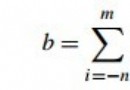2.2 使用寄存器
在前一節中的x86基本寄存器的介紹,對於一個匯編語言編程人員來說是不可或缺的。現在你知道,寄存器是處理器內部的一些保存數據的存儲單元。僅僅了解這些是不足以寫出一個可用的匯編語言程序的,但你已經可以大致讀懂一般匯編語言程序了(不必驚訝,因為匯編語言的祝記符和英文單詞非常接近),因為你已經了解了關於基本寄存器的絕大多數知識。
在正式引入第一個匯編語言程序之前,我粗略地介紹一下匯編語言中不同進制整數的表示方法。如果你不了解十進制以外的其他進制,請把鼠標移動到這裡。
數字計算機內部只支持二進制數,因為這樣計算機只需要表示兩種(某些情況是3種,這一內容超過了這份教程的范圍,如果您感興趣,可以參考數字邏輯電路的相關書籍)狀態. 對於電路而言,這表現為高、低電平,或者開、關,分別非常明顯,因而工作比較穩定;另一方面,由於只有兩種狀態,設計起來也比較簡單。這樣,使用二進制意味著低成本、穩定,多數情況下,這也意味著快速。
與十進制類似,我們可以用下面的式子來換算出一個任意形如am-1……a3a2a1a0 的m位r進制數對應的數值n:
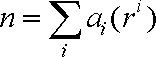
程序設計中常用十六進制和八進制數字代替二進制數,其原因在於,16和8是2的整次方冪,這樣,一位十六或八進制數可以表示整數個二進制位。十六進制中,使用字母A、B、C、D、E、F表示10-15,而十六進制或八進制數制表示的的數字比二進制數更短一些。
EAX的內容為000A3412h.
匯編語言中的整數常量表示
十進制整數
這是匯編器默認的數制。直接用我們熟悉的表示方式表示即可。例如,1234表示十進制的1234。不過,如果你指定了使用其他數制,或者有凡事都進行完整定義的小愛好,也可以寫成[十進制數]d或[十進制數]D的形式。
十六進制數
這是匯編程序中最常用的數制,我個人比較偏愛使用十六進制表示數據,至於為什麼,以後我會作說明。十六進制數表示為0[十六進制數]h或0[十六進制數]H,其中,如果十六進制數的第一位是數字,則開頭的0可以省略。例如,7fffh, 0ffffh,等等。
二進制數
這也是一種常用的數制。二進制數表示為[二進制數]b或[二進制數]B。一般程序中用二進制數表示掩碼(mask code)等數據非常的直觀,但需要些很長的數據(4位二進制數相當於一位十六進制數)。例如,1010110b。
八進制數
八進制數現在已經不是很常用了(確實還在用,一個典型的例子是Unix的文件屬性)。八進制數的形式是[八進制數]q、[八進制數]Q、[八進制數]o、[八進制數]O。例如,777Q。
需要說明的是,這些方法是針對宏匯編器(例如,MASM、TASM、NASM)說的,調試器默認使用十六進制表示整數,並且不需要特別的聲明(例如,在調試器中直接用FFFF表示十進制的65535,用10表示十進制的16)。
現在我們來寫一小段匯編程序,修改EAX、EBX、ECX、EDX的數值。
我們假定程序執行之前,寄存器中的數值是全0:
? X H L EAX 0000 00 00 EBX 0000 00 00 ECX 0000 00 00 EDX 0000 00 00正如前面提到的,EAX的高16bit是沒有辦法直接訪問的,而AX對應它的低16bit,AH、AL分別對應AX的高、低8bit。
mov eax, 012345678h則執行上述程序段之後,寄存器的內容變為:
? X H L EAX 1234 56 78 EBX abcd ef fe ECX 0000 00 01 EDX 0000 00 02那麼,你已經了解了mov這個指令(mov是move的縮寫)的一種用法。它可以將數送到寄存器中。我們來看看下面的代碼:
mov eax, ebx則寄存器內容變為:
? X H L EAX abcd ef fe EBX abcd ef fe ECX 0000 00 02 EDX 0000 00 02我們可以看到,“move”之後,數據依然保存在原來的寄存器中。不妨把mov指令理解為“送入”,或“裝入”。
練習題
把寄存器恢復成都為全0的狀態,然後執行下面的代碼:
mov eax, 0a1234h思考:此時,EAX的內容將是多少?[答案]
下面我們將介紹一些指令。在介紹指令之前,我們約定:
使用Intel文檔中的寄存器表示方式
reg32 32-bit寄存器(表示EAX、EBX等) reg16 16-bit寄存器(在32位處理器中,這AX、BX等) reg8 8-bit寄存器(表示AL、BH等) imm32 32-bit立即數(可以理解為常數) imm16 16-bit立即數 imm8 8-bit立即數在寄存器中載入另一寄存器,或立即數的值:
mov reg32, (reg32 | imm8 | imm16 | imm32)
mov reg32, (reg16 | imm8 | imm16)
mov reg8, (reg8 | imm8)
例如,mov eax, 010h表示,在eax中載入00000010h。需要注意的是,如果你希望在寄存器中裝入0,則有一種更快的方法,在後面我們將提到。
交換寄存器的內容:
xchg reg32, reg32例如,xchg ebx, ecx,則ebx與ecx的數值將被交換。由於系統提供了這個指令,因此,采用其他方法交換時,速度將會較慢,並需要占用更多的存儲空間,編程時要避免這種情況,即,盡量利用系統提供的指令,因為多數情況下,這意味著更小、更快的代碼,同時也杜絕了錯誤(如果說Intel的CPU在交換寄存器內容的時候也會出錯,那麼它就不用賣CPU了。而對於你來說,檢查一行代碼的正確性也顯然比檢查更多代碼的正確性要容易)剛才的習題的程序用下面的代碼將更有效:
mov eax, 0a1234h
遞增或遞減寄存器的值:
inc reg(8,16,32)這兩個指令往往用於循環中對指針的操作。需要說明的是,某些時候我們有更好的方法來處理循環,例如使用loop指令,或rep前綴。這些將在後面的章節中介紹。
將寄存器的數值與另一寄存器,或立即數的值相加,並存回此寄存器:
add reg32, reg32 / imm(8,16,32)
add reg16, reg16 / imm(8,16)
add reg8, reg8 / imm(8)
例如,add eax, edx,將eax+edx的值存入eax。減法指令和加法類似,只是將add換成sub。
需要說明的是,與高級語言不同,匯編語言中,如果要計算兩數之和(差、積、商,或一般地說,運算結果),那麼必然有一個寄存器被用來保存結果。在PASCAL中,我們可以用nA := nB + nC來讓nA保存nB+nC的結果,然而,匯編語言並不提供這種方法。如果你希望保持寄存器中的結果,需要用另外的指令。這也從另一個側面反映了“寄存器”這個名字的意義。數據只是“寄存”在那裡。如果你需要保存數據,那麼需要將它放到內存或其他地方。
類似的指令還有and、or、xor(與,或,異或)等等。它們進行的是邏輯運算。
我們稱add、mov、sub、and等稱為為指令助記符(這麼叫是因為它比機器語言容易記憶,而起作用就是方便人記憶,某些資料中也稱為指令、操作碼、opcode[operation code]等);後面的參數成為操作數,一個指令可以沒有操作數,也可以有一兩個操作數,通常有一個操作數的指令,這個操作數就是它的操作對象;而兩個參數的指令,前一個操作數一般是保存操作結果的地方,而後一個是附加的參數。
我不打算在這份教程中用大量的篇幅介紹指令——很多人做得比我更好,而且指令本身並不是重點,如果你學會了如何組織語句,那麼只要稍加學習就能輕易掌握其他指令。更多的指令可以參考Intel提供的資料。編寫程序的時候,也可以參考一些在線參考手冊。Tech!Help和HelpPC 2.10盡管已經很舊,但足以應付絕大多數需要。
聰明的讀者也許已經發現,使用sub eax, eax,或者xor eax, eax,可以得到與mov eax, 0類似的效果。在高級語言中,你大概不會選擇用a=a-a來給a賦值,因為測試會告訴你這麼做更慢,簡直就是在自找麻煩,然而在匯編語言中,你會得到相反的結論,多數情況下,以由快到慢的速度排列,這三條指令將是xor eax, eax、sub eax, eax和mov eax, 0。
為什麼呢?處理器在執行指令時,需要經過幾個不同的階段:取指、譯碼、取數、執行。
我們反復強調,寄存器是CPU的一部分。從寄存器取數,其速度很顯然要比從內存中取數快。那麼,不難理解,xor eax, eax要比mov eax, 0更快一些。
那麼,為什麼a=a-a通常要比a=0慢一些呢?這和編譯器的優化有一定關系。多數編譯器會把a=a-a翻譯成類似下面的代碼(通常,高級語言通過ebp和偏移量來訪問局部變量;程序中,x為a相對於本地堆的偏移量,在只包含一個32-bit整形變量的程序中,這個值通常是4):
mov eax, dword ptr [ebp-x]
sub eax, dword ptr [ebp-x]
mov dword ptr [ebp-x],eax
而把a=0翻譯成
mov dword ptr [ebp-x], 0
上面的翻譯只是示意性的,略去了很多必要的步驟,如保護寄存器內容、恢復等等。如果你對與編譯程序的實現過程感興趣,可以參考相應的書籍。多數編譯器(特別是C/C++編譯器,如Microsoft Visual C++)都提供了從源代碼到宏匯編語言程序的附加編譯輸出選項。這種情況下,你可以很方便地了解編譯程序執行的輸出結果;如果編譯程序沒有提供這樣的功能也沒有關系,調試器會讓你看到編譯器的編譯結果。
如果你明確地知道編譯器編譯出的結果不是最優的,那就可以著手用匯編語言來重寫那段代碼了。怎麼確認是否應該用匯編語言重寫呢?
使用匯編語言重寫代碼之前需要確認的幾件事情
首先,這種優化最好有明顯的效果。比如,一段循環中的計算,等等。一條語句的執行時間是很短的,現在新的CPU的指令周期都在0.000000001s以下,Intel甚至已經做出了4GHz主頻(主頻的倒數是時鐘周期)的CPU,如果你的代碼自始至終只執行一次,並且你只是減少了幾個時鐘周期的執行時間,那麼改變將是無法讓人察覺的;很多情況下,這種“優化”並不被提倡,盡管它確實減少了執行時間,但為此需要付出大量的時間、人力,多數情況下得不償失(極端情況,比如你的設備內存價格非常昂貴的時候,這種優化也許會有意義)。 其次,確認你已經使用了最好的算法,並且,你優化的程序的實現是正確的。匯編語言能夠提供同樣算法的最快實現,然而,它並不是萬金油,更不是解決一切的靈丹妙藥。用高級語言實現一種好的算法,不一定會比匯編語言實現一種差的算法更慢。不過需要注意的是,時間、空間復雜度最小的算法不一定就是解決某一特定問題的最佳算法。舉例說,快速排序在完全逆序的情況下等價於冒泡排序,這時其他方法就比它快。同時,用匯編語言優化一個不正確的算法實現,將給調試帶來很大的麻煩。 最後,確認你已經將高級語言編譯器的性能發揮到極致。Microsoft的編譯器在RELEASE模式和DEBUG模式會有差異相當大的輸出,而對於GNU系列的編譯器而言,不同級別的優化也會生成幾乎完全不同的代碼。此外,在編程時對於問題的嚴格定義,可以極大地幫助編譯器的優化過程。如何優化高級語言代碼,使其編譯結果最優超出了本教程的范圍,但如果你不能確認已經發揮了編譯器的最大效能,用匯編語言往往是一種更為費力的方法。 還有一點非常重要,那就是你明白自己做的是什麼。好的高級語言編譯器有時會有一些讓人難以理解的行為,比如,重新排列指令順序,等等。如果你發現這種情況,那麼優化的時候就應該小心——編譯器很可能比你擁有更多的關於處理器的知識,例如,對於一個超標量處理器,編譯器會對指令序列進行“封包”,使他們盡可能的並行執行;此外,宏匯編器有時會自動插入一些nop指令,其作用是將指令湊成整數字長(32-bit,對於16-bit處理器,是16-bit)。這些都是提高代碼性能的必要措施,如果你不了解處理器,那麼最好不要改動編譯器生成的代碼,因為這種情況下,盲目的修改往往不會得到預期的效果。
曾經在一份雜志上看到過有人用純機器語言編寫程序。不清楚到底這是不是編輯的失誤,因為一個頭腦正常的人恐怕不會這麼做程序,即使它不長、也不復雜。首先,匯編器能夠完成某些封包操作,即使不行,也可以用db偽指令來寫指令;用匯編語言寫程序可以防止很多錯誤的發生,同時,它還減輕了人的負擔,很顯然,“完全用機器語言寫程序”是完全沒有必要的,因為匯編語言可以做出完全一樣的事情,並且你可以依賴它,因為計算機不會出錯,而人總有出錯的時候。此外,如前面所言,如果用高級語言實現程序的代價不大(例如,這段代碼在程序的整個執行過程中只執行一遍,並且,這一遍的執行時間也小於一秒),那麼,為什麼不用高級語言實現呢?
一些比較狂熱的編程愛好者可能不太喜歡我的這種觀點。比方說,他們可能希望精益求精地優化每一字節的代碼。但多數情況下我們有更重要的事情,例如,你的算法是最優的嗎?你已經把程序在高級語言許可的范圍內優化到盡頭了嗎?並不是所有的人都有資格這樣說。匯編語言是這樣一件東西,它足夠的強大,能夠控制計算機,完成它能夠實現的任何功能;同時,因為它的強大,也會提高開發成本,並且,難於維護。因此,我個人的建議是,如果在軟件開發中使用匯編語言,則應在軟件接近完成的時候使用,這樣可以減少很多不必要的投入。
第二章中,我介紹了x86系列處理器的基本寄存器。這些寄存器對於x86兼容處理器仍然是有效的,如果你偏愛AMD的CPU,那麼使用這些寄存器的程序同樣也可以正常運行。
不過現在說用匯編語言進行優化還為時尚早——不可能寫程序,而只操作這些寄存器,因為這樣只能完成非常簡單的操作,既然是簡單的操作,那可能就會讓人覺得乏味,甚至找一台足夠快的機器窮舉它的所有結果(如果可以窮舉的話),並直接寫程序調用,因為這樣通常會更快。但話說回來,看完接下來的兩章——內存和堆棧操作,你就可以獨立完成幾乎所有的任務了,配合第五章中斷、第六章子程序的知識,你將知道如何駕馭處理器,並讓它為你工作。