DB2 Magazine 是一種專門針對數據庫管理員、分析員、程序員、設計師、顧問以及 MIS/DP 經理的季刊,其內容涵蓋了所有 DB2 平台(包括 IBM AIX、Hewlett-Packard HP-UX、Sun Solaris、SCO UnixWare、Linux、Microsoft Windows NT、Microsoft Windows 95、Microsoft Windows 98、IBM OS/2、IBM OS/400、IBM MVS、IBM OS/390、IBM VM 和 IBM VSE )的各種主題。
為了從 DB2 Information Integrator 獲得最佳性能,DBA 需要知道哪些東西。
大多數 DBA 都知道,對於性能低下的 SQL 查詢,為了發現、評估和實施有助於改善其性能的改進方法,需要完成哪些任務。然而對於聯邦查詢,DBA 必須學習新的技巧,拓寬一般情況下的查詢調優任務列表,以便處理由 DB2 Information Integrator (DB2 II) 提供的新功能。
DB2 II 支持跨多種數據源的聯邦查詢,這些數據源包括 SQL Server、Oracle、Informix、Sybase 和 DB2 Universal Database (UDB) for z/OS,以及 iSerIEs、Linux、Unix 和 Window。DB2 II 產品是一個中間件,其中包含的優化和數據訪問技術,充分調動了底層數據源的能力,並為這些不同的源提供一種統一訪問語言(SQL)。
DB2 II 產品已經為那些之前不能訪問或者不易訪問的信息源敞開了大門。盡管如此,隨著每一項新的數據支持技術的出現,新的調優機會也應運而生。使用 DB2 II 並不確保最優執行每一個查詢。DBA 要做的工作,仍然是發現和調優性能低下的查詢。
聯邦對象帶來了新的挑戰。在這一期,我將解釋調優聯邦查詢時所需的任務和工具。本文假設您對 DB2 II 有一個基本的了解。您可以通過在參考資料小節中列出的文章,或者通過 ibm.com/software/data/integration 溫習 DB2 II 方面的知識。如果您想了解 Merrill Lynch(我的雇主),是如何利用 DB2 II 解決現實生活中的業務問題的,請參閱文章 "Taming the Beast"。
基本調優任務
對任何性能低下的 SQL 語句進行調優都需要一種有條不紊的方法。毫無計劃地更改參數只能讓每一次做出的更改難於判斷效果。如果某一次更改對性能起了反作用,那麼您需要知道應該退回到哪一次更改。
不管調優什麼 SQL,都應該執行以下任務:
評估當前性能,並記錄到文檔。
與創建查詢的人會談,並得出合理的性能預期。
建立查詢的業務目標。
對於來自生產系統的查詢,獲得一個 Explain 計劃。
如果可行的話,在測試系統上重建環境,並重新運行查詢。
對於與查詢相關的所有表,確信最近在這些表上執行了 Runstats 或與之等價的遠程命令。
確保各個表的重組,以匹配它們的集群索引。
查找 WHERE 子句中索引列上的 SQL 函數,這些函數可能導致優化器忽略了索引。
確保在 WHERE 子句中盡可能使用索引列。
查找笛卡兒積(Cartesian products)。
跟蹤每一項更改的效果,每次跟蹤一項。
聯邦調優任務
由於聯邦查詢連接到了不同的數據源,調優的第一步是將查詢分解為兩部分:本地和遠程。本地部分使用駐留在 DB2 II 服務器上的對象,而遠程部分使用駐留在遠程主機上的對象。通過這種方式劃分聯邦查詢,有助於判斷影響性能問題的根源。
DB2 II 服務器中的所有聯邦對象在 syscat.tables 編目表中都是以昵稱(TYPE=N)的形式標識的。也可以通過 EXPLAIN 命令識別查詢中的聯邦對象,該命令將顯示 DB2 II 引擎選擇的全局訪問計劃。EXPLAIN 命令的輸出是判斷優化器是否將為查詢使用“疊加(push-down)”處理(即在遠程服務器上執行的處理)的惟一途徑。DB2 II 使用來自包裝器、服務器和昵稱對象的信息,來判斷什麼任務可以疊加到遠程服務器。
清單 1 展示了一個存儲在 db2ii-query.sql 文件中的聯邦查詢的實例。以粗體標記的表(mids.tbacct 和 mids.tbacct -hldr)上的查詢引用了遠程對象。而表 table hjg.iitbl 則是在 DB2 II 服務器本地。Explain 將把這個查詢分解成幾個部分。對於將要使用疊加處理的部分,以 ship 這個詞標記。清單 2 展示了 Explain 輸出的一個縮節本。優化器將子查詢 #1 標記為“shipable”。
清單 1. 聯邦 SQL 查詢
db2expln -d dbdsdr -stmtfile db2ii-query.sql -o db2ii-query.out -terminator ";" -g
select a.dsssca-no
, a.dssas-ty-cd
, imlp-1st-nm
, imlp-lst-nm
, mlp-st-cd
ac-eom-ast-am
from mids.tbacct a
, mids.tbacct-hldr ah
,hjg.iitbl
where a.dsssca-no =ah.dsssca-no
and ac-eom-ast-am > 1000000
and st-cd =mlp-st-cd and-mlp-st cd ='ny'
fetch first 1 rows only
清單 2. Explain 輸出,其中標記了要做疊加處理的查詢
| Ship Distributed Subquery #1
| | #Columns = 6
Return Data to Application
| #Columns = 6
查詢的這個部分由優化器生成,其中只包含那些訪問遠程數據源的對象。清單 3 展示了 Explain 輸出的一部分,其中有重寫後的查詢。這個清單中的輸出含有關於查詢的信息,包括將被發送到遠程數據源的 SQL、使用的昵稱以及遠程服務器的名稱及相關版本(在這裡是 MIDASP)。如果您對完整的 Explain 輸出有興趣的話,請下載文件: IBM DB2 Universal Database SQL Explain Tool (DOC, 30K)。
清單 3. 優化器重寫的訪問遠程對象的查詢。Distributed Substatement #1:
Server: MIDASP (DB2/UDB 7.1)
SQL Statement:
SELECT A0."DSSSCA-NO", A0."AC-EOM-AST-AM", A0."DSSAS-TY-CD", A1."MLP-ST- CD", A1."IMLP-1ST-NM", A1."IMLP-LST-NM"
FROM "MIDS"."TBACCT" A0, "MIDS"."TBACCT-HLDR" A1
WHERE (1000000 < A0."AC-EOM-AST-AM") AND (A1."MLP-ST-CD" ='NY') AND (A0."DSSSCA-NO" =A1."DSSSCA-NO") FOR READ ONLY
Nicknames Referenced:
MIDS.TBACCT-HLDR ID = 33125
Base = MIDS.TBACCT-HLDR
MIDS.TBACCT ID = 33124
Base = MIDS.TBACCT
如果將兩個遠程表(a.dsssca-no =ah.dsssca-no)之間的連接謂詞去掉,那麼將得到一個笛卡兒乘積。如果在做出這樣的更改之後發出 EXPLAIN 命令,則 DB2 II 優化器會把數據取到它的服務器上,並在本地執行連接操作,而不是把連接發送到遠程服務器,這樣可以減少網絡傳輸。清單 4 展示了這個 SQL 例子,並給出了與之相關的 Explain 輸出的一部分(完整的輸出在網上有提供)。
清單 4. 重寫的查詢,將數據取到 DB2 II 服務器進行本地處理
| Ship Distributed Subquery #1
| | #Columns = 3
| Nested Loop Join
| | Access Table Name = HJG.IITBL ID = 62,24
| | | #Columns = 1
| | | Relation Scan
| | | | Prefetch: Eligible
| | | Lock Intents
| | | | Table: Intent Share
| | | | Row : Next Key Share
| | | Sargable Predicate(s)
| | | | #Predicates = 1
| | | | Process Probe Table for Hash Join
Return Data to Application
| #Columns = 6
Distributed Substatement #1:
Server: MIDASP (DB2/UDB 7.1)
SQL Statement:
SELECT A0."AC_EOM_AST_AM", A0."DSSSCA_NO",
A0."DSSAS_TY_CD"
FROM "MIDS"."TBACCT" A0
WHERE (1000000 < A0."AC_EOM_AST_AM")
FOR READ ONLY
Nicknames Referenced:
MIDS.TBACCT ID = 33124
Base = MIDS.TBACCT
#Output Columns = 3
Distributed Substatement #2:
Server: MIDASP (DB2/UDB 7.1)
SQL Statement:
SELECT A0."MLP_ST_CD", A0."IMLP_1ST_NM",
A0."IMLP_LST_NM"
FROM "MIDS"."TBACCT_HLDR" A0
WHERE (A0."MLP_ST_CD" ='NY')
FOR READ ONLY
Nicknames Referenced:
MIDS.TBACCT_HLDR ID = 33125
Base = MIDS.TBACCT_HLDR
#Output Columns = 3
End of section
在 Explain 命令中使用 -g 選項可以增加訪問計劃的樹狀圖形顯示,類似於 DB2 Control Center 的 visual Explain (見清單 5)。
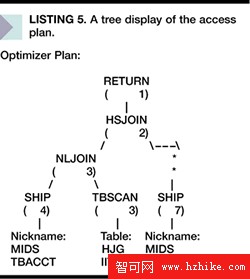
疊加處理
在用 EXPLAIN 命令分析了訪問計劃,並且識別了本地和遠程對象之後,真正的工作就開始了。您必須確定是查詢的哪一部分導致了性能瓶頸。
如果看到查詢的一個部分引用了遠程對象,但處理沒有被發送到遠程數據源,那麼您可能已經發現了問題的起因。但是,沒有明確的規則可以一針見血地指出問題所在。很多調優都需要反復試驗。如果您懷疑查詢的某個部分應該被疊加,但是 Explain 顯示並沒有發生該疊加,那麼接下來要做的就是,檢查那些對優化器的訪問路徑決策有影響的參數。
雖然 DB2 II 引擎努力地送出盡可能多的工作,以便優化性能,但是,如果由於函數方面的問題而沒有送出工作,或者如果優化器斷定本地處理更為高效,那麼 DB2 II 引擎就會在本地處理工作。
查詢中可能阻礙疊加處理發生的函數方面的問題包括:
對於某個函數,DB2 II 知道在遠程沒有與之對等的函數。
某個 SQL 結構在遠程數據源上不受支持,因而不能重寫成遵從遠程數據源的 SQL 本地語言的形式。
遠程數據源上的一個排序序列不同於 DB2 II(或另一個遠程數據源)上的排序序列,這將導致一些 SORT 和不等價的謂詞不能應用到基於字符的屬性上。
記住,DB2 II 還可能因為性能方面的原因而避免使用疊加,例如避免笛卡兒乘積。笛卡兒乘積會生成很多行,因而將導致過多的網絡傳輸。為了避免這種情況,優化器可以決定把連接所涉及的表中的數據取放到 DB2 II 服務器中,並在本地執行連接。
昵稱統計信息
DB2 II 服務器不把處理放到遠程服務器上執行的最常見的一個原因是,在遠程數據源上,關於對象的統計信息是過時的,或者根本不存在。當創建昵稱時,遠程數據源的統計信息被檢索並插入到 DB2 II 本地編目中。通過對昵稱進行 NNSTAT 存儲過程,可以從遠程數據源刷新統計信息。然而,這種方法不能保證遠程統計信息是最新的。對於將要更新的統計信息,在使用 CREATE NICKNAME 或 NNSTAT 命令將刷新後的統計信息傳播到 DB2 II 服務器之前,必須在遠程對象的源上執行 Runstats 實用程序(或在遠程數據源上與之等效的實用程序)。
為了使遠程服務器信息盡可能准確,DB2 II 8.2 允許按照設定的時間間隔調度 NNSTAT 命令。將來的版本可能會自動地按設定的頻率判斷一個遠程對象的統計信息是否已發生變化,並更新 DB2 II 編目中的統計信息。
DB2 II 服務器選項
您還可以使用另外一組參數來影響疊加處理的行為:服務器對象選項。使用表 1 中的選項將遠程數據源的屬性(如字符串排序序列)告知聯邦服務器。
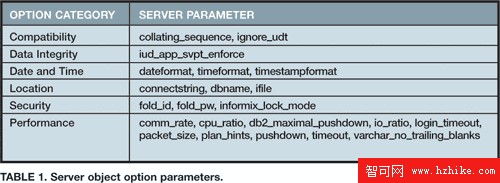
當您提供更多關於遠程數據源的信息時,就是在幫助優化器理解,到遠程數據源的疊加處理可能更為高效。例如,將 CPU-RATIO 選項設為 0.1 表明遠程服務器的能力是本地 DB2 II 服務器十倍那麼強。只要沒有函數方面的問題,得到上述信息的優化器很可能會選擇疊加盡可能多的處理。
另一個會影響疊加行為的參數是 db2-maximal-pushdown。優化器的缺省行為是根據最低預估成本(db2-maximal-pushdown = 'N')估計疊加的機會大小。把 db2-maximal-pushdown 參數設為 'Y' 將改變優化器的估計標准,而更加重視網絡傳輸量。如果是這樣設置,那麼該選項將導致優化器偏好本地 DB2 II 服務器與遠程數據源之間網絡通信量較少的策略。您可以使用這個選項,通過改變優化器決策矩陣中的一個核心參數,來比較查詢的性能。
您還可以用不同的選項設置創建到相同數據源的多個服務器對象。在調優實踐中使用這個功能來判斷不同選項設置的效用。您可以使用 SET SERVER 命令臨時設置服務器選項,後面我還會更詳細地解釋。
昵稱參數
您可以修改與某個昵稱相關的一列,方法是改變其本地類型映射,或者添加一個列選項。不管采用哪種方法,這種附加信息都將促使優化器使用疊加處理。
例如,Oracle 使用 (38,0) 數據類型表示一個整數,但 DB2 II 服務器會將該數據類型翻譯成一個浮點數據類型。通常,對於一個查詢,需要連接分別來自這兩種數據庫的表,在結果集返回之前,DB2 II 服務器會定位到所有數據來進行列的比較。如果將昵稱列的數據類型修改成整型,那麼優化器會決定在遠程數據源上執行工作。修改昵稱的命令語法是:
alter nickname ben.
timesheets-short alter
column hours local type
integer
將一個列選項應用於某個昵稱列,還可能影響優化器對疊加方法的使用。例如,如果指示優化器,有一個列具有以字符表示的數字,則會導致優化器將排序處理疊加到遠程數據源上執行,即使排序序列不相同也在所不惜。表 2 展示了會影響優化器選擇的列選項。下面的語法展示了如何設置昵稱列上的列選項:
alter nickname ben.
timesheets alter column
employee-number
options (set numeric string
'y' )

有用的工具
您可以使用很多工具來幫助調優聯邦查詢。我已經提到了 Explain 實用程序,這是最重要的一個。記錄查詢的執行度量是一種基本的調優任務,其他工具在這方面可以起到輔助作用。
例如,通過使用 db2 命令的 -l 選項,可以創建一個日志文件,文件中包含查詢的開始時間和結束時間。
db2 -l < log file name > -tvf
< file containing SQL >
您還可以使用 db2batch 實用程序記錄查詢計時。這個標准實用程序是 DB2 附帶的,用於基准化查詢。該工具最簡單的用法是這樣的:
db2batch -d < database name > -f
< file containing SQL >
另一個用於監控聯邦查詢的執行情況,以及監控資源利用情況的得力工具是 DB2 snapshot。snapshot 顯示消耗的時間和有關聯邦查詢的其他關鍵信息,以及聯邦查詢的所有遠程分段。表 3 展示了啟動 snapshot 命令的兩種方法。

在為 Linux、Unix 和 Windows version 8 等環境設計的 DB2 UDB 版本中,IBM 創建了很多基於 snapshot API 的用戶定義函數。這些 UDF 使用 SQL 語法來調用,它們分行和列返回 snapshot 的值。我推薦使用的這些新函數為您提供了獲得調優的關鍵性能的標准方式。這些技術可以在同類軟件間共享,並且是可移植的。將 snapshot 函數輸出與數據庫編目信息相連接的這種能力優化和增強了收集過程,並加快了解決問題的速度。一些非常復雜的公式可以封裝在 SQL 語句或存儲過程中。(要了解關於 snapshots 的更多信息,請參閱參考資料中的文章)。
您可以使用 CREATE SERVER 命令永久地設置 DB2 II 對象的選項。為了臨時設置這些選項,可以使用 SET SERVER 選項命令。該命令的語法如下:
set server cpu-ratio to 0.1
for server ben
在以上的 SET SERVER 例子中,CPU-RATIO 被設為 0.1,但只在當前會話的生命周期內有效。在調優查詢的時候請使用這個命令,因為它使您可以重復測試不同的情況,並使用 Explain 實用程序檢查結果。與創建多個帶不同選項的服務器,或者通過刪除已有的服務器對象來更改設置這些做法相比,這種方法干擾更少,並且也靈活得多。
為了確定聯邦查詢某一部分的各項性能,或者判斷是否正確地設置了訪問許可,可以使用 set passthru 命令。該命令使用戶可以直接訪問遠程數據源,而不是借助聯邦引擎。一旦設置了 passthru,用戶就可以用合法的 ID 和密碼登錄到遠程數據源上。有一點要小心:如果您希望下次還使用聯邦引擎,那麼應記得執行 SET SERVER RESET 命令將此選項關閉。還應注意的是,passthru 模式下的查詢執行和使用本地客戶機接口不同。DB2 II 增加了一些系統開銷。
DBA 發揮作用
DB2 II 的精彩之處在於,它隱藏了執行跨平台連接和更新的復雜性。DB2 II 使開發人員不必編寫重復、復雜且繁瑣的例程,因而可以將注意力放在解決業務問題和加快推向市場上來。IBM 正在努力使這個軟件更具自主性。但仍需要有人來對查詢進行調優,以便提高其性能。在這方面,DBA 還有很多工作要做。