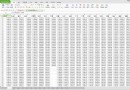
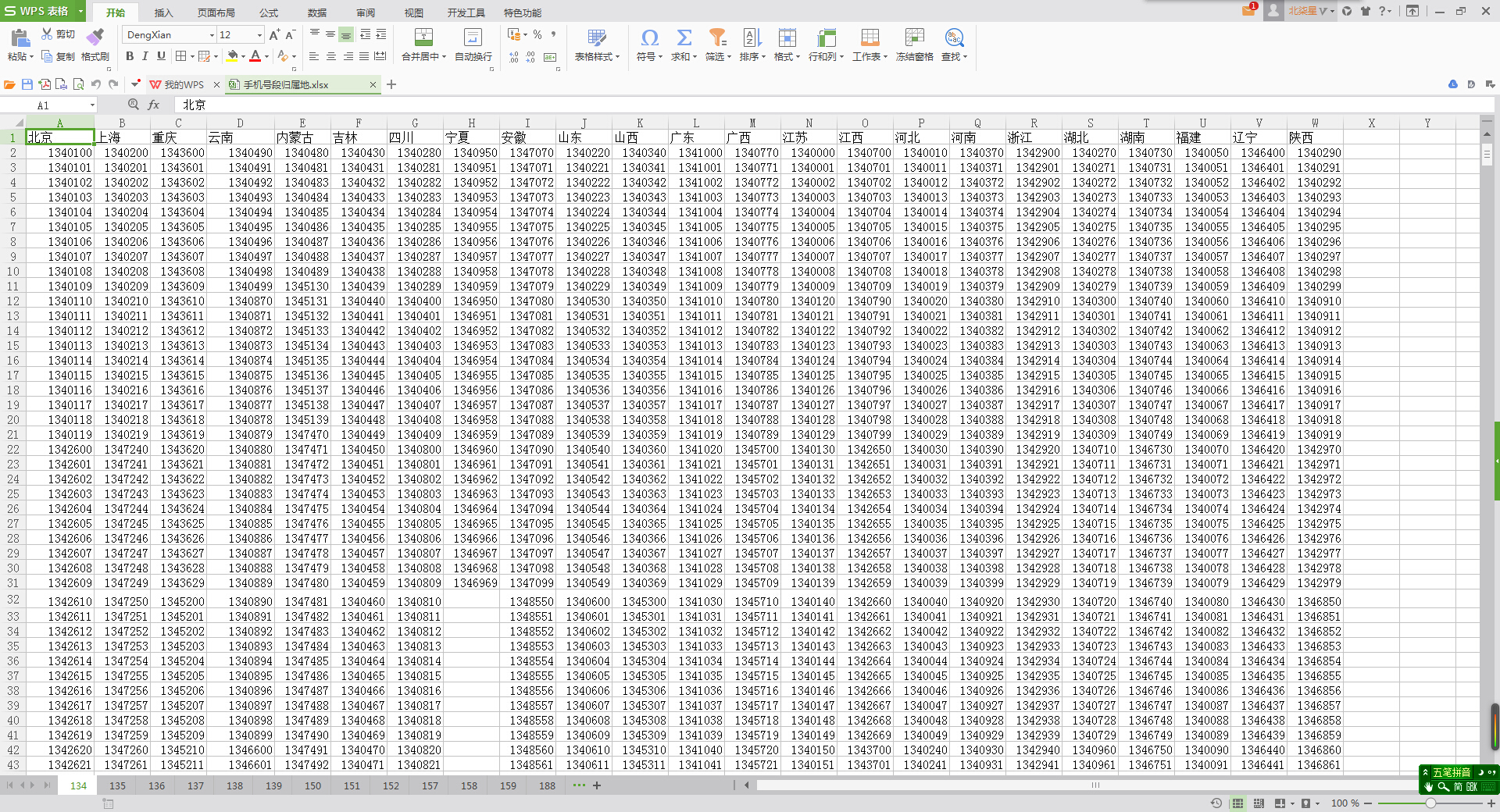
上周,老板給我一個小任務:批量生成手機號碼並去重。給了我一個Excel表,裡面是中國移動各個地區的可用手機號碼前7位(如下圖),裡面有十三張表,每個表裡的電話號碼前綴估計大概是八千個,需要這些7位號碼生成每個都生成後4位組成11位手機號碼,也就說每一個格子裡面的手機號碼都要生成一萬個手機號。而且還有,本來服務器已經使用了一部分手機號碼了,要在生成的號碼列表裡去掉已經使用過的那一批。已經使用過的這一批號碼已經導出到了一批txt文本裡,約4000w,每個txt有10w個號碼,裡面有重復的,老板估計實際大概是3000w左右。老板可以給我分配使用一個16G內存、8核CPU的Windows服務器來跑程序。
要處理海量數據,所以程序的執行效率和占用內存不能太高,應該能在開發機的4G內存下也大概跑得動(即關掉所有編程IDE和服務器軟件,只用Notepad++和浏覽器的情況下不會卡機)。這次任務可能會用到的技術有:程序Excel的處理,文件的遍歷和讀寫,大型數組的操作,多線程並發。預估任務完成周期:一周(日常工作正常進行的前提下)。
PHP:很熟悉,但是執行效率和內存占用不夠好,可能會卡機,要實現多線程似乎有點復雜。(有待斟酌)
Javascript:較熟悉,執行效率和內存占用不太清楚,但是弱類型通常都比較堪憂,各種回調比較干擾思維不順手。(不考慮)
Java:略懂,學起來和寫起來都比較麻煩,開發效率比較慢。(有待斟酌)
C#:沒用過,較難學(比JAVA易,比腳本難)。(有待斟酌)
C/C++:略懂,數組處理、多線程這兩個似乎比較難搞。(不考慮)
Python:沒用過,據說很容易學,有個研究生同學用物理運算等,執行效率應該不低。(試試看)
於是就打著試試看的心態,打開了菜鳥教程(Runoob)的Python教程大概看了一下,目錄中有幾個數組(List、元組、字典)、文件IO、File和多線程,看了一下例程果然好簡單。再度了一下python處理Excel,果斷簡單快捷!於是開啟了玩蛇之路。
本文開頭說到,有4000w的已用號碼列表,但是裡面是有重復的,而後面的處理都需要用到這些號碼。而看到這400多個txt文件加起來大小約500M,所以全部讀進去再進行處理也可以承受。所以先把這些文件讀進去合並去重,輸出成為一個txt文件。最後得到的號碼有1800w多條,輸出txt文件大小約209M。


#!/usr/bin/python
# -*- coding: UTF-8 -*-
#把所有的文本都讀出來
i = 1;
txtStrAll='';
while i<= 402: #402
fileobj = open('list-data- ('+ str(i) +').txt');
txtStr = fileobj.read();
txtStrAll += txtStr+'\n';
fileobj.close();
i+=1;
txtArr = txtStrAll.splitlines(); #分割成數組
print len( txtArr ); #39905386
txtArr = list(set(txtArr)); #去重
print len( txtArr ); #18316857
#合並成字符串,for in會要很久很久
newStr = '';
newStr = '\n'.join( txtArr );
#寫入txt
newFileObj = open('list-dataAll.txt', "wb");
newFileObj.write( newStr );
newFileObj.close();
hebing.py
其中對數組內的元素進行合並去重的那一句是 txtArr = list( set(txtArr) )。很神奇對吧,這兩個是什麼函數?其實這兩個都是轉換類型的函數。先把它轉換成了 set 類型,再轉換為 list 類型(列表/數組)。python的set(集合)類型是一個無序不重復的元素集,所以list轉換為set之後就自動去重了,當然同時順序也會被打亂了,不過這裡的順序不重要就不用管它啦。
最後數組轉換為字符串也是直接用字符串拼接數組就轉換了,不要用for循環,非常非常耗時間了。
根據網上例程直接讀取Excel第一個表裡面的內容出來,合並成數組轉成字符串存到文本裡面去。在轉成字符串的時候發現報錯似乎是說數據類型不對,才知道原來python與PHP、JS不同,是強類型的=_=!於是先在Excel裡把表裡面的數據轉換成字符串格式(excel裡准確叫文本格式),轉換後excel表裡面的數據格左上角是有綠色的小三角形的。每個表單獨處理生成一個文件,一個文件裡面大概有八千個手機號碼前綴。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
#讀取Excel,把每個表的 7位 號碼都讀取出來,存入文件
#共有13個表(三位數前綴),
#到python官網下載http://pypi.python.org/pypi/xlrd模塊安裝。
#安裝方法:進入下載的 xlrd的文件夾,執行命令 python setup.py install
import sys
reload(sys)
sys.setdefaultencoding('utf-8');
#解決'ascii' codec can't encode character, Python2默認是GB2312編碼
import xlrd
exel = xlrd.open_workbook('cellnum.xlsx');
tblIndex = 1; #第幾個表
table1 = exel.sheets()[tblIndex]; #第N個表
ncols = table1.ncols; #列數
#print ncols;
i=0;
dataAll = [];
while( i< ncols):
dataArr = table1.col_values( i );
# print dataArr;
for num in dataArr[:]: #每列中的數字格
if not num.isdigit() :
dataArr.remove(num);
dataAll.append( dataArr );
i += 1;
#dataAll 是一個表的數據List
#print dataAll;
#寫入txt
newStr = '';
for eCol in dataAll:
colStr = '\n'.join( eCol );
newStr += colStr+'\n';
newFileObj = open('exel-dataAll'+str(tblIndex)+'.txt', "wb");
newFileObj.write( newStr );
newFileObj.close();
preNum.py
首先來想想,有十三個表,一個表裡面有大概八千個號碼前綴,每個前綴生成一萬個號碼,每個號碼要與前面所說的1800萬的已用手機號碼進行比對去重。你會怎麼做呢???
↓↓
↓↓
我的想法是,分成十三次來做,每次一個表,每個表中八千多個號碼,使用多線程,八千多個線程,每個線程生成一萬個號碼並與那1800萬個號碼一 一比對。
其中生成和去重的核心代碼如下,每生成一個號碼的時間大概是0.5秒。所以估計了一下時間,10000*0.5s ≈ 83min,八千個進程大概要一個半小時左右。
#這裡是重復的號碼
#fileobj = open('testBugNum.txt'); #測試的
fileobj = open('list-dataAll.txt'); #實際的
bugTxtStr = fileobj.read();
fileobj.close();
bugTxtArr = bugTxtStr.splitlines(); #已用過的號碼的列表
while j < 10000: #生成一萬個同前綴號碼
newNum = str( int(txtNum)*10000+j );
j += 1;
# print newNum;
if not newNum in bugTxtArr: #如果不在已用過的號碼列表裡
numArr.append( '+86'+newNum );
print '+86'+newNum;
我在本機大概運行了一下,觀察了幾分鐘,似乎線程創建得比較慢,有些已經跑到了十幾個了,有的才剛創建線程。線程調度嘛,不按照順序嘛,除了輸出很亂以外,似乎也沒有什麼其它問題。於是就上傳到服務器上去跑了,然後再過了一會就下班回家了。第二天回到公司,連上服務器看看,出乎意料啊,看到輸出的信息裡面,那些線程才跑到 三百多,天吶什麼時候才能跑到一萬啊。而且還有坑爹的是,偶爾就看到有些線程創建失敗啊⊙o⊙
從前面的運行信息來看,這裡使用多線程似乎並沒有加快程序的運行啊,這是為什麼呢?如果不能用多線程,那麼生成比對的地方就要改成另外更高效的方式了,有嗎?第一問,從網上找到答案,硬實說在計算密集型程序中,多線程比單線程更糟,因為一個CPU就那麼幾個核,不同的線程還是一樣要占用CPU資源,再加上線程調度的時間和空間,真是天坑。第二問,PHP中有從一個數組去除另一個數組的函數(官方說叫做數組的差集 array_diff() ),那麼python應該也會有這樣的函數,先成一萬個號碼的數組再進行差集 會不會比原來 每個號碼對比再合並效率快呢?
實踐了一下,證明確實效率高了極多極多,python中的數組差集是這個樣子的 numArr = list( set(numArr) - set(bugTxtArr) ); 測了一下,大概三秒完成一批號碼(一批約等於一萬個號碼),之前是半秒一個號碼\( ^▽^ )/。
期間調試的時候發現,使用多線程有時會報錯 Unhandled exception in thread started by sys.excepthook is missing 之類的,網上查資料說是因為主進程已經執行完畢,那麼其創建的線程就會被關掉。所以我的做法就是讓主進程最後為一直執行空語句,很像當年用C語言做單片機的做法呢→_→
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import thread
from time import sleep
#生成號碼的函數,傳入號碼前綴
def generate(txtNum):
# print txtNum;
numArr = []; #用來存號碼數組的
numArrStr = ''; #用來寫入文件的
global doneNum;
global bugTxtArr;
global totalNum;
global tblIndex;
j = 0;
while j < 10000: #生成一萬個同前綴號碼
newNum = str( int(txtNum)*10000+j );
j += 1;
# print newNum;
numArr.append( newNum );
#每個對比,但是非常耗時間
# if not newNum in bugTxtArr: #如果不在已用過的號碼列表裡
# numArr.append( '+86'+newNum );
# #print '+86'+newNum;
# 先全部合並,再數組去除(list 差集運算)
# numArr = list( set(numArr).difference(set(bugTxtArr)) );
numArr = list( set(numArr) - set(bugTxtArr) );
numArrStr = '\n'.join(numArr);
#存入文件
# newFileObj = open('cellNum'+str(tblIndex)+'/'+str(txtNum)+'.txt', "wb");
# newFileObj.write( numArrStr );
# newFileObj.close();
print '-----TASK--------'+str(txtNum)+'--OK-------------';
doneNum += 1; #完成的任務數加一
if doneNum == totalNum:
print '++++++---ALL---TASK---DONE---+++++++++++++++'; #完成所有任務
#########################################函數結束#####################################
#定義要處理的表
tblIndex = 0;
#把一個表合並後的數據讀出來
fileobj = open('exel-dataAll'+str(tblIndex)+'.txt');
txtStr = fileobj.read();
fileobj.close();
txtArr = txtStr.splitlines(); #分割成數組
totalNum = len( txtArr );
#print txtArr;
#這裡是重復的號碼
#fileobj = open('testBugNum.txt'); #測試的
fileobj = open('list-dataAll.txt'); #實際的
bugTxtStr = fileobj.read();
fileobj.close();
bugTxtArr = bugTxtStr.splitlines(); #已用過的號碼的列表
#print bugTxtArr;
print totalNum;
doneNum = 0;
num = 0;
for txtNum in txtArr:
# generate(txtNum); #生成號碼
#多線程,有多少個前綴就多少個線程,每個線程生成一萬個號碼
#測試發現執行效率沒有提高,而內存消耗大很多,查資料了解到計算密集型任務用多線程沒幫助的
try:
thread.start_new_thread( generate, (txtNum,) )
except:
print "Error: "+str(txtNum)+" no Thread";
errfileobj = open('error-log'+str(tblIndex)+'.txt', 'a');
errfileobj.write( "Error: "+str(txtNum)+" no Thread\n" );
errfileobj.close();
# num += 1;
# if num > 10:
# break;
#sleep(1);
#print 'sleep end';
#while 1==1 : #主程序一直執行,以防線程提早結束
# pass;
doData.py
最後就是把一個Excel表生成的八千多個文件整理,每十個文件合成一個,每個文件約十萬個號碼,每個號碼前面加上 “+86” 。就遍歷一下目錄,沒什麼技術點就不詳說了。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
def hebing( filesArr ):
global tblIndex;
i = 0;
newStr = '';
filesArrLen = len(filesArr);
#print filesArr;
for file in filesArr:
txtStrAll = '';
fileobj = open('cellNum'+str(tblIndex)+'/'+filesArr[i]);
txtStr = fileobj.read();
fileobj.close();
txtStrAll += txtStr+'\n';
txtArr = txtStrAll.splitlines(); #分割成數組
#全部在開頭加上+86
arrLen = len(txtArr);
#print arrLen;
for j in range(0, arrLen):
txtArr[j] = "+86"+txtArr[j];
#轉成字符串
newStr += '\n'.join(txtArr);
i += 1;
#每10個文件寫入txt,注意最後的不足十個的時候
if not i%10 :
#print i;
newFileObj = open('resList'+str(tblIndex)+'/'+str(i)+'.txt', "wb");
newFileObj.write( newStr );
newFileObj.close();
newStr = '';
elif i==filesArrLen :
#print i;
newFileObj = open('resList'+str(tblIndex)+'/'+str(i)+'.txt', "wb");
newFileObj.write( newStr );
newFileObj.close();
newStr = '';
#把所有的文本都讀出來
tblIndex = 1;
rootDir = "F:\cellphone\cellNum"+str(tblIndex);
#print rootDir;
for parent,dirs,files in os.walk(rootDir):
# print files; #得到一個文件名List,按文件名排序的
# hebing( files[0:15] ); #測試
hebing( files );
hbData.py
後話,總共只有十三個表,這些程序稍微改一下,執行十三次就行了。值得注意的是,我這裡的程序幾乎每個都有一個全局變量 tblIndex, 是以防一文件裡面一個個修改目錄名和文件名,疏忽有可能導致的數據覆蓋。