PHP作為一門簡單而強大的語言,能夠提供很多Web適用的語言特性。從實踐出發,繼弱類型變量原理探究後,本文繼續帶領大家深入理解php內核。
最近,和一個網友交流的時候,給我提了一個非常奇怪的問題。那就是,在一個運算中,加了一個引用之後,發現性能慢了一萬倍。在我的腦海裡面,引用是一個非常容易出錯的問題,特別是PHP裡面的引用,有非常多的陷阱。因為,以前專門研究過這一塊PHP的源代碼,所以,我可以比較清晰的解析引用到底是怎麼一回事,希望,讀了我這篇文章,能徹底理解這個問題。如果,有任何疑問,或者有一些你想了解的問題,可以給我留言。
先來看一段代碼:
class RefferTest
{
private $data;
private $testKey;
function __construct()
{
$key = "hello";
$this->data[$key] = range(0, 10000);
$this->testKey = $key;
}
function reffer($key)
{
$reffer = &$this->data[$key];
return count($reffer);
}
function noreffer($key)
{
return count($this->data[$key]);
}
function test()
{
$t1 = microtime(true);
for ($i = 0; $i < 5000; $i++)
{
$this->reffer($this->testKey);
}
$t2 = microtime(true) - $t1;
var_dump("reffer: " . round($t2, 4));
$t1 = microtime(true);
for ($i = 0; $i < 5000; $i++)
{
$this->noreffer($this->testKey);
}
$t2 = microtime(true) - $t1;
var_dump("noreffer: " . round($t2, 4));
}
}
$test = new RefferTest();
$test->test();
如果你完這個代碼,能說出,為了reffer 和 noreffer會差一萬倍的性能,那下面的也就沒有必要往下看了。這篇博客針對的是,PHP的新手。你可以運行一下這個代碼試試看,的確差了一萬倍。當然,那個網友遇到的問題的代碼要比上面的復雜,上面的代碼是我為了說明問題,特意簡化的。或許你已經從代碼裡面看出問題了,但是,至於為什麼會這樣。我想,還是有必要分析一下。這樣,以後,在使用PHP的時候,才不會犯相同的錯誤。
PHP為了減少復制,采用了一種copy on writer的機制。我想,這是一種非常常見的機制,你也一定聽說過。比如,gcc 的 stl string 的實現,就是采用這樣的機制,字符串賦值,不是真正的復制,而且,在修改的時候才會進行復制。我們先來舉個最簡單的例子:
$a = str_repeat("", );
$b = $a;
$a[] = "";
$a 是一個非常大的字符串,如果 $b = $a 的時候,進行復制,那要耗費很多內存 和 cpu,這樣非常的不劃算,萬一,下面的代碼並不修改$a 和 $b 那復制根本沒有必要。當然,$a 在後面又被修改了,這個時候,必須進行復制了,否則就不符合邏輯了。但是,現在問題來了,怎麼知道,$a 在修改的時候,要進行復制呢,必須要有這樣一個標記。方法就是采用引用計數。引用計數還被用來進行內存的管理。
基本的流程是這樣的:
1: 創建一個變量,可以保存 10000 個 0 的這樣一個字符串。
2: 創建一個變量符號 a ,這個變量符號引用 這個變量。注意,變量符號 和 變量不是一回事情,這兩者是分離的。
如果從C語言的角度來說,PHP大概完成這樣一件事情:
char *varname = "a"; size_t varname_len = strlen(varname); zend_hash_add(EG(active_symbol_table), varname, varname_len + , &var, sizeof(zval*), NULL);
active_symbol_table 是PHP的一個符號表,所有能訪問到的變量都在這個裡面,他是一個哈希表。var 這個變量,保存了 10000 個 0 這個字符串。而且是zval的結構,zval的結構如下:
typedef struct _zval_struct {
zvalue_value value;
zend_uint refcount;
zend_uchar type;
zend_uchar is_ref;
} zval;
typedef union _zvalue_value {
long lval;
double dval;
struct {
char *val;
int len;
} str;
HashTable *ht;
zend_object_value obj;
} zvalue_value;
zvalue_value 是一個聯合,可以保存 long, double, 字符串,哈希表(PHP Array),還有就是 對象。也就是所有的PHP的類型。 zval 其實 就是 對 zvalue_value ,加入了類型type 和 引用is_ref,引用計數refcount三個功能。這就是PHP中的普通變量。要是用PHP做比較大型的東西,就會發現,內存占用非常厲害。就是因為,他一個變量 不是 傳統C語言的那個變量了,它加了很多東西。
好了,第一句完成了,下面是第二句。第二句很簡單,會產生一個新的變量符號b,把他加入 active_symbol_table ,但是不會增加新的一個變量,而只是,refcount++。賦值就完成了。如圖:

首先我們要注意的是,a ,b 只是一個符號,他是active_symbol_table 表裡面的一個key,都有一個指針指向一個zval,所以,a 和b 在 C語言層面上是完全一致的。我們就得出PHP變量第一定律:
PHP變量第一定律:如果兩個變量指向同一個zval,那麼這兩個變量是無差別的。也就是說,任何對a 的操作 相對b 都是對稱的。這裡的對稱,是這樣理解的。就是鏡子中的你,而不是等同。比如,對 a 進行 賦值,a 就會產生 copy。同樣的,如果對b進行賦值,也會進行相同的操作,那就是b產生一個copy。也就是說,a 和b的行為是一樣的。
第三句,當writer發生的時候,PHP會判斷一下refcount 是否大於2,如果大於2,那麼就復制一下zval,然後,把原來那個zval refcount--。這就是copy on writer 的全部了,你一定覺得,這一切你都是非常的熟悉,你都懂。
但是,PHP不僅僅是copy on writer 這樣簡單,它還有一個引用的問題。引入引用的概念,這樣,問題就變的有些復雜了。因為,引用這個標記,意思就是說,writer 的時候,你也不需要復制。這樣,會修改原來的那個變量。從我們在學校裡面以前經常學習的哲學上來說,這是一對矛盾。他們是對立的,又是統一的,各有各的用處。所謂,存在的就是合理的。
好,下面我們來看看這對矛盾,我們只考慮兩種組合的情況。多種組合都是類似的。兩種組合的話,就是賦值在前,引用在後。
或者 引用在前,賦值在後。我們會分別討論,先來看:就是賦值在前,引用在後的情況。
$a = ; $b = $a; $c = &$a;
$b = $a, 是copy on writer 行為的 賦值。而 $c 和 $a 是引用賦值。我們假設在上面這樣的情況下,我們可以用一個zval表示,也就是不需要復制,那麼情況是這樣的:
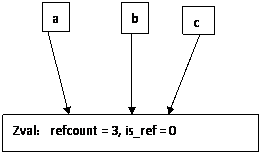
根據我們的PHP變量第一定律,那,就是說,a,b,c的操作是對稱的,但是非常明顯,對 b 操作要產生復制行為,而對a操作不會產生復制,操作行為不相同,和第一定律矛盾。也就是說,要使得上面的操作沒有矛盾,必須,進行分離。分離的原則就是,誰制造矛盾,誰復制。顯然是 第三句話,$c = &$a; 在制造矛盾。所以,內部變量的復制過程如下圖:
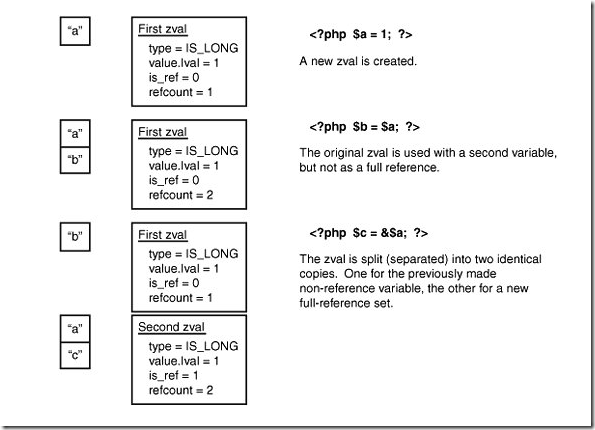
上面情況是賦值在前,引用在後的情況。還有一種情況是,引用在前賦值在後:
$a = ; $b = &$a; $c = $a;
按照PHP變量的第一定律,a,b,c 必須進行分離,才能保證定律的正確。可以發現,b 和 a 明顯是一伙人,就是說,b 和 a 的操作是對稱的,他們可以指向同一個zval ,而c 的行為和 a,b 不一樣,改變c 需要進行復制。看到這裡,我想,如果你看懂了的話,為什麼剛開始,貼出來的那段代碼的,那個兩個count差異如此之大,你也應該明白了。當我和那個網友討論的時候,它最後說,那這樣的話,PHP設計的不好,我完全可以,$c先不進行復制,等c被write 了,再進行復制。看來要說懂一個東西,還是一件很難的事情,好好想想那個PHP第一定律吧。你可以假設不進行分離,c指向同一個zval,所以,c 和 a,b的行為是一樣的,是is_ref = 1,所以,c 不會進行復制。最後一種內部執行情況可以用下圖表示:

我以前也進行搞混這個引用,現在,你可以用那個第一定律來分析所有的情況了。PHP內核分析的文章,以後我還會寫一些,如果你想深入了解PHP的某些方面,可以給我留言。
最後再補充一點,也是一個隱性的錯誤。
function count_bigarray()
{
global $bigarray;
return count($bigarray);
}
這裡,沒有顯示的引用,但是這裡隱藏了一個引用。PHP會自動創建一個引用全局變量 $bigarray 的代碼,如果你在這裡使用count,那麼這個效率會非常的慢。最好直接通過$GLOBAL 數組進行引用。
下面文章將給大家介紹深入理解php內核二之SAPI探究,希望大家繼續關注哦。