Access應用宏掌握法式。本站提示廣大學習愛好者:(Access應用宏掌握法式)文章只能為提供參考,不一定能成為您想要的結果。以下是Access應用宏掌握法式正文
在一個(差)的PostgreSQL 查詢中只需一個小小到修改(ANY(ARRAY[...])to ANY(VALUES(...)))就可以把查詢時光從20s縮減到0.2s。從最簡略的進修應用 EXPLAIN ANALYZE開端,到進修應用 Postgres community 年夜量進修時光的投入將有百倍時光到報答。
應用Postgres監測慢的Postgres查詢
在這周早些時刻,一個用於我們的圖形編纂器上的小表(10GB,1500萬行)的主鍵查詢,在我們的一個(多個)數據庫上產生來年夜的查詢機能成績。
99.9%到查詢都長短常敏捷流利的,然則在一些應用年夜量的列舉值的處所,這些查詢會須要20秒。消費如斯多到時光在數據庫上,意味著應用者必需在閱讀器眼前期待圖形編纂器的呼應。很顯著只由於這0.01%就會形成很欠好到影響。
查詢和查詢籌劃
上面是這個出成績的查詢
SELECT c.key,
c.x_key,
c.tags,
x.name
FROM context c
JOIN x
ON c.x_key = x.key
WHERE c.key = ANY (ARRAY[15368196, -- 11,000 other keys --)])
AND c.x_key = 1
AND c.tags @> ARRAY[E'blah'];
表X有幾千行數據,表C有1500萬條數據。兩張表的主鍵值“key”都有恰當的索引。這是一個異常簡略清楚的主鍵查詢。但風趣的是,當增長主鍵內容的數目,如在主鍵有11,000個值的時刻,經由過程在查詢語句上加上 EXPLAIN (ANALYZE, BUFFERS)我們獲得以下的查詢籌劃。
Nested Loop (cost=6923.33..11770.59 rows=1 width=362) (actual time=17128.188..22109.283 rows=10858 loops=1)
Buffers: shared hit=83494
-> Bitmap Heap Scan on context c (cost=6923.33..11762.31 rows=1 width=329) (actual time=17128.121..22031.783 rows=10858 loops=1)
Recheck Cond: ((tags @> '{blah}'::text[]) AND (x_key = 1))
Filter: (key = ANY ('{15368196,(a lot more keys here)}'::integer[]))
Buffers: shared hit=50919
-> BitmapAnd (cost=6923.33..6923.33 rows=269 width=0) (actual time=132.910..132.910 rows=0 loops=1)
Buffers: shared hit=1342
-> Bitmap Index Scan on context_tags_idx (cost=0.00..1149.61 rows=15891 width=0) (actual time=64.614..64.614 rows=264777 loops=1)
Index Cond: (tags @> '{blah}'::text[])
Buffers: shared hit=401
-> Bitmap Index Scan on context_x_id_source_type_id_idx (cost=0.00..5773.47 rows=268667 width=0) (actual time=54.648..54.648 rows=267659 loops=1)
Index Cond: (x_id = 1)
Buffers: shared hit=941
-> Index Scan using x_pkey on x (cost=0.00..8.27 rows=1 width=37) (actual time=0.003..0.004 rows=1 loops=10858)
Index Cond: (x.key = 1)
Buffers: shared hit=32575
Total runtime: 22117.417 ms
在成果的最底部你可以看到,這個查詢總共消費22秒。我們可以異常直不雅的經由過程上面的CPU應用率圖不雅察到這22秒的消費。年夜部門的時光消費在 Postgres和 OS 上, 只要很少部門用於I/O . 
在最低的層面,這些查詢看起來就像是這些CPU應用率的峰值。CPU圖很少有效,然則在這類前提下它證明了症結的一點:數據庫並沒有期待磁盤去讀取數據。它在做一些排序,哈希和行比擬之類的工作。
第二個風趣的器量,就是間隔這些峰值很近的軌跡,它們是由Postgres“獲得”的行數(本例中沒有前往,就看看再疏忽失落吧)。 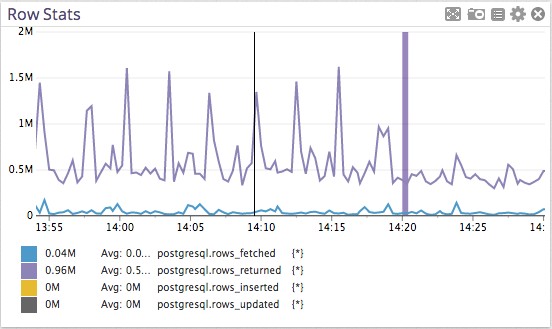
明顯有些舉措在規矩的有條不紊的閱讀過很多行:我們的查詢。
Postgres 的成績地點:位圖掃描
上面是行婚配的查詢籌劃
Buffers: shared hit=83494
-> Bitmap Heap Scan on context c (cost=6923.33..11762.31 rows=1 width=329) (actual time=17128.121..22031.783 rows=10858 loops=1)
Recheck Cond: ((tags @> '{blah}'::text[]) AND (x_key = 1))
Filter: (key = ANY ('{15368196,(a lot more keys here)}'::integer[]))
Buffers: shared hit=50919
Postgres 應用位圖掃描表C. 當主鍵的數據量小的時刻,它能有用的應用索引在內存裡樹立位圖。假如位圖太年夜,最優查詢籌劃就轉變查詢方法了。在我們這個查詢中,由於主鍵包括的數據量很年夜,所以查詢就應用最優(體系本身斷定的)的方法去檢索查詢候選行,而且立刻查詢一切和主鍵婚配的數據。就是這些¨放入內存¨和¨立刻查詢¨消費太多的時光(查詢籌劃中的Recheck Cond)。
幸虧只要30%的數據被導入到內存中,所以還不至於像從硬盤裡讀取那末壞。但它依然對機能有異常顯著的影響。記住,查詢長短常簡略的。這是一個主鍵查詢所以沒有許多清楚明了的方法來肯定它有無戲劇性的從新架構數據庫或運用法式。PGSQL-Performance mailing list賜與了我們很年夜的贊助.
處理計劃
這是我們愛好開源和愛好贊助用戶的別的一個緣由。Tom Lane是開源代碼作者中最盛產的法式員之一,他建議我們做以下測驗考試:
SELECT c.key,
c.x_key,
c.tags,
x.name
FROM context c
JOIN x
ON c.x_key = x.key
WHERE c.key = ANY (VALUES (15368196), -- 11,000 other keys --)
AND c.x_key = 1
AND c.tags @> ARRAY[E'blah'];
把ARRAY改成VALUES,你能指出他們的分歧點嗎?
我們應用ARRAY[...]羅列出一切的症結字以用來查詢,然則這卻誘騙了查詢優化器。但是Values(...)卻可以或許讓優化器充足應用症結字索引。僅僅是一行代碼的轉變,而且沒有發生任何語義的轉變。
上面是新查詢語句的寫法,差異就在於第三和第十四行。
Nested Loop (cost=168.22..2116.29 rows=148 width=362) (actual time=22.134..256.531 rows=10858 loops=1)
Buffers: shared hit=44967
-> Index Scan using x_pkey on x (cost=0.00..8.27 rows=1 width=37) (actual time=0.071..0.073 rows=1 loops=1)
Index Cond: (id = 1)
Buffers: shared hit=4
-> Nested Loop (cost=168.22..2106.54 rows=148 width=329) (actual time=22.060..242.406 rows=10858 loops=1)
Buffers: shared hit=44963
-> HashAggregate (cost=168.22..170.22 rows=200 width=4) (actual time=21.529..32.820 rows=11215 loops=1)
-> Values Scan on "*VALUES*" (cost=0.00..140.19 rows=11215 width=4) (actual time=0.005..9.527 rows=11215 loops=1)
-> Index Scan using context_pkey on context c (cost=0.00..9.67 rows=1 width=329) (actual time=0.015..0.016 rows=1 loops=11215)
Index Cond: (c.key = "*VALUES*".column1)
Filter: ((c.tags @> '{blah}'::text[]) AND (c.x_id = 1))
Buffers: shared hit=44963
Total runtime: 263.639 ms
查詢時光從22000ms降低到200ms,僅僅一行代碼的轉變效力就進步了100倍。
在臨盆中應用的新查詢
行將宣布的一段代碼:

它使數據庫看起來更雅觀輕松. 

第三方對象
postgres慢查詢不存在了。然則有誰願意被0.1%不幸的多數熬煎。要立刻驗證修正查詢的影響,就須要Datadog來贊助我們斷定修正能否是准確的。
假如你想要找出對Postgres查詢轉變的影響,能夠須要幾分鐘來注冊一個收費的Datadog賬號。
英文原文:100x faster Postgres performance by changing 1 line