In fact, the birth of artificial intelligence is more difficult to find,大數據時代的來臨,Greatly accelerated the application of artificial intelligence.
4:1 李世石慘敗
隨著數據規模的增加,The bottleneck of traditional artificial intelligence algorithm will appear,At this point, deep learning algorithms should be selected.
These subtitles are written by a deep learning program

Content + Style = Interesting thing

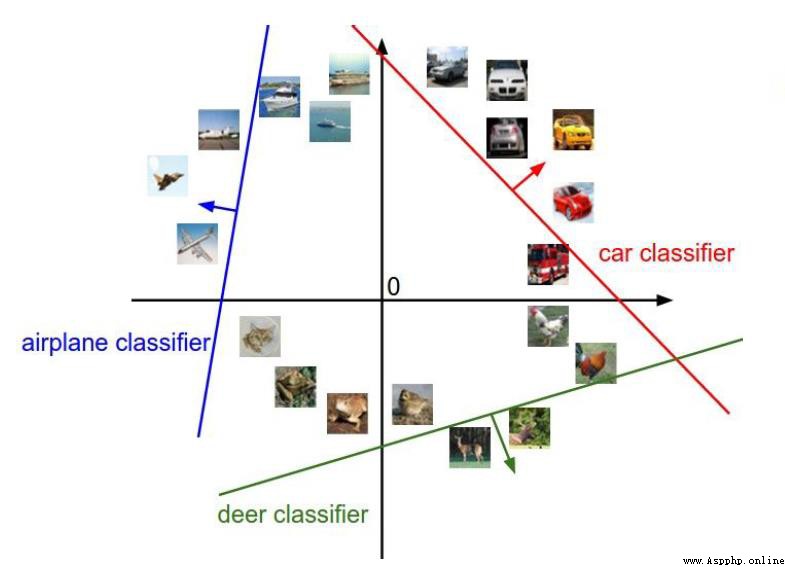
圖像分類是計算機視覺的核心任務.
Suppose we have a series of tags:狗,貓,汽車,飛機...
How can we tell if the picture below is a cat??
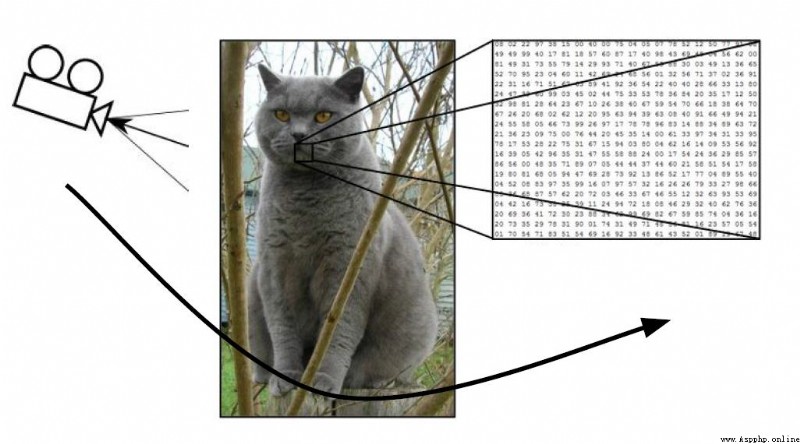
一張圖片被表示成三維數組的形式,每個像素的值從0到255
例如:3001003
(最後的3代表顏色 RGB. R代表red,G代表Green,B代表Black)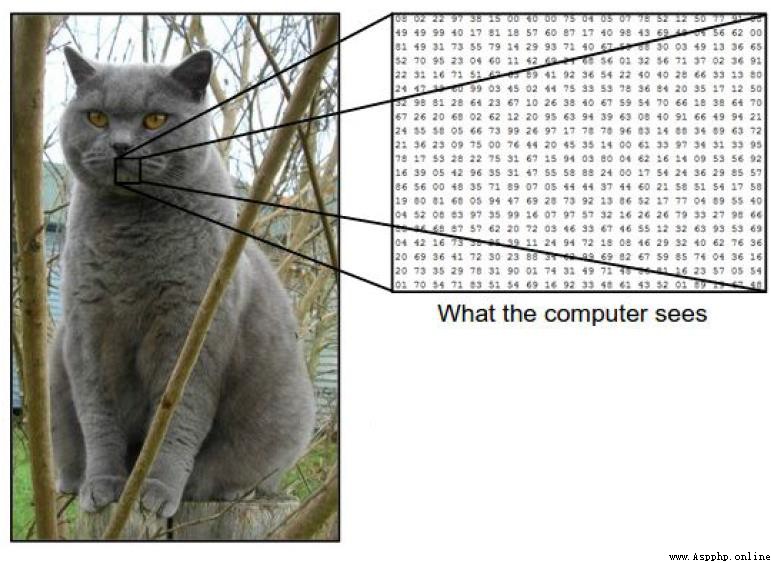
There are many distractions in computer vision.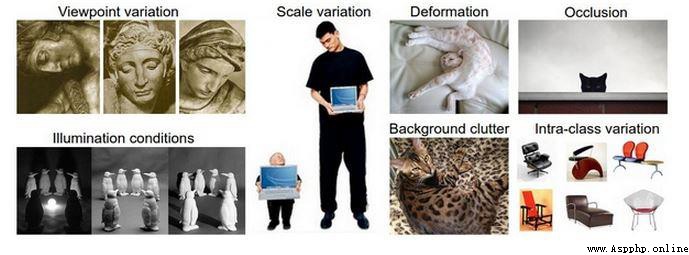



Background mixing is the most troublesome situation at present

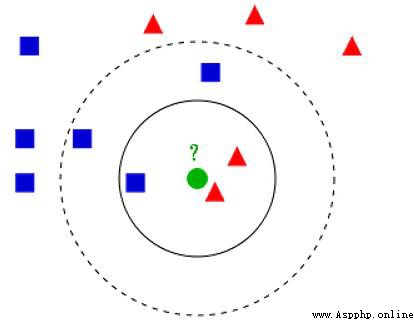

對於未知類別屬性數據集中的點:
概述:
KNN 算法本身簡單有效,它是一種lazy-learning 算法.
分類器不需要使用訓練集進行訓練,訓練時間復雜度為0.
KNN 分類的計算復雜度和訓練集中的文檔數目成正比,也就是說,如果訓練集中文檔總數為n,那麼KNN 的分類時間復雜度為O(n).
距離度量和分類決策規則是該算法的三個基本要素
問題:
該算法在分類時有個主要的不足是,當樣本不平衡時,如一個類的樣本容量很大,而其他類樣本容量很小時,有可能導致當輸入一個新樣本時,該樣本的K 個鄰居中大容量類的樣本占多數
解決:
不同的樣本給予不同權重項
10類標簽
50000個訓練數據
10000個測試數據
大小均為32*32
測試結果:
准確率較低

問題:
交叉驗證: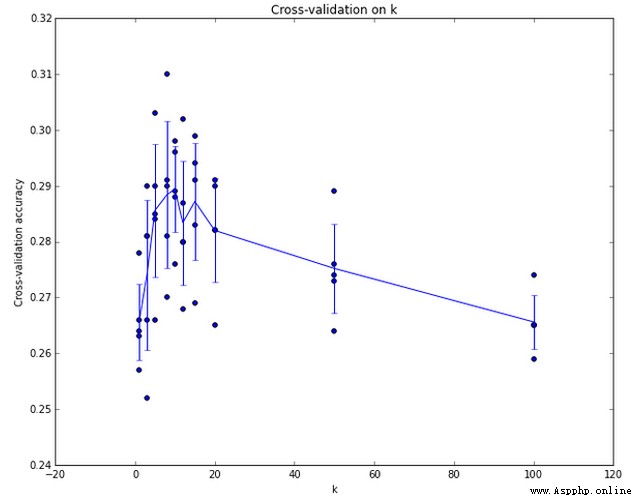
The right way to pick hyperparameters:
The right way to pick hyperparameters是:將原始訓練集分為訓練集和驗證集,我們在驗證集上嘗試不同的超參數,最後保留表現最好那個.
如果訓練數據量不夠,使用交叉驗證方法,它能幫助我們在選取最優超參數的時候減少噪音.
一旦找到最優的超參數,就讓算法以該參數在測試集跑且只跑一次,並根據測試結果評價算法.
最近鄰分類器能夠在CIFAR-10上得到將近40%的准確率.該算法簡單易實現,但需要存儲所有訓練數據,並且在測試的時候過於耗費計算能力.
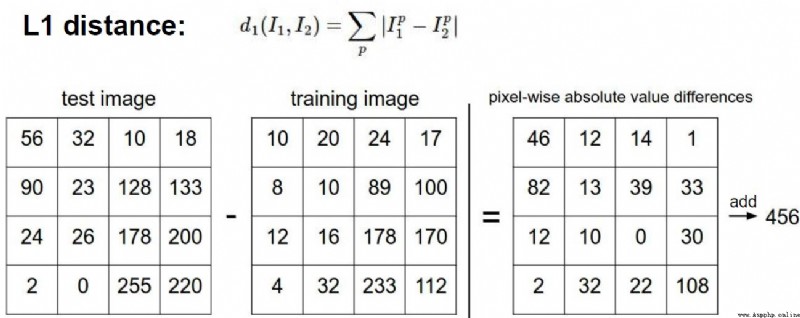
最後,我們知道了僅僅使用L1和L2范數來進行像素比較是不夠的,圖像更多的是按照背景和顏色被分類,而不是語義主體分身.
整體步驟:
預處理你的數據:對你數據中的特征進行歸一化(normalize),讓其具有零平均值(zero mean)和單位方差(unit variance).
如果數據是高維數據,考慮使用降維方法,比如PCA.
將數據隨機分入訓練集和驗證集.按照一般規律,70%-90% 數據作為訓練集.
在驗證集上調優,嘗試足夠多的k值,嘗試L1和L2兩種范數計算方式.
Score for each category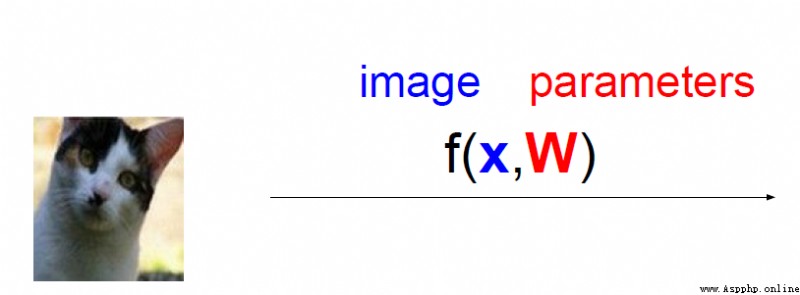
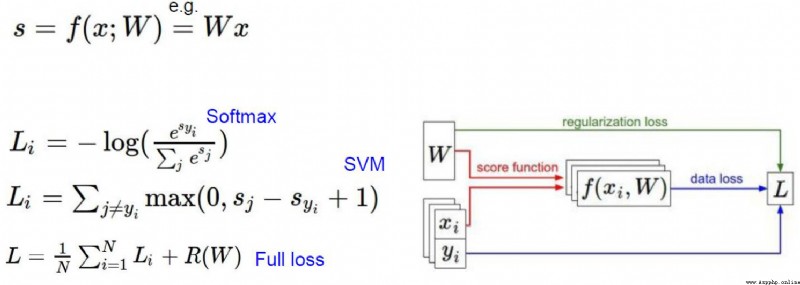
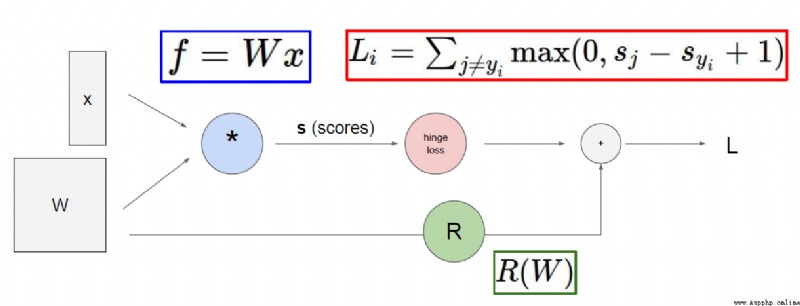
得分函數: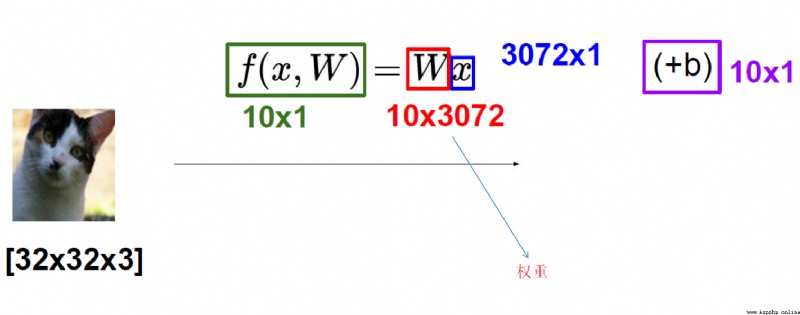
實例:
0.256 - 0.5231 + 0.124 + 2.02 + 1.1 = -96.8
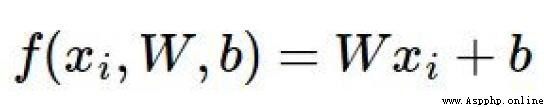

從上例可以看到,The final score is not ideal,There is a large difference between the predicted value and the actual value,This introduces a loss function.
從上圖可以看出,The worse the model evaluation is, the worse,The larger the value of the loss function is.

損失函數: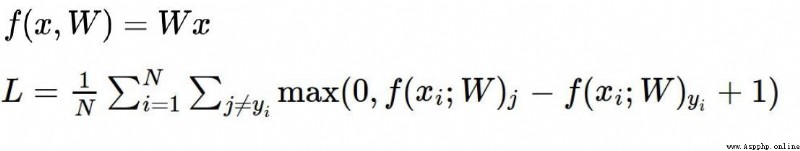
According to the loss function of the above figure,結合下圖的x , w1, w2
會出現 f(x,w1) = f(x,w2)
但是w1Just set the weight value for a variable,而w2weights are set for all variables,Although the score is the same model,But theoretically adding more variables to the model is a better approach.
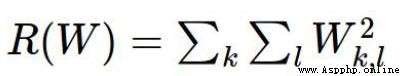
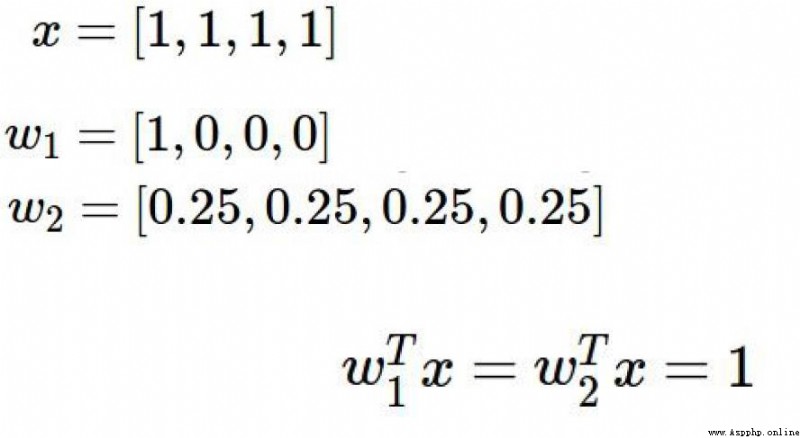
為了解決上面提出的問題,So the regularization penalty term is introduced
understandable understanding λ 就是 w 2 w^2 w2
y(x,w1) = 11 = 1
y(x,w2) = 0.250.25 + 0.250.25 + 0.250.25 + 0.25*0.25 = 0.25
此時y(x,w2) The loss function is less thany(x,w1),解決了上面的問題.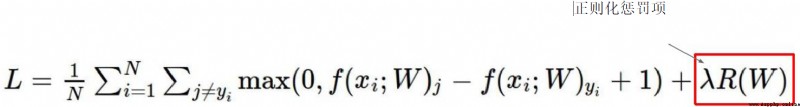
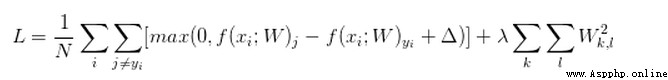
Softmax 分類器 是 多類別分類,SoftmaxThe output is the probability.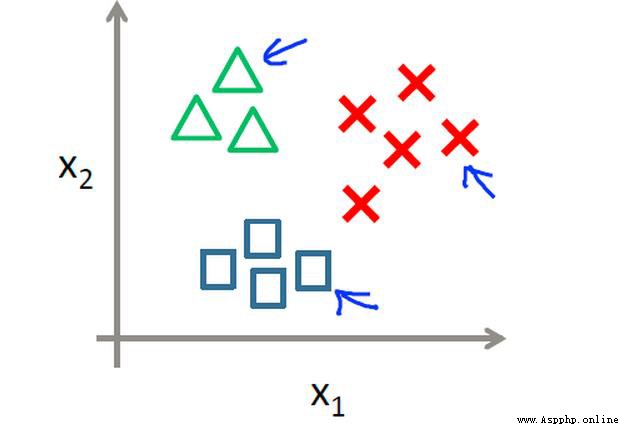
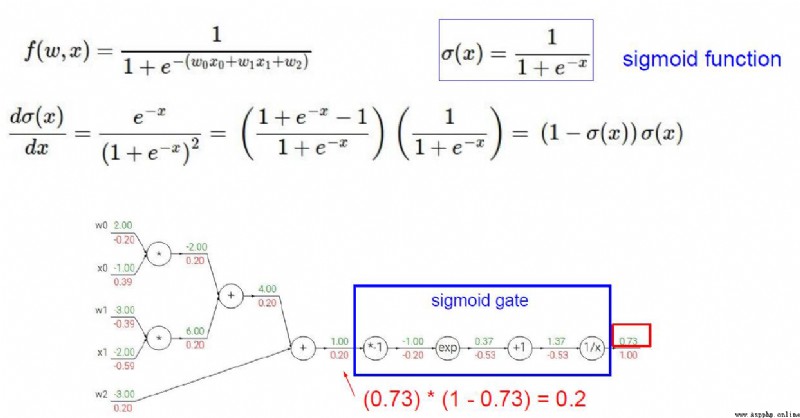
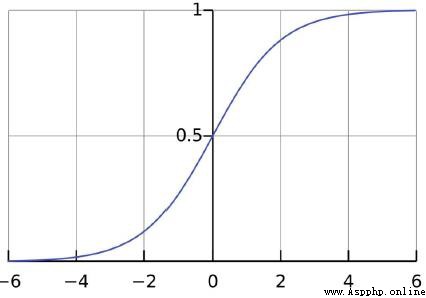
Sigmoid是符號函數: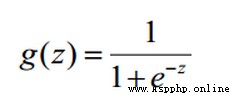
x取值范圍是(-∞,+∞),而y的取值范圍是[0-1]
Just our probability values range too[0-1],So it can be matched.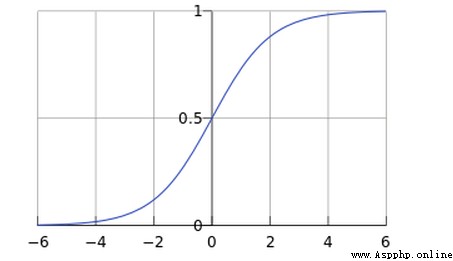
Softmax的輸出(歸一化的分類概率)
損失函數:交叉熵損失(cross-entropy loss)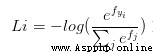
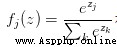
The picture above is calledsoftmax函數
其輸入值是一個向量,向量中元素為任意實數的評分值
輸出一個向量,其中每個元素值在0到1之間,且所有元素之和為1
Rough idea:
得到的結果:

The first position is random,then iterates,找到最低點
跟隨梯度:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-IYJswv5W-1659234249640)(https://upload-images.jianshu.io/upload_images/2638478-2962a7e9f53e5658.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)]


Bachsize通常是2的整數倍(32,64,128)
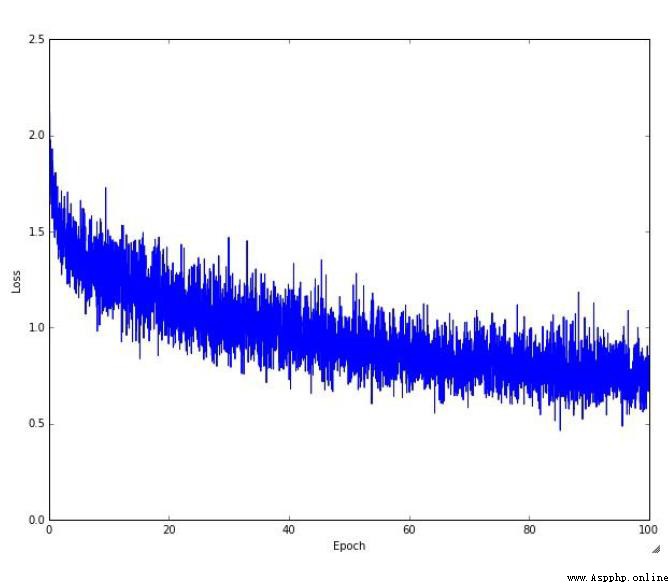
上圖是 while training the networkLOSSValue the visualization results.
while training the networkLOSSValue the visualization results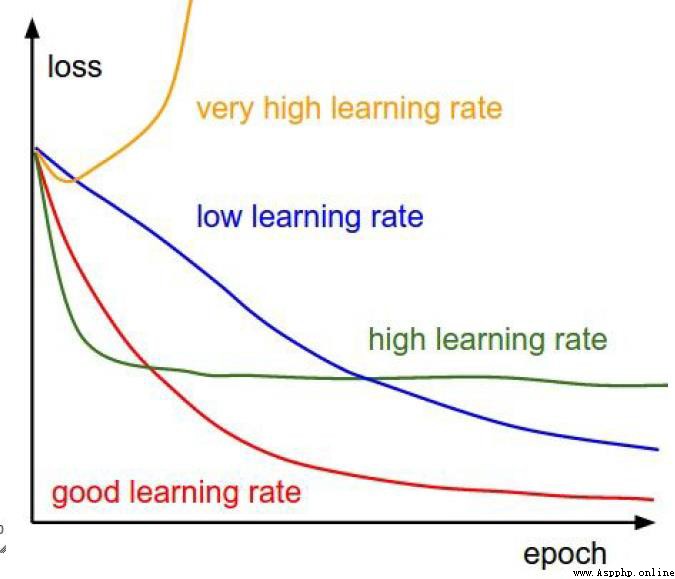

The result of the function run is biased from the validation set(損失函數大),At this point, the feedback results can be,Adjust weight parameters,盡可能的將 The value of the loss function becomes smaller.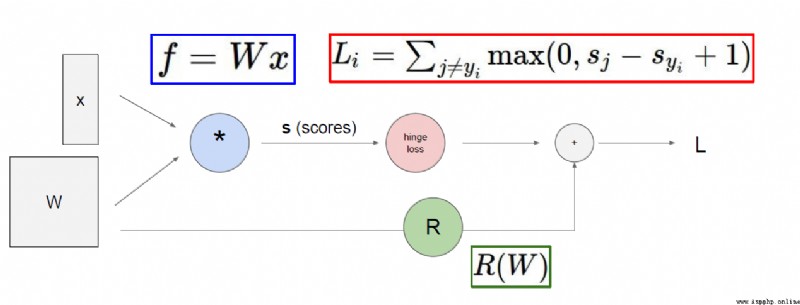
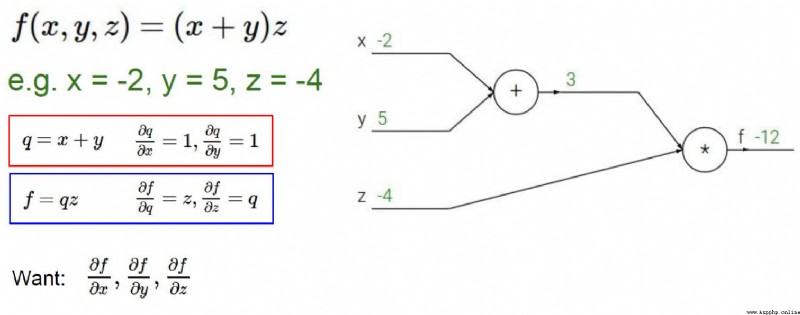
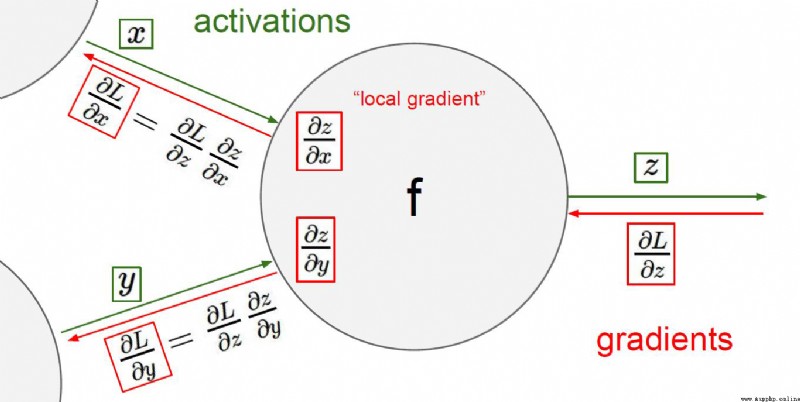
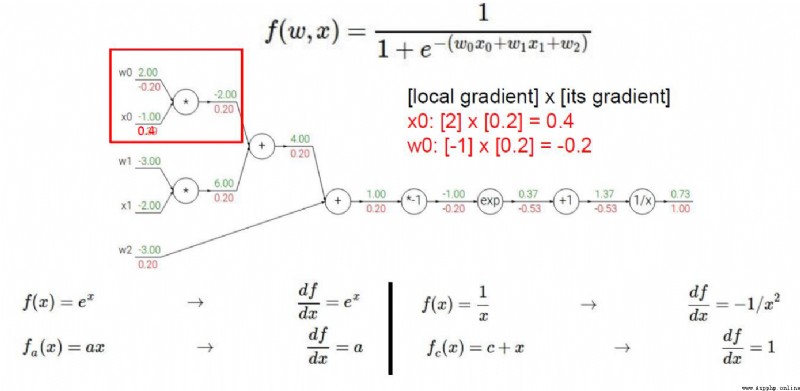
加法門單元:均等分配
MAX門單元:給最大的
乘法門單元:互換的感覺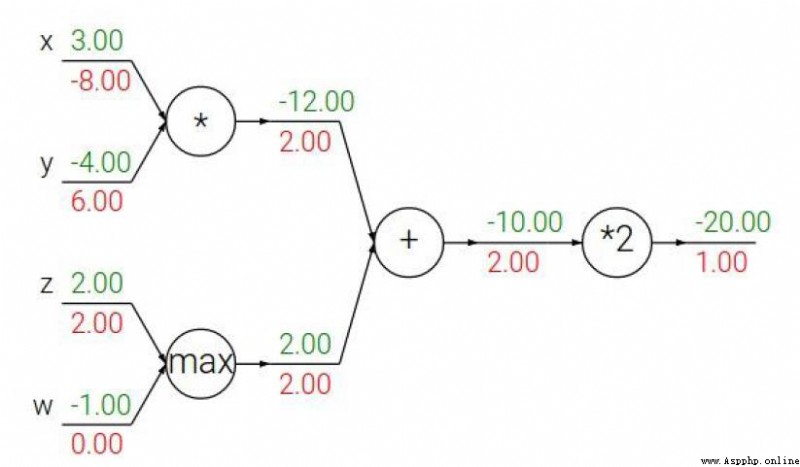
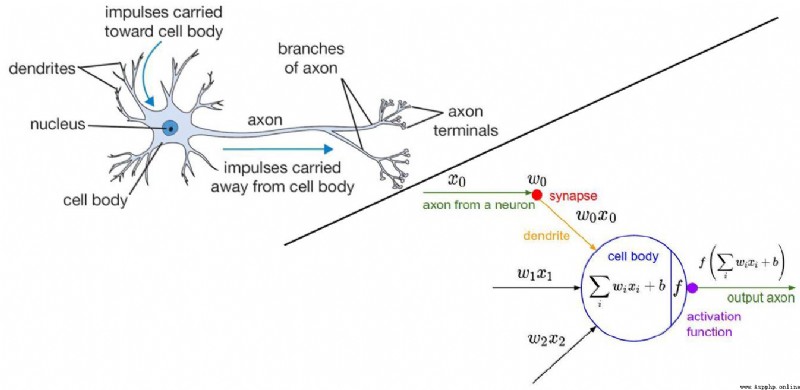
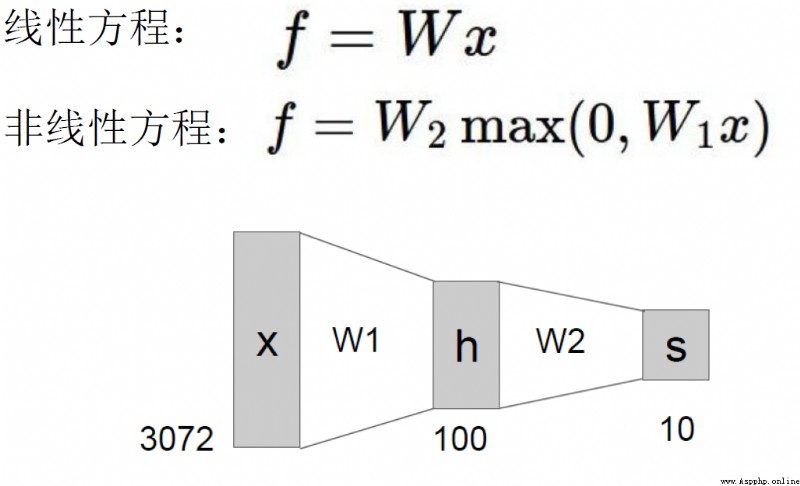
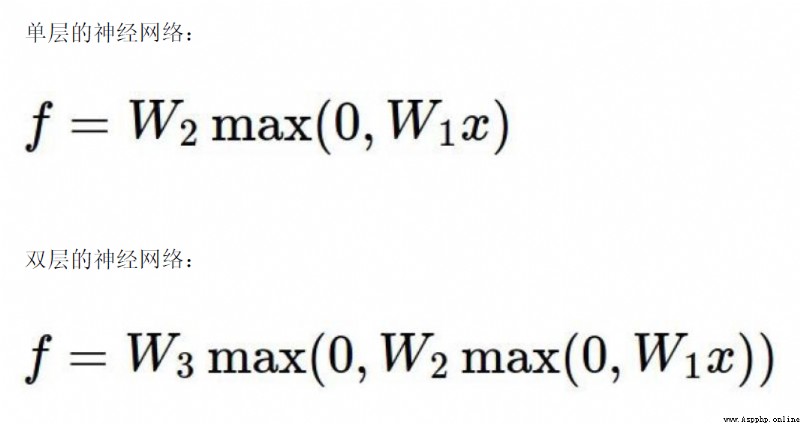
The important role of regularization term in neural network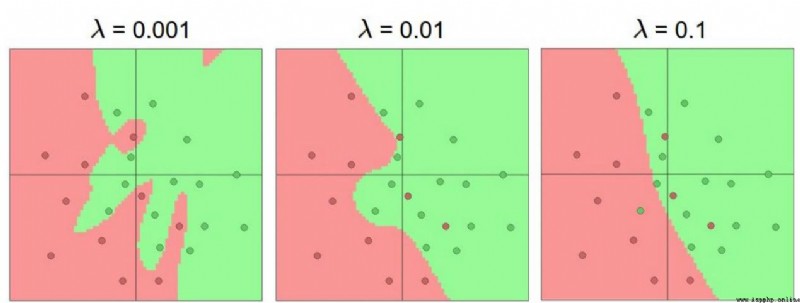
The more neurons,The more able to express complex models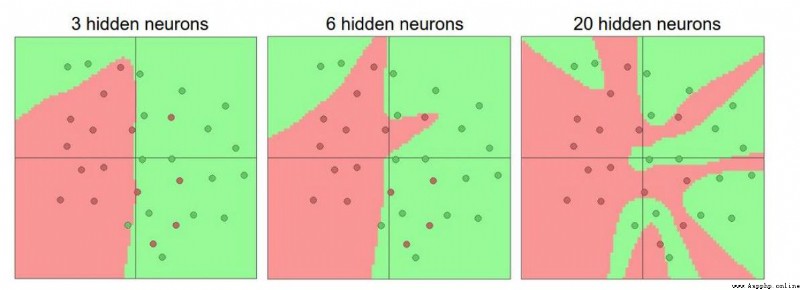
The activation function is used to solve Problems with non-linear relationships between predicted outcomes and variables.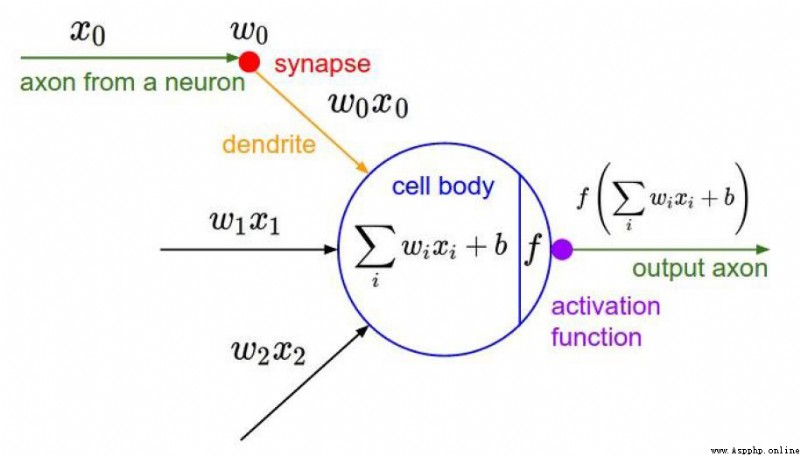
The initial activation function isSigmoid,But he will have a problem of gradient disappearance.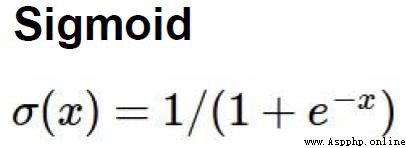
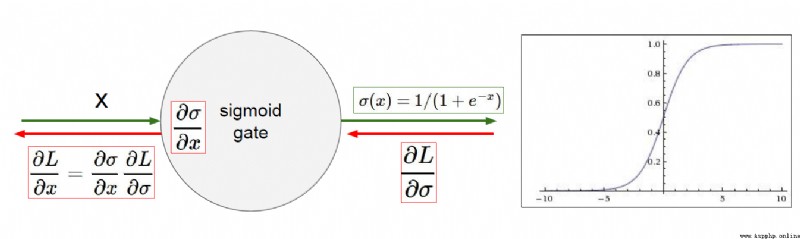
So a new activation function is introducedReLUctant
當x<=0的時候,y=0
當x > 0 的時候,y=x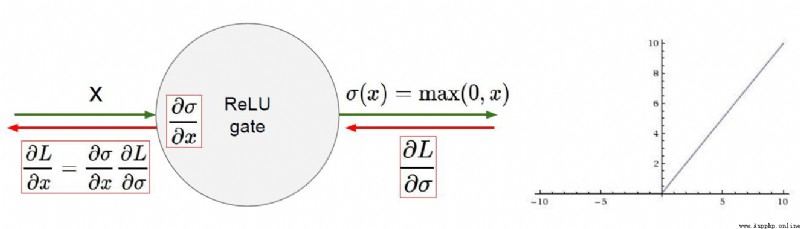
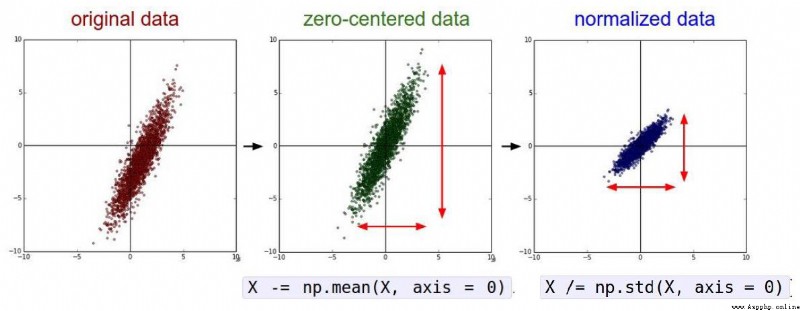
All-zero value initialization?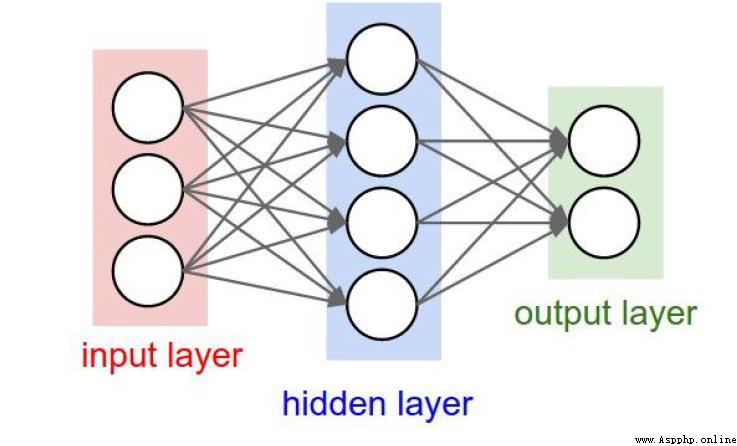

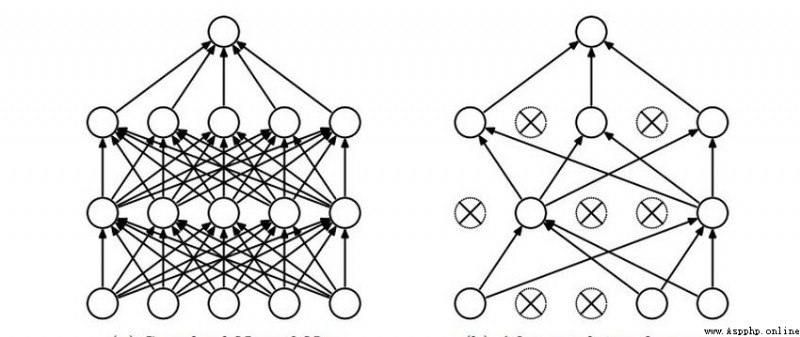
The picture on the left is fully connected,模型效果更優,But the model is also more complex,計算量也大.
So there is the picture on the rightDROP-OUT,Remove some unimportant connections,While ensuring the model effect,Minimize unnecessary computation.