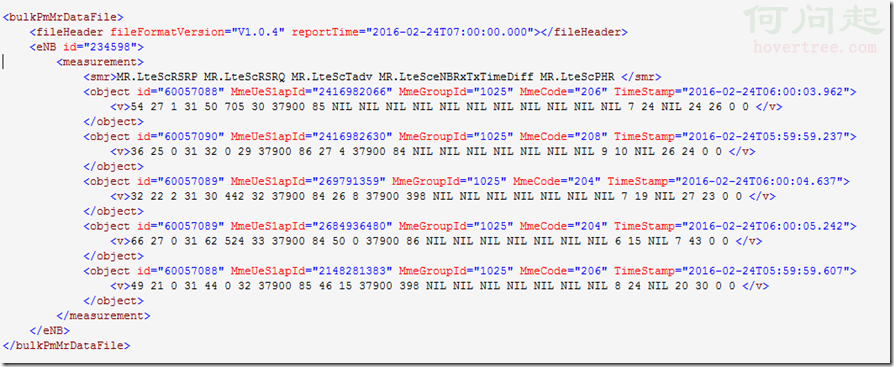
相信第一次處理中文的朋友們可能都會對中文的encoding 和程序的報錯很頭疼。
如果你像我一樣希望能夠把事情盡快做好而不去深究,你可能會寫一些異常處理的代碼把 UnicodeEncodingError糊弄過去先,但當你開始懷疑有多少encoding出錯的信息被你丟棄的時候,可能你會很驚奇。於是,你還是會想坐下來,(洗把臉)然後面對自己必須弄懂什麼是utf-8,什麼是 ‘gb2312’, 什麼是 ‘gbk’ 和其中的貓膩。正如有時候猛撕小傷口上邦迪膠布的快感一樣,有時候當你認真面對一些你平時一直回避的問題的時候(其實有時候需要的不是勇氣), 你反而會覺得“不過如此”,並且能夠一勞永逸的解決問題。
關於Python處理Unicode,我所能找到的最言簡意赅的入門教程是:
簡要羅列一下最重要最實用的點:
Solution
1. Decode early
Decode to <type ‘unicode’> ASAP
>>> def to_unicode_or_bust(
… obj, encoding=’utf-8′):
… if isinstance(obj, basestring):
… if not isinstance(obj, unicode):
… obj = unicode(obj, encoding)
… return obj
…
>>>
detects if object is a string and if so converts to unicode, if not already.
2. Unicode everywhere
>>> to_unicode_or_bust(ivan_uni)
u’Ivan Krsti\u0107′
>>> to_unicode_or_bust(ivan_utf8)
u’Ivan Krsti\u0107′
>>> to_unicode_or_bust(1234)
1234
3. Encode late
Encode to <type ‘str’> when you write to disk or print
>>> f = open(‘/tmp/ivan_out.txt’,’w’)
>>> f.write(ivan_uni.encode(‘utf-8′))
>>> f.close()
我以前一直覺得unicode相關的處理都是很 dirty 的工作,一般都會一邊嘗試,一邊用異常處理去補丁,看完以上這個教程以後豁然開朗。
祝大家也能早日理清處理中文的時候的頭緒,坦然直面“神秘”的unicode