和其他數據庫一樣,DB2® V8 XML Extender 提供了兩種針對 XML 的存儲和訪問模型:XML 文檔可作為未解析文本完整地存儲在 CLOB 列中,也可以被映射和分解到一套關系表中。這兩種選擇都有一些已知的性能限制。DB2® 9 中新的 pureXML™ 技術試圖通過以其固有的層次格式存儲和查詢 XML 的方式來消除這些限制。本文描述了一系列度量方法,這些方法用於確定 pureXML 是否能夠提供性能優勢,並量化 pureXML 和 CLOB 或分解式存儲之間的性能差異。
簡介
DB2® 9 中的 pureXML™ 技術旨在為 XML 數據管理提供最高級別的性能。本文比較了 pureXML™ 技術與字符型大對象 (CLOB) 和分解式 XML 存儲的性能。許多數據庫系統允許將 XML 數據存儲為 CLOB 格式,或將數據“分解”到關系表中。DB2® V8 也支持這兩種選擇(通過 XML Extender),DB2 9 中仍然提供了 XML Extender,來實現向後兼容性。然而,它們將被 pureXML 特性所取代。
DB2 XML Extender 包括一套存儲過程、用戶定義的函數 (UDF),以及用戶定義的數據類型 (UDT)(這些類型將 XML 功能添加到核心 DB2 引擎之上)。XML Extender 的過程和 UDF 中配有 XML 解析器和特定於 XML 的邏輯,因而能夠執行由傳統 DB2 引擎特性支持的 XML 存儲和檢索。您能夠使用 XML Extender 的 XML Extender Column 或 XML Extender Collection 特性。
XML Extender Column 允許將 XML 文檔完整地存儲為未解析的純文本。此過程非常簡單,但是忽略了 XML 文檔的內部結構。您可選擇將 CLOB 列、VARCHAR 列或文件系統內的文件用作基礎存儲。在 VARCHAR 列中,XML Extender 僅能存儲最大 3KB 的文檔 —— 許多應用程序很難保證滿足此限制。高水平的數據庫管理員 (DBA) 能夠將此限制提高到 32k,但是通常情況下即使是這個最大值,應用程序也無法保證能夠滿足。外部文件存儲更為靈活,但是無法從數據庫管理的持久性和完整性中獲益。這就是 CLOB(能夠存儲最大 2GB 的文檔)成為 XML Extender Column 的最常用選擇的原因。本文將在後面探究 XML Extender CLOB 列的性能。
XML Extender Collection 允許將 XML 數據轉換為關系格式。這需要從預期的 XML 結構到數據庫模式中的關系表集合的固定映射。基於此映射,存儲過程從 XML 文檔中提取原子數據值,並將其插入到傳統關系行和列中。此過程稱為分解("shredding" 或 decomposition)。它涉及 XML 解析,並將單一邏輯 XML 文檔插入翻譯為一系列 SQL 行插入。在實際應用程序中,它能夠輕松使用數十個關系表來代表原始 XML 結構中的全部一對多關系。因此,映射很快就變得復雜起來,XML 插入性能也相應受到影響。一旦使用關系格式的數據可用,純 SQL 就可用於數據訪問和操作。然而,原始 XML 文檔的重構也非常昂貴。它需要以多路方式加入和生成合適的 XML 標簽。這些標簽可由標准化的 SQL/XML 發布函數 定義,來重構原始文檔或新的不同文檔。但是,XML Extender Collection 無法保留原始 XML 文檔的任何數字簽名。
以關系格式提供 XML 數據仍然是一個重要的需求。最常見的原因是需要向僅使用關系數據的遺留 SQL 應用程序、打包業務應用程序和商業智能 (BI) 工具饋送數據。因此,DB2 9 提供了新的 “分解” 解決方案,這種解決方案也稱為 “注釋模式分解” 或“新分解”,這種解決方案的速度是 XML Extender Collection 分解速度的 7 到 8 倍。本文將在後面比較這種新的高速分解方案和 IBM DB2 9 中的 IBM pureXML™ 支持的性能。
DB2 9 中的 新 pureXML 技術 和 CLOB 或分解式 XML 存儲有非常大的區別。它不將文檔存儲為純文本,也不將 XML 映射到關系或對象關系表。相反,它使用其固有的層次格式(這種格式匹配 XML 數據模型)存儲 XML。每個 XML 文檔均是定義良好的元素和屬性樹,並使用樹遍歷來表示 XML 查詢。因此,對應的層次存儲和處理格式會讓 XML 數據管理更為有效,這一點很自然。為了詳細解釋此觀點,本文將比較 DB2 9 中的 pureXML 和基於 CLOB 和分解式 XML 處理的性能。
測試設置
表 1 總結了本文進行的比較。本文對比了 CLOB 和分解式存儲的關鍵 XML 操作與對應的 pureXML 操作。
表 1:比較 CLOB 和分解式 XML 處理與 pureXML CLOB 中的 XML DB2 9 pureXML 將 XML 插入到 XML Extender CLOB 列 將 XML 插入到 XML 列 對 CLOB 進行完整的文檔檢索 對 XML 列進行完整的文檔檢索 在 CLOB 中使用 XML Extender “提取”功能查詢 XML(在查詢時解析 XML) 對 XML 列進行 XQuery 操作 分解到關系表的 XML DB2 9 pureXML 使用 DB2 9 的新分解特性,將 XML 分解到關系表 將 XML 插入到 XML 列 發布 SQL/XML,從關系數據構建 XML 文檔
(例如之前分解的 XML)
對 XML 列進行 XQuery 操作全部測試均使用以下數據和設置執行:
一個安裝了 IBM® AIX® 5.2 (64位) 和單一 DB2 9 實例的 4-CPU pSerIEs 系統
使用了 1,000 到 100,000 個 CustAcc 文檔(4kb 到 20kb 大小),這些文檔來自文章 “DB2 9 XML 性能特征” 中的金融場景
頁面大小為 32kb 的數據庫管理的 (DMS) 表空間
全部表空間均使用 no file system caching 選項定義,除非另外聲明(用於某些 CLOB 存儲測試)
全部表空間分布在 10 個物理磁盤上,數據庫日志位於獨立的等量列中
全部測試均使用了相同的數據庫配置和調優,來確保性能比較的公平性和有效性
比較 CLOB 和 pureXML 列
這種比較是很有趣的,因為對於當今相當多的 XML 應用程序來說,CLOB 列是 XML 存儲最常用的選擇。在 DB2 9 出現之前,沒有更好的備選方案。CLOB 存儲和 pureXML 處理之間的基本區別在於 XML 解析及其對插入和查詢性能的巨大影響。
如果 XML 文檔被插入到 CLOB 列中,那麼它們就是作為未解析文本對象插入的。避免在插入時進行 XML 解析對性能有益,對於 CPU-bound 型系統尤其如此。然而,如果不進行 XML 解析,XML 文檔的結構會被完全忽略。因此數據庫無法對存儲的文本對象執行智能和有效的搜索和提取操作。惟一的補救方法是,在執行查詢時調用 XML 解析器來“搜索” XML 文檔,以便找到符合搜索條件的內容。XML 解析巨大的 CPU 占用率通常會導致很低的搜索和提取性能。只有盲目、全面的文檔檢索(這會再次忽略內部 XML 結構)能夠快速從 CLOB 列讀取 XML 文檔。
DB2 9 中的 pureXML 技術在插入時(而不是查詢時)解析 XML 文檔。XML 文檔以已解析的格式被存儲和查詢,這在 DB2 9 中使用一種新的數據類型 “XML” 來表示。這種已解析格式使用節點樹結構,有別於 XML 文檔的文本表示。搜索和提取操作的執行無需進行 XML 解析,這會獲得巨大的性能益處,因為 XML 解析開銷發生在插入時。類似地,對 XML 列進行文檔檢索需要串行化,即,將已解析的 XML 格式轉換回其原始文本表示。當從 CLOB (在 CLOB 中 XML 本來就是以文本形式存儲的)讀取完整的 XML 文檔時,不存在此開銷。
總之,CLOB 存儲為插入和全文檔檢索操作提供了優秀的性能,這通常是以搜索和提取性能下降為代價的。DB2 9 中的 XML 數據類型犧牲了某些插入和檢索性能,來獲得更高的搜索和提取性能。這是一種合理的折衷方案,因為業務數據的搜索和分析頻率要高於插入頻率。通常是一次插入、多次搜索。另外,因為 XML 列在緩沖池中緩存而 CLOB 列不是,所以 XML 列的潛在開銷通常會增加。
下一節介紹用於量化這些折衷方案的性能度量指標。
比較 CLOB 插入和 XML 插入
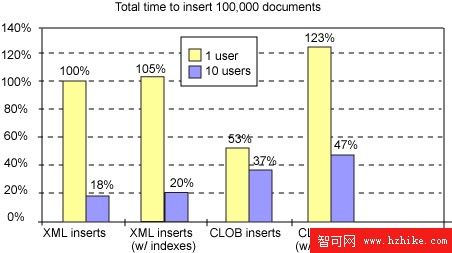
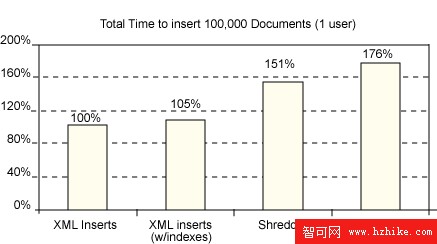
在第一個測試中,我們順序插入 100,000 個具有或不具有索引的文檔,像許多 OLTP 應用程序那樣在每個文檔之後提交。圖 1 中的結果顯示了 XML 和 CLOB 列插入之間的相對占用時間(越低越好)。將 XML 插入的占用時間用作比較基線 (100%),維護 6 個 XML 索引僅需很小的開銷(在我們的場景中是 5%)。
圖 1:比較 XML 和 CLOB 列的單用戶插入性能
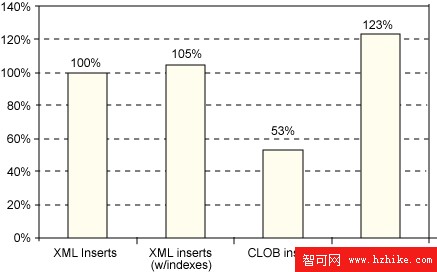
向 CLOB 列插入相同的 XML 數據約占用一半的時間(53%)。這是因為避免了 XML 解析和對 XML 數據的進一步處理。簡單地說,XML Extender “索引表”對應 CLOB 列,真正的 XML 索引對應 XML 列。在插入時維護索引表需要 XML 解析和額外的關系插入,因為選擇的 XML 元素和屬性值是分別提取和存儲的。因此,插入占用時間至少等於 pureXML 插入的占用時間,在我們的場景中甚至高出了 23%。。
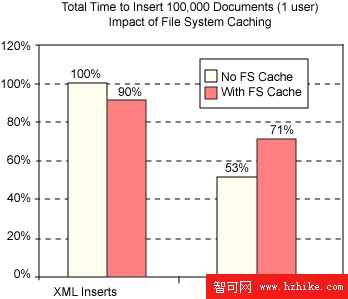
圖 1 中的試驗對 DB2 表空間使用了 no file system caching 選項。如果您允許 DMS 表空間容器使用文件系統緩沖(圖 2),那麼 XML 插入性能僅有少量改進,而 CLOB 插入性能卻會下降。因為 CLOB 插入使用直接寫入的方式,所以無需文件系統緩存,而僅有純開銷。然而,如果不涉及 XML 解析,那麼文件系統緩存能夠幫助提高對 CLOB 列的讀操作。
圖 2:文件系統緩存對 XML 和 CLOB 列插入的影響(無索引或索引表)
單用戶數據庫應用程序非常少見,因此考察並發工作負載的性能行為十分重要。我們將插入測試修改為使用 10 個各自具有到數據庫的獨立連接的並發線程,每個線程連續插入 10,000 個文檔。 圖 3 顯示增加的工作負載密度大大影響了 CLOB 性能。雖然 CLOB 插入的速度在單用戶測試中是 XML 插入的兩倍(圖 1),但是它們在多用戶測試中卻慢了兩倍(207%)。這是因為 CLOB 插入從並行性中的獲益不如 XML 列插入多。隨著並發程度的提高,XML 列緩沖的插入比 CLOB 的並發直接寫入更具伸縮性。
圖 3:XML 和 CLOB 列的多用戶插入性能比較
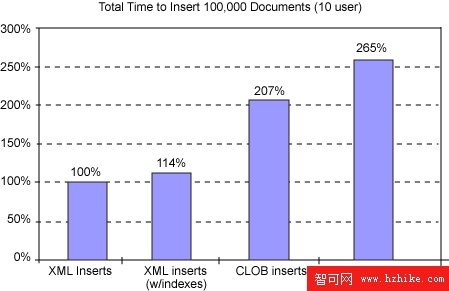
圖 4 表明並發性加速對 XML 列的作用要遠遠高於對 CLOB 列的作用。將單用戶 XML 插入用作 100% 基線,我們的系統和配置允許 10 個並發插入流在 18% 的時間內插入相同的 100,000 個文檔,速度快了 5 倍。CLOB 插入無法從並發性中獲得相同的益處,是基線的37%,僅是非並發 CLOB 插入的 1.4 倍。
圖 4:XML 和 CLOB 列插入的並發加速
我們還使用了 1000、5000、10,000 和 50,000 個文檔進行了全部這些插入測試。正如所料,CLOB 和 XML 列占用的插入時間和插入的文檔數成線性比例。因此為了簡便起見,我們省略了相應的圖表。
CLOB 和 XML 列的 XML 查詢比較
為了評估 XML 和 CLOB 列之間的查詢性能差異,本文設計了 5 個查詢來涵蓋以下常見的搜索和檢索情況:
對全部文檔進行全文檔檢索,無謂詞
對匹配某個標准的一個文檔進行全文檔檢索(一個謂詞)
對匹配某個標准的多個文檔進行全文檔檢索(多個謂詞)
對全部文檔進行部分檢索
對匹配某個標准的全部文檔進行部分檢索
這些操作使用如下 5 個查詢實現:
Q1 (Select*):選擇全部 XML 文檔(選擇 <table>中的全部文檔)
Q2 (1Pred1Doc):返回一個給定帳號的客戶文檔
Q3 (5PredSome):返回全部主要地址在加利福尼亞、擁有美元帳戶、尚未達到高級客戶級別的女性客戶的客戶文檔
Q4 (PartialAll):返回每個客戶的姓名及其帳戶的余額總數
Q5 (PartialSome):獲取全部在其任意帳戶中持有 IBM 股票的客戶的主要電子郵件地址
對於 CLOB 來說,這些查詢使用具有 XML Extender 提取函數的 SQL 表示。 對於 XML 列來說,這些查詢使用 XQuery 表示法。無論 XQuerIEs 是嵌入在 SQL 中還是單獨執行,在我們的測試中並沒有性能區別。全部查詢和某些示例數據在 可下載的 zip 文件 中提供。
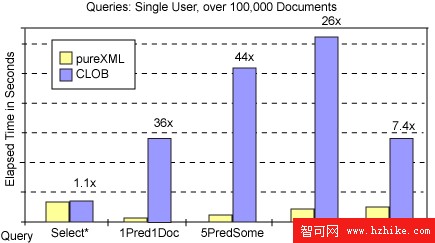
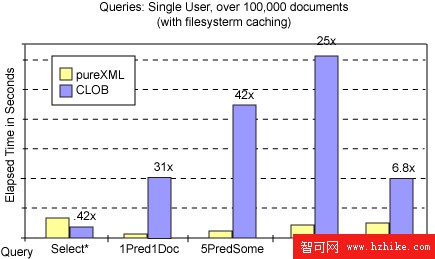
圖 5 顯示了對 pureXML 和 CLOB 進行的全部 5 個測試查詢的查詢性能(占用時間)。您可看到 pureXML 查詢的速度可以很輕松地達到 CLOB 列中的 XML 速度的 20、30 或 40 倍。這些是沒有用於表空間的系統文件緩存的默認設置的結果。圖 6 包括具有 文件系統緩存的相同結果。文件系統緩存僅對查詢 Q1(檢索全部文檔,無謂詞運算)有較大影響。在沒有文件系統緩存的情況下,XML 和 CLOB 列的 Q1 執行效果類似,不在緩沖池進行緩沖的 CLOB 列略微落後(10%)。文件系統緩存大大改進了 CLOB 檢檢索性能(參見 圖 6),因此查詢 Q1 速度能夠達到 XML 列的兩倍以上。這是因為從 XML 列讀取數據需要串行化或將已解析的 XML 轉換回文本格式。在沒有文件系統緩存的情況下,XML 列在 DB2 緩沖池進行緩沖而 CLOB 列則不是,從而可降低開銷。
圖 5:查詢性能,無索引,無文件系統緩存
對於查詢 2 到查詢 5,文件系統緩存的影響不大。這些查詢通常需要子文檔級訪問來運算謂詞和提取文檔片段。這是 pureXML 的真正的妙處所在:XML 以已解析格式存儲,因此在查詢執行時不需要解析。在我們的測試中,這會獲得 7 到 44 倍的性能加速。
圖 6:查詢性能,無索引,有文件系統緩存
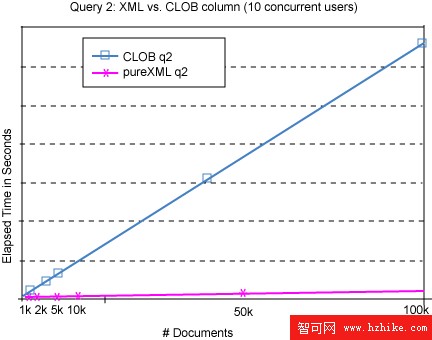
XML 列和 CLOB 列之間的查詢響應時間差異隨著需要解析(針對 CLOB)或遍歷(針對 pureXML)的數據量的增加而顯著增加,注意到這一點是很重要的。圖 7 顯示查詢響應時間作為表中文檔數(范圍從 1,000 到 100,000)的函數(不使用索引或索引表)。
圖 7:查詢 2 的性能作為數據量的函數
XML Extender 提供索引表的概念來加速對 XML 文檔的搜索,以便避免針對謂詞運算的 XML 分析。在插入時,特定元素和屬性被提取到關系表。您已經知道這會給 CLOB 插入增加巨大開銷,但是這也會使索引表被有效地搜索,並和包含 CLOB 的主表結合。我們的 5 個測試查詢中的 3 個(q2、q3 和 q5)包含過濾謂詞,這些謂詞能夠從索引表查找中獲益。索引表能夠避免許多針對 CLOB 的 XML 解析,這通常能夠使 CLOB 查詢速度快 100 倍或更多。
在 圖 8 中,讓我們將其和能夠提供類似獲益的具有實際 XML 索引的 pureXML 進行比較。圖 8 中的全部 6 個示意條都代表不大於一秒的占用時間。而具有索引的 pureXML 的速度是具有索引表的 CLOB 列的速度的 6 到 35 倍。造成這種情況有多種原因。pureXML 索引直接指向具有對應文檔的行。在使用索引表的情況下,DB2 首先對索引表執行索引查找,然後將對應的行和包含 CLOB 的主表相結合。查詢 Q3 (5PredSome) 具有多個謂詞、使用 3 個索引表和主表,因此它需要計算一個 4 路結合。Query Q5 對謂詞使用索引表,但是需要提取函數(具有 XML 分析)來檢索客戶電子郵件地址。
圖 8:具有索引 (pureXML) 和索引表 (CLOB) 的謂詞運算
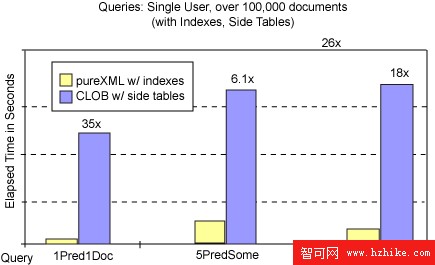
圖 8 說明,即使索引表能夠降低必須解析的 CLOB 數,DB2 9 中的 XML 索引也能夠類似地降低必須針對謂詞運算進行遍歷的文檔數。因此,使用索引和索引表通常能夠縮短 XML 和 CLOB 的絕對占用時間,但是不會消除 XML 相對 CLOB 列較大的相對性能優勢。
對 CLOB 和 XML 使用 10 個用戶進行多用戶查詢測試。因為 CLOB 和 pureXML 存儲之間的相對性能差異類似於上述單用戶測試,所以這裡省略了測試結果。
比較分解式存儲和 XML 列
將 XML 數據分解到關系表仍然是常見的一種需求。一個典型原因是現有應用程序可能還不能理解 XML,因而需要關系格式的數據。這包括遺留 SQL 應用程序、打包業務應用程序以及 BI 和報告工具。DB2 9 中的注釋 XML 模式分解(“新分解”)解決了較老的 XML Extender 分解的功能和性能限制。下一節比較了新的 DB2 9 分解性能和 DB2 9 中的 pureXML 技術。
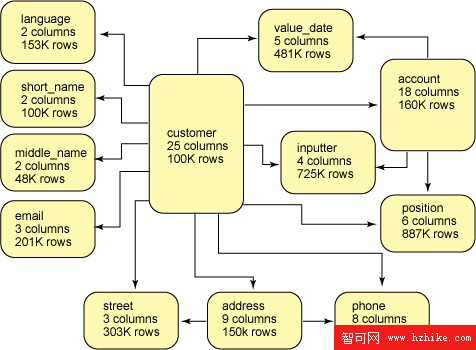
對這些測試使用了和之前測試相同的客戶數據。因為存在各種重復的元素,所以需要 12 個表中共 87 個列來代表傳統關系模式中的 XML 數據。此模式如 圖 9 所示,圖 9 指示了在分解了 100,000 個客戶文檔之後,每個表中的列數和行數。總之,這些表包含 350 萬個關系行,來代表這 100,000 個 XML 文檔。圖 9 中的箭頭指示一對多關系。全部主鍵和外鍵均定義了索引,來支持 12 個表之間有效的結合。
圖 9:使用關系模式持有分解式 XML 數據
比較分解方法和具有 pureXML 插入的關系表
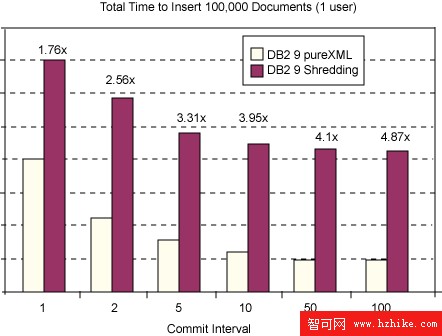
使用此關系模式(具有DB2 9 中新的注釋模式分解)分解 100,000 個文檔的速度比將相同的 XML 文檔插入 XML 列慢了 1.75 倍(參見 圖 10)。此操作在每個文檔之後執行,這是 OLTP 應用程序的典型操作。
圖 10:比較 pureXML 插入和 DB2 9 分解(在每個文檔之後執行)
如果降低執行的頻率,就能提高 XML 列相當於分解的性能優勢。每隔一個文檔執行可使 XML 插入比分解快 2.56 倍(在我們的場景和配置中)。對於大量的插入或導入操作來說,如果每隔 50 或 100 個文檔執行一次,可使 XML 列插入比分解快 4 到 5 倍(參見 圖 11)。XML 列插入能夠從較大的間隔中獲得比分解(每個日志 I/O 請求有更多的日志頁面)更多的益處。
圖 11:比較 pureXML 插入和 DB2 9 分解(不同的執行間隔)
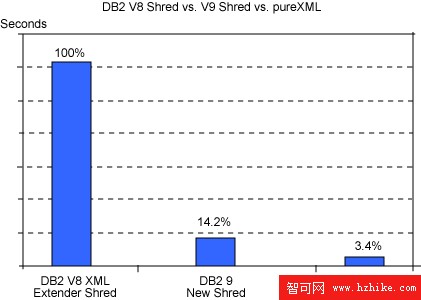
在執行間隔為 50 的情況下,圖 12 比較了 DB2 9 中新的注釋模式分解與 V8 中的 XML Extender 分解和 pureXML 插入。在我們的測試中,新的分解比 XML Extender 分解快 7 倍,pureXML 插入甚至比 V8 分解快 30 倍。
圖 12:比較 DB2 V8 XML Extender 分解和 DB2 9 技術(執行間隔 = 50)
比較分解數據上和 pureXML 列上的 XML 查詢
假設您需要為面向 XML 的應用程序和 web 服務(需要 XML 格式的查詢結果)提供服務。如果 XML 數據被分解到關系表,那麼關系查詢結果必須被轉換回 XML。為了實現此目的,可在 SQL 查詢的 SELECT 從句中使用 SQL/XML 發布函數來構建結果集所需的 XML 標簽。
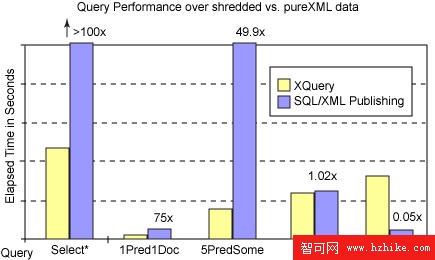
圖 9 中定義了關系模式的 5 個 SQL 查詢,它們邏輯上等效於 XML 列的 5 個 XQueries。這些 SQL 查查詢使用傳統關系謂詞,結合一些或全部表,並使用 SQL/XML 發布函數來返回和 XQuerIEs 相同的 XML 結果。圖 13 中顯示了相關的性能結果。
Query Q2 (1Pred1Doc) 基於一個帳號查找僅返回一個文檔。在兩種情況下(pureXML 和發布)都具有帳號的索引來改進查詢性能。雖然 SQL/XML 查詢速度很快,但是仍然比 XML 列的 XQuery 慢 75 倍。這是因為 XQuery 僅需通過索引定位文檔然後串行化文檔,而 SQL/XML 發布必須結合全部 12 個關系表並構建 XML 文檔。
QuerIEs Q1 (Select*) 和 Q3 (5PredSome) 返回許多文檔,因此增加了從關系數據構建 SQL/XML 文檔的成本。Query Q4 (PartialAll) 從每個 XML 文檔讀取幾個值,並根據這些值構建全新的文檔。當使用 pureXML 存儲上的 XQuery 時,值從 XML 列中讀取,構建使用 XQuery 來完成。當使用分解式數據的 SQL/XML 發布時,值從關系列中讀取,構建使用 SQL/XML 來完成。兩種情況下的瓶頸都是構建操作。這就是兩種版本的 Q4 執行結果類似的原因。
圖 13:比較 pureXML XQuery 和分解式數據的 SQL/XML 發布
Q5 (PartialSome) 使用多個謂詞來返回僅具有一個元素的少量 XML 文檔。在這種情況下,使用 SQL/XML 的成本不太高,因為它僅針對每個結果行構建一個因素,僅結合 12 個表中的 3個。因為關系數據搜索從某種程度上比 XML 數據搜索速度快,所以其性能比分解式數據好(在我們的設置中比 XQuery 速度快 20 倍)。
結束語
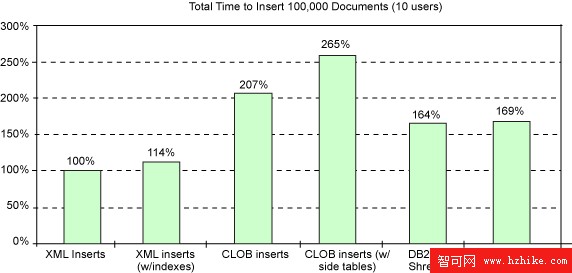
雖然對於單用戶工作負載來說,CLOB 插入的速度可能快於 pureXML 插入的速度,但是典型業務場景下的密集並發插入可使 CLOB 插入速度比插入到 XML 列的速度慢 2 或 2.5 倍。如果在每個文檔後執行插入操作,那麼 pureXML 插入速度約比 DB2 9 中的新分解解決方案快 60% 到 70%。 對於執行頻率低的大量插入或導入來說,pureXML 獲取 XML 數據的速度比分解甚至快了 4 到 5 倍。這些測試使用了 DB2 9 中的新分解解決方案,此解決方案的速度比 V8 中的 XML Extender 分解速度快了 7 到 8 倍。
XML 類型列中 XML 數據的 XQuery 速度比 CLOB 的對應查詢(需要在查詢時進行 XML 解析)速度快了 40 倍。“pureXML 查詢”和“CLOB 查詢”之間的絕對性能差異,隨查詢數據量的增加而(線性)增加。
分解式數據的 pureXML XQuery 和 SQL/XML Publishing 之間的相對性能差異主要取決於需要標記為 XML 的關系數據量,以及所需要的連接(JOIN)操作數。當必須檢索復雜的數據時,XQuery 明顯優於發布查詢。在我們的一些測試中,從 DB2 pureXML 存儲檢索 XML 數據能夠比從關系表中構建 XML 數據快 50 到 100 倍。然而,無需復雜結合的簡單搜索查詢(返回的結果帶有少量或沒有 XML 標簽)在 SQL 中速度更快。應用程序仍然需要在查詢性能和插入性能之間權衡,並評估兩者的混合使用。圖 14 中總結了 XML 插入的性能。
圖 14:XML 插入性能總結 (commitcount =1)
請注意:本文中的全部性能結果都是在隔離的實驗室環境(具有特定硬件、操作和數據庫配置)下獲得的。在不同的環境下進行的不同測試所獲得的結果可能和本文獲得的結果有或多或少的性能差異。
雖然我們的全部測量僅使用了 DB2,但是許多與 CLOB 和分解式 XML 存儲有關的性能問題,是其各自的一般概念(將 XML 存儲為文本或將其轉換為關系數據模型)所固有的。因此,您可在支持這些概念的其他 DBMS 環境下發現類似的性能特征。對此類問題感興趣的讀者可以在自己的環境下探索此類問題,並可將本文中的材料用作開發自己的測試的基礎。