接收方控制發送方發送的數據量。
TCP為用戶提供了高可靠性的網絡傳輸服務,但可靠性保障措施也影響了傳輸效率。因此,在實際工程應用中,只有關鍵數據的傳輸才采用TCP,而普通數據的傳輸一般采用高效率的udp。
二、粘包問題分析與對策
TCP粘包是指發送方發送的若干包數據到接收方接收時粘成一包,從接收緩沖區看,後一包數據的頭緊接著前一包數據的尾。
出現粘包現象的原因是多方面的,它既可能由發送方造成,也可能由接收方造成。發送方引起的粘包是由TCP協議本身造成的,TCP為提高傳輸效率,發送方往往要收集到足夠多的數據後才發送一包數據。若連續幾次發送的數據都很少,通常TCP會根據優化算法把這些數據合成一包後一次發送出去,這樣接收方就收到了粘包數據。接收方引起的粘包是由於接收方用戶進程不及時接收數據,從而導致粘包現象。這是因為接收方先把收到的數據放在系統接收緩沖區,用戶進程從該緩沖區取數據,若下一包數據到達時前一包數據尚未被用戶進程取走,則下一包數據放到系統接收緩沖區時就接到前一包數據之後,而用戶進程根據預先設定的緩沖區大小從系統接收緩沖區取數據,這樣就一次取到了多包數據(圖1所示)。
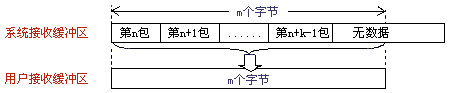
圖1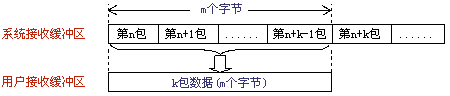
圖2
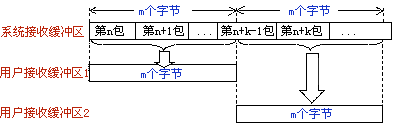
圖3
粘包情況有兩種,一種是粘在一起的包都是完整的數據包(圖1、圖2所示),另一種情況是粘在一起的包有不完整的包(圖3所示),此處假設用戶接收緩沖區長度為m個字節。
不是所有的粘包現象都需要處理,若傳輸的數據為不帶結構的連續流數據(如文件傳輸),則不必把粘連的包分開(簡稱分包)。但在實際工程應用中,傳輸的數據一般為帶結構的數據,這時就需要做分包處理。
在處理定長結構數據的粘包問題時,分包算法比較簡單;在處理不定長結構數據的粘包問題時,分包算法就比較復雜。特別是如圖3所示的粘包情況,由於一包數據內容被分在了兩個連續的接收包中,處理起來難度較大。實際工程應用中應盡量避免出現粘包現象。
為了避免粘包現象,可采取以下幾種措施。一是對於發送方引起的粘包現象,用戶可通過編程設置來避免,TCP提供了強制數據立即傳送的操作指令push,TCP軟件收到該操作指令後,就立即將本段數據發送出去,而不必等待發送緩沖區滿;二是對於接收方引起的粘包,則可通過優化程序設計、精簡接收進程工作量、提高接收進程優先級等措施,使其及時接收數據,從而盡量避免出現粘包現象;三是由接收方控制,將一包數據按結構字段,人為控制分多次接收,然後合並,通過這種手段來避免粘包。
以上提到的三種措施,都有其不足之處。第一種編程設置方法雖然可以避免發送方引起的粘包,但它關閉了優化算法,降低了網絡發送效率,影響應用程序的性能,一般不建議使用。第二種方法只能減少出現粘包的可能性,但並不能完全避免粘包,當發送頻率較高時,或由於網絡突發可能使某個時間段數據包到達接收方較快,接收方還是有可能來不及接收,從而導致粘包。第三種方法雖然避免了粘包,但應用程序的效率較低,對實時應用的場合不適合。
一種比較周全的對策是:接收方創建一預處理線程,對接收到的數據包進行預處理,將粘連的包分開。對這種方法我們進行了實驗,證明是高效可行的。
三、編程與實現
1.實現框架
實驗網絡通信程序采用TCP/IP協議的socket api編程實現。socket是面向客戶機/服務器模型的。TCP實現框架如圖4所示。
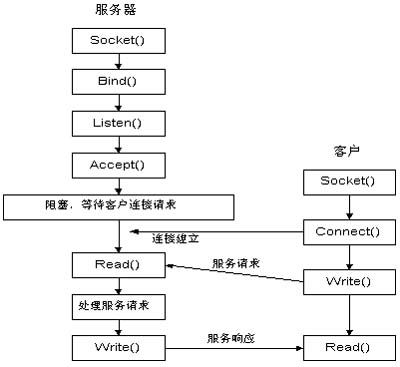
圖4
2.實驗硬件環境:
服務器:pentium 350 微機
客戶機:pentium 166微機
網絡平台:由10兆共享式hub連接而成的局域網
3.實驗軟件環境:
操作系統:windows 98
編程語言:visual c++ 5.0
4.主要線程
編程采用多線程方式,服務器端共有兩個線程:發送數據線程、發送統計顯示線程。客戶端共有三個線程:接收數據線程、接收預處理粘包線程、接收統計顯示線程。其中,發送和接收線程優先級設為thread_priority_time_critical(最高優先級),預處理線程優先級為thread_priority_above_normal(高於普通優先級),顯示線程優先級為thread_priority_normal(普通優先級)。
實驗發送數據的數據結構如圖5所示:

圖5
5.分包算法
針對三種不同的粘包現象,分包算法分別采取了相應的解決辦法。其基本思路是首先將待處理的接收數據流(長度設為m)強行轉換成預定的結構數據形式,並從中取出結構數據長度字段,即圖5中的n,而後根據n計算得到第一包數據長度。
1)若n<m,則表明數據流包含多包數據,從其頭部截取n個字節存入臨時緩沖區,剩余部分數據依此繼續循環處理,直至結束。
2)若n=m,則表明數據流內容恰好是一完整結構數據,直接將其存入臨時緩沖區即可。
3)若n>m,則表明數據流內容尚不夠構成一完整結構數據,需留待與下一包數據合並後再行處理。
對分包算法具體內容及軟件實現有興趣者,可與作者聯系。
四、實驗結果分析
實驗結果如下:
1.在上述實驗環境下,當發送方連續發送的若干包數據長度之和小於1500b時,常會出現粘包現象,接收方經預處理線程處理後能正確解開粘在一起的包。若程序中設置了“發送不延遲”:(setsockopt (socket_name,ipproto_tcp,tcp_nodelay,(char *) &on,sizeof on) ,其中on=1),則不存在粘包現象。
2.當發送數據為每包1kb~2kb的不定長數據時,若發送間隔時間小於10ms,偶爾會出現粘包,接收方經預處理線程處理後能正確解開粘在一起的包。
3.為測定處理粘包的時間,發送方依次循環發送長度為1.5kb、1.9kb、1.2kb、1.6kb、1.0kb數據,共計1000包。為制造粘包現象,接收線程每次接收前都等待10ms,接收緩沖區設為5000b,結果接收方收到526包數據,其中長度為5000b的有175包。經預處理線程處理可得到1000包正確數據,粘包處理總時間小於1ms。
實驗結果表明,TCP粘包現象確實存在,但可通過接收方的預處理予以解決,而且處理時間非常短(實驗中1000包數據總共處理時間不到1ms),幾乎不影響應用程序的正常工作。