簡介
DB2 UDB Version 8.x 中的 xml(標准化越來越近了) 支持基於 DB2 的關系基礎設施。xml(標准化越來越近了) 數據要麼按原樣存儲為字符大對象(CLOB),要麼分解到關系表中。另一方面,DB2 UDB Viper 具有真正的 xml(標准化越來越近了) 數據本機支持。現在,將 xml(標准化越來越近了) 數據作為一種新的數據類型處理,存儲在一個經過解析並加上注釋的樹中,這個樹是與關系數據存儲分開的。還引入了基於 xml(標准化越來越近了) 模式的 xml(標准化越來越近了) 索引技術,並支持 XQuery 和 SQL/xml(標准化越來越近了) 作為查詢和發布 XML(標准化越來越近了) 數據的語言。
DB2 UDB Version 8.x 中的 XML(標准化越來越近了) 支持
DB2 8.x 使用 SQL/xml(標准化越來越近了) 和 DB2 xml(標准化越來越近了) Extender 向底層關系數據提供 xml(標准化越來越近了) 功能。DB2 xml(標准化越來越近了) Extender 提供許多用戶定義類型(UDT)、用戶定義函數(UDF)和存儲過程來支持 xml(標准化越來越近了)。xml(標准化越來越近了) 文檔存儲為關系形式,並使用 xml(標准化越來越近了) Extender 基礎設施為關系數據提供 xml(標准化越來越近了) 表現形式。還支持一些用來將關系數據發布為 xml(標准化越來越近了) 的 SQL/xml(標准化越來越近了) 函數。更多細節可以在 DB2 XML(標准化越來越近了) Extender Web 站點上找到。
DB2 還允許創建用戶定義的 Java 函數和存儲過程,可以將 XML(標准化越來越近了) 和 XSL 解析器(作為 DB2 8.x 的一部分安裝)合並到代碼中。
DB2 Viper 中的 XML(標准化越來越近了) 支持
DB2 Viper 支持本機 xml(標准化越來越近了) 存儲,從而不再需要將 xml(標准化越來越近了) 分解到關系表中供查詢和發布。這種新的存儲方式將 xml(標准化越來越近了) 保存為與 xml(標准化越來越近了) 文檔對象模型(DOM)相似的經過解析並加上注釋的樹形式。對於仍然需要將 xml(標准化越來越近了) 數據分解到關系表中的應用程序,這個版本中還提供了增強的分解功能,這種功能使用帶注釋的 XML(標准化越來越近了) 模式映射。
XML(標准化越來越近了) 特性對比 —— DB2 UDB Version 8.x 和 DB2 Viper
表 1. XML(標准化越來越近了) 特性對比 —— DB2 UDB Version 8.x 和 DB2 Viper
DB2 UDB Version 8.x
DB2 Viper
存儲和索引
XML(標准化越來越近了) 數據存儲為兩種形式:
原樣的文檔:
- xml(標准化越來越近了)CLOB、xml(標准化越來越近了)VARCHAR、xml(標准化越來越近了)FILE 類型的 XML(標准化越來越近了) Extender 列。
- BLOB、CLOB 或 VARCHAR 類型的列。
- 在關系副表中創建 XML(標准化越來越近了) 文檔的間接索引。
分解到關系 xml(標准化越來越近了) Extender(XML(標准化越來越近了) 集合):
- 只有 XML(標准化越來越近了) 中的葉節點可以分解並映射到 SQL 列類型。
- 功能有限,不能處理復雜的 XML(標准化越來越近了) 文檔。
XML(標准化越來越近了) 數據存儲為兩種形式:
原樣的本機文檔 XML(標准化越來越近了) 存儲。
- 從頭構建了全新的層次化(本機)存儲。這種存儲方式保存文檔的任意樹形式。
- XML(標准化越來越近了) 類型的列。
- 使用葉節點的路徑表達式建立 XML(標准化越來越近了) 索引。
- 在插入時對文檔進行解析。
用關系 SQL/XML(標准化越來越近了) 函數和帶注釋的模式映射進行分解。
- 使用帶注釋的 XML(標准化越來越近了) 模式映射分解到現有的關系表。
- xml(標准化越來越近了) 片段也可以分解,映射到 XML(標准化越來越近了) 列類型。
- 處理名稱空間。
- 可以使用擴展的功能過濾 XML(標准化越來越近了) 數據,比如 DB2 表達式和條件。
驗證
- DAD 中定義的隱式驗證。
- 使用 XML(標准化越來越近了) Extender UDF svalidate 進行顯式驗證。
- 文檔類型定義(DTD)注冊並存儲在內部表中。
- 從文件系統獲得 XML(標准化越來越近了) 模式。
- 使用 SQL/xml(標准化越來越近了) 函數 XML(標准化越來越近了)VALIDATE 進行顯式驗證。
- DTD 和 xml(標准化越來越近了) 模式注冊在 XML(標准化越來越近了) 模式存儲庫(XSR)中,並存儲在數據庫中。
查詢和發布
使用 SQL/xml(標准化越來越近了) 和 XML(標准化越來越近了) Extender 函數進行查詢和發布。
對於原樣的 XML(標准化越來越近了) 文檔。
- 使用帶索引的副表查詢文檔,以 CLOB 形式獲得文檔。
- 可以使用 XML(標准化越來越近了) Extender 函數進行子文檔查詢。
可以使用 Extender 函數進行 XSLT 轉換。
對於分解到關系表的 XML(標准化越來越近了) 數據。
- XML(標准化越來越近了) Extender DAD 映射和函數。
使用 SQL/XML(標准化越來越近了) 和 XQuery 進行查詢和發布。
對於原樣的 XML(標准化越來越近了) 文檔。
- 可以混合使用 SQL/xml(標准化越來越近了) 和 XQuery 來檢索和發布關系數據和 XML(標准化越來越近了) 數據。
使用 XML(標准化越來越近了) Extender XSLT 函數支持 XSLT。
- 可以使用 XQuery 查詢、轉換和發布 XML(標准化越來越近了)。
對於分解到關系表的 XML(標准化越來越近了) 數據。
更新
對於原樣的 XML(標准化越來越近了) 文檔。
- 使用 XML(標准化越來越近了) Extender UDF update 進行更新。
對於原樣的 XML(標准化越來越近了) 文檔。
- 由於缺少定義 XQuery 更新的標准,不支持子文檔更新。
- 可以從 developerWorks 下載更新存儲過程,請參考 xml(標准化越來越近了) application migration from DB2 8.x to DB2 Viper, Part 1: Partial updates to XML(標准化越來越近了) documents in DB2 Viper (developerWorks,2006 年 5 月)。
為數據庫啟用 XML(標准化越來越近了) 功能
需要為數據庫啟用 XML(標准化越來越近了) Extender 功能。
不需要啟用數據庫,因為 XML(標准化越來越近了) 支持現在是 DB2 引擎的固有部分。
工具
在 DB2 Development Center 或 Control Center 中沒有集成 XML(標准化越來越近了) 支持。
Websphere Studio Application Developer
- XML(標准化越來越近了) Schema Editor
- 在查詢構建器中不支持 SQL XML(標准化越來越近了)。
- Java Database Connectivity(JDBC)驅動程序中沒有提供支持。
XML(標准化越來越近了) 支持集成到了工具的各個方面。
DB2 Control Center 和 DB2 Developers Workbench(基於 Eclipse)。
- XML(標准化越來越近了) Schema Editor
- 用於帶注釋的 XML(標准化越來越近了) 模式映射的映射工具
- 在查詢構建器中支持 SQL/XML(標准化越來越近了) 函數。
- Visual Studio .Net 增加了對 DB2 XML(標准化越來越近了) 的支持
DB2 版本
DB2 UDB Version 7.x 和 DB2 UDB Version 8.x
DB2 z/OS Version 7 和更高版本(V8)
iSerIEs V5R1 和更高版本(V5R3)
DB2 Viper
AIX、NT、Linux、SOLARIS 注意: 數據庫中緊密集成了 XQuery 引擎,支持本機 XML(標准化越來越近了) 存儲,因此能夠獲得 SQL 和 XQuery 兩者的查詢執行計劃。
DB2 UDB Viper 中引入的 XML(標准化越來越近了) 特性
在開始一步步地遷移示例應用程序之前,先簡要地看看 DB2 UDB Viper 的 XML(標准化越來越近了) 支持。
XML(標准化越來越近了) 數據的存儲
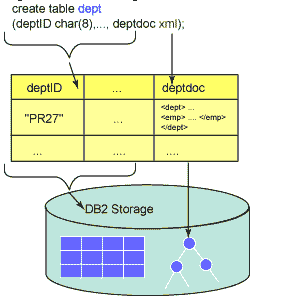
在與 DB2 的本機 xml(標准化越來越近了) 支持進行交互時,圖 1 中所示的抽象是關系表中一個 xml(標准化越來越近了) 類型的列。任何良構的 XML(標准化越來越近了) 文檔都可以插入這個列。在物理存儲層,主存儲單元是一個節點。
對於同時包含關系列和 xml(標准化越來越近了) 列的表,關系列存儲為關系格式,XML(標准化越來越近了) 列存儲為經過解析的樹。
圖 1. 與 DB2 的本機 XML(標准化越來越近了) 支持進行交互
 XML(標准化越來越近了) 索引
XML(標准化越來越近了) 索引
xml(標准化越來越近了) 索引是一種新型索引,可以高效地計算 xml(標准化越來越近了) 路徑表達式,從而提高查詢 XML(標准化越來越近了) 文檔的性能。
xml(標准化越來越近了) 索引使用一個 xml(標准化越來越近了)PATTERN(沒有謂詞的 XPath,只有一個子軸(/)和後代或本身軸(//))來對一個 xml(標准化越來越近了) 列中存儲的 xml(標准化越來越近了) 文檔的路徑和值建立索引。在創建索引時,可以指定要為什麼路徑建立索引以及類型。在此列中存儲的 XML(標准化越來越近了) 中,與路徑表達式或路徑表達式集合匹配的任何節點都被索引。索引直接指向存儲中的節點,節點與它的父節點和子節點鏈接,便於快速導航。
create index idx3 on dept(deptdoc) generate key using
XML(標准化越來越近了)pattern '/dept/employee/name' as sql varchar(35);
XML(標准化越來越近了) 模式存儲庫 XSR 是一個存儲庫,存儲著用來驗證和處理 xml(標准化越來越近了) 列中存儲的 xml(標准化越來越近了) 實例文檔的所有 XML(標准化越來越近了) 工件。XSR 避免了定位外部文檔所需的額外開銷以及可能產生的性能影響。每個數據庫的數據庫編目中包含一個 xml(標准化越來越近了) 模式存儲庫,並包含編目表、編目視圖和一些系統定義的存儲過程(用於進行注冊)以便將數據輸入這些編目表。XML(標准化越來越近了) 模式、DTD 和外部實體必須顯式地在 XSR 中注冊,然後才能使用。
帶注釋的模式映射
DB2 Viper 使用帶注釋的 xml(標准化越來越近了) 模式提供一種新的分解機制。並不創建單獨的映射文件(DAD),而是用關系映射信息對 xml(標准化越來越近了) 模式進行注釋。然後,將這些帶注釋的模式注冊到 XSR。在運行時使用它們對要插入列中的 xml(標准化越來越近了) 文檔進行分解。分解的 xml(標准化越來越近了) 值的數據類型是標准關系類型。可以使用關系索引技術為分解的關系列創建索引。更多信息請參考 “From DAD to annotated XML(標准化越來越近了) schema decomposition” (developerWorks,2006 年 4 月)。
圖 2 給出一個帶注釋的模式映射示例。它展示整個 xml(標准化越來越近了) 文檔以及從 XML(標准化越來越近了) 文檔提取出的數據如何存儲在同一個記錄中。
圖 2. 帶注釋的模式映射
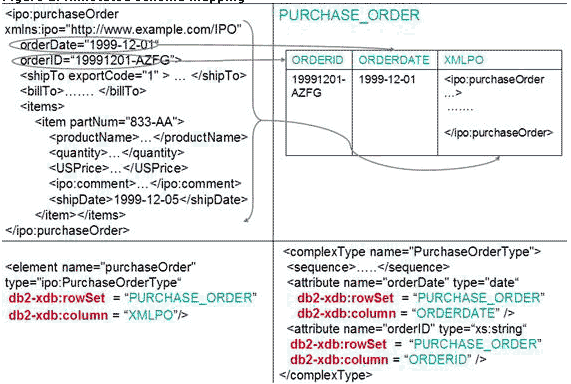
原樣的 xml(標准化越來越近了) 文檔存儲在 xml(標准化越來越近了)PO 列(XML(標准化越來越近了) 類型)中,提取出的 orderID 存儲在 ORDERID 列(VARCHAR)中,orderDate 存儲在 ORDERDATE 列(DATE)中。
SQL/XML(標准化越來越近了) 函數
XML(標准化越來越近了) 發布函數
文檔構造過程就是用元素和屬性這樣的小塊內容組合出 xml(標准化越來越近了) 值。SQL/xml(標准化越來越近了) 為這個過程提供了幾個函數,可以從關系數據構造出 XML(標准化越來越近了) 文檔。
DB2 UDB Version 8.x 中有以下這些用來發布的 SQL/XML(標准化越來越近了) 函數:
xml(標准化越來越近了)AGG: 以提供的 xml(標准化越來越近了) 值作為輸入,返回所有非空的輸入 XML(標准化越來越近了) 值的連結。xml(標准化越來越近了)ATTRIBUTES: 生成被構造的 XML(標准化越來越近了) 元素的屬性。xml(標准化越來越近了)CONCAT: 連結非空的 xml(標准化越來越近了) 類型的輸入表達式,返回一個 XML(標准化越來越近了) 值序列。xml(標准化越來越近了)ELEMENT: 根據輸入參數構造一個 XML(標准化越來越近了) 元素。xml(標准化越來越近了)FOREST: 從輸入參數構建一個 XML(標准化越來越近了) 元素林。xml(標准化越來越近了)NAMESPACES: 為由 xml(標准化越來越近了)ELEMENT 或 XML(標准化越來越近了)FOREST 生成的元素構造名稱空間聲明。xml(標准化越來越近了)2CLOB 和 xml(標准化越來越近了)SERIALIZE: xml(標准化越來越近了) 串行化函數將 XML(標准化越來越近了) 值轉換為一個字符串值。
圖 3. DB2 UDB V8.x 中的 SQL/XML(標准化越來越近了) 發布函數

DB2 Viper 支持 DB2 V8 中的所有 SQL/xml(標准化越來越近了) 函數(並接受或返回新的 XML(標准化越來越近了) 類型)。
還支持以下這些新的 SQL/XML(標准化越來越近了) 發布函數:
XML(標准化越來越近了)COMMENT: 生成一個 XQuery 注釋節點。XML(標准化越來越近了)PI: 生成一個 XQuery 處理指令節點。XML(標准化越來越近了)TEXT: 生成一個 XQuery 文本節點。XML(標准化越來越近了)DOCUMENT: 生成一個 XQuery 文檔節點。
下面是用於 IN/OUT 和驗證的新的 SQL/XML(標准化越來越近了) 函數:
xml(標准化越來越近了)PARSE: 對字符/BLOB 數據進行解析,並生成 XML(標准化越來越近了) 值。xml(標准化越來越近了)CAST: 轉換為 XML(標准化越來越近了) 類型,或者相反。xml(標准化越來越近了)VALIDATE: 針對 xml(標准化越來越近了) 模式和類型驗證 xml(標准化越來越近了) 值,並給 XML(標准化越來越近了) 值加注釋。IS VALIDATED: 檢查 XML(標准化越來越近了) 值是否已經經過驗證。
XML(標准化越來越近了)PARSE
可以使用 SQL/xml(標准化越來越近了) 函數 xml(標准化越來越近了)PARSE 將表示 xml(標准化越來越近了) 文檔的字符串值轉換為 DB2 xml(標准化越來越近了) 類型。這個函數接受一個串行化的 xml(標准化越來越近了) 文檔,將它轉換為 xml(標准化越來越近了) 類型的實例。當需要改變默認的解析選項時,使用 xml(標准化越來越近了)PARSE。使用 xml(標准化越來越近了)PARSE 會使系統 “忘記” 正在處理 xml(標准化越來越近了) 數據,因為 XML(標准化越來越近了)PARSE 的輸入是一個字符串或二進制類型。
insert into customer (cid, info) values (?,XML(標准化越來越近了)PARSE(
DOCUMENT cast(? as BLOB(2M)) preserve whitespace ))
XML(標准化越來越近了)CAST
這個偽函數將 xml(標准化越來越近了) 值轉換為非 xml(標准化越來越近了) 數據類型,或者將非 xml(標准化越來越近了) 值轉換為 xml(標准化越來越近了) 值。例如,它將 SQL/xml(標准化越來越近了) 值轉換為 SQL 數據類型。它支持轉換為 SQL 標量類型的子集。假設轉換的源來自 XML(標准化越來越近了) 模式原子類型或無類型文本,或者是值為原子類型或無類型文本的節點。
values(xml(標准化越來越近了)CAST(XML(標准化越來越近了)QUERY('$m/customer/@cid' PASSING
XML(標准化越來越近了)parse(document 'hardeep
singh') AS "m") AS INTEGER) )
XML(標准化越來越近了)Validate
xml(標准化越來越近了)Validate 函數接受一個 xml(標准化越來越近了) 值並針對一個 xml(標准化越來越近了) 模式驗證它,返回一個用 xml(標准化越來越近了) 模式中定義的默認值和類型注釋生成的 xml(標准化越來越近了) 值。對於本機 xml(標准化越來越近了) 列,沒有列級的 xml(標准化越來越近了) 模式驗證。驗證必須顯式地添加到每個 insert 或 update 語句中。這允許將來自不同 xml(標准化越來越近了) 模式的 XML(標准化越來越近了) 文檔保存在相同的列中。
注意: 不支持針對 DTD 進行驗證。DTD 只用來添加默認值和解析實體引用。
insert into purchaSEOrders (pid,porders) values (2, XML(標准化越來越近了)Validate(?))
Is validated
is validated 謂詞可以用來檢查 xml(標准化越來越近了) 數據是否已經經過驗證。它用於檢查約束和在 WHERE 子句中對行進行過濾,而且不會受到用來驗證的 XML(標准化越來越近了) 模式的影響。
Alter table purchaSEOrders add constraint XML(標准化越來越近了)_check check
(pOrder is validated))
Select pOrder from purchaSEOrders where pOrder is validated
XML(標准化越來越近了)SERIALIZE
xml(標准化越來越近了) 值在處理時采用一種內部表示方式,這不是字符串,也不能直接與字符串值進行比較。可以使用 xml(標准化越來越近了)SERIALIZE 函數將 xml(標准化越來越近了) 值轉換為表示 xml(標准化越來越近了) 文檔的串行化字符串值。在 DB2 驅動程序不支持 XML(標准化越來越近了) 類型的環境中,這個函數非常有用。
xml(標准化越來越近了)SERIALIZE 函數返回一個從 xml(標准化越來越近了) 表達式參數生成的指定數據類型的串行化 xml(標准化越來越近了) 值。結果的數據類型由用戶指定。如果 xml(標准化越來越近了) 表達式的結果是空的,那麼函數的結果是空值。返回的串行化 XML(標准化越來越近了) 值必須小於 2GB。串行化結果用 UTF-8 進行編碼。
SELECT XML(標准化越來越近了)SERIALIZE ( CONTENT
XML(標准化越來越近了)ELEMENT ( NAME "customer",
XML(標准化越來越近了)ATTRIBUTES (e.cid AS "id"),
XML(標准化越來越近了)ELEMENT (NAME "name", e.name),
XML(標准化越來越近了)ELEMENT (NAME "email", e.email),
XML(標准化越來越近了)ELEMENT (NAME "zip", e.zip))
AS CLOB(7200)) AS CINFO FROM customer e where cid=1000
下面是用來查詢 xml(標准化越來越近了) 數據的新的 SQL/XML(標准化越來越近了) 函數和謂詞:
XML(標准化越來越近了)TABLE: 執行一個 XQuery,將結果序列作為關系表返回。XML(標准化越來越近了)EXISTS: 判斷一個 XQuery 是否返回一個或多個項。XML(標准化越來越近了)QUERY: 執行一個 XQuery 並返回結果序列。xml(標准化越來越近了)TABLE 從 XML(標准化越來越近了) 文檔構造一個表 xml(標准化越來越近了)TABLE 提供了從 xml(標准化越來越近了) 文檔發布關系數據的標准方式。它查詢 xml(標准化越來越近了) 值並返回一個關系結果集(將 XML(標准化越來越近了) 數據分解為關系形式)。創建一個虛擬表作為分解的結果,可以使用 SQL insert 語句將這個表插入現有的 SQL 表。
XML(標准化越來越近了)TABLE 允許指定生成的關系的形態(列的數量和數據類型)。XQuery 參數決定行實例和每列的值的生成。
圖 4. XML(標准化越來越近了)TABLE 查詢

圖 4 所示的查詢接受輸入的 xml(標准化越來越近了) 文檔(product)並從其中分解出 @pid 和根節點。然後將這些存儲進 XML(標准化越來越近了)PRODUCT 表中。
表 2. 帶注釋的 xml(標准化越來越近了) 模式分解和 XML(標准化越來越近了)TABLE 之間的差異
帶注釋的 XML(標准化越來越近了) 模式分解
xml(標准化越來越近了)TABLE(SQl/XML(標准化越來越近了))
類型映射
靜態映射信息在 XML(標准化越來越近了) 模式中注釋並在注冊時啟用,不需要在運行時向應用程序公開(隱式)。
動態映射信息作為 SQL 查詢的一部分。實際上,映射在運行時顯式地定義並向應用程序公開。
XML(標准化越來越近了) 模式
需要一個 xml(標准化越來越近了) 模式,而且這個 XML(標准化越來越近了) 模式必須在 XSR 中注冊。
不需要一個 XML(標准化越來越近了) 模式。
目標關系表必須存在?
是的。
在運行時創建虛擬表。
支持多個表?
是的。一個 XML(標准化越來越近了) 文檔可以映射到多個關系表。
不行。只能創建一個可以在 SQL 語句中引用的虛擬表。
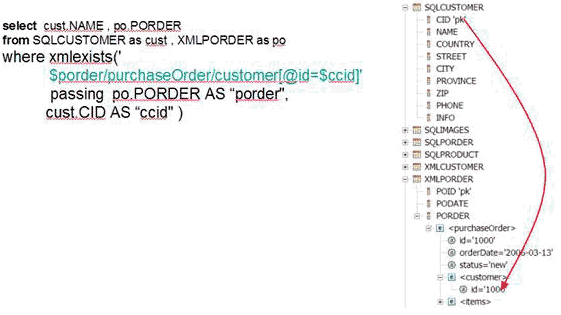
XML(標准化越來越近了)QUERY
xml(標准化越來越近了)QUERY 是一個 SQL/xml(標准化越來越近了) 發布(偽)函數,它的用途是計算一個 XQuery 表達式並向應用程序返回一個 XML(標准化越來越近了) 值,這個值可以是包含零個或更多項的 XQuery 序列。
圖 5. XML(標准化越來越近了)QUERY 查詢
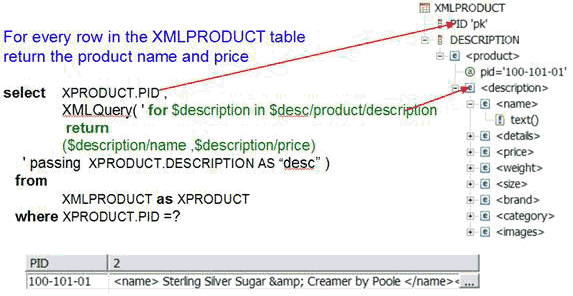
圖 5 所示的查詢只返回 xml(標准化越來越近了)PRODUCT 表中每一行的 DESCRIPTION 列中存儲的 XML(標准化越來越近了) 數據的一些元素。
XML(標准化越來越近了)EXISTS xml(標准化越來越近了)EXISTS 謂詞使用 XQuery 查詢一個 SQL/XML(標准化越來越近了) 值。如果查詢返回非空的序列,那麼函數返回 true;否則返回 false。
圖 6. XML(標准化越來越近了)EXISTS 查詢
 DB2 Viper 的 xml(標准化越來越近了) 支持對基於 XML(標准化越來越近了) 的應用程序的影響
DB2 Viper 的 xml(標准化越來越近了) 支持對基於 XML(標准化越來越近了) 的應用程序的影響
應用程序的設計會受到 xml(標准化越來越近了) 數據的存儲模型(原樣或分解)的影響。存儲模型受到存儲、查詢和修改 xml(標准化越來越近了) 數據方面的功能限制和任何性能需求的影響。隨著新功能的引入,DB2 xml(標准化越來越近了) Extenders 的許多限制已經被消除了,因此 XML(標准化越來越近了) 存儲模型可以改變了。
本文的其余部分詳細描述處理 XML(標准化越來越近了) 數據的 DB2 功能之間的差異。還討論如何將現有的應用程序遷移到 DB2 Viper 以便使用新的特性集。
設置數據庫 您可能會注意到,為數據庫設置 XML(標准化越來越近了) 支持所需的一些步驟已經改變了。
表 3. DB2 V8.x 和 DB2 Viper 數據庫設置之間的差異
DB2 UDB Version 8.x
DB2 Viper
創建數據庫
也支持非 UTF-8 數據庫使用 XML(標准化越來越近了) 數據。
為創建數據庫,發出 create db migrate 命令。
只支持 UTF-8 數據庫使用 XML(標准化越來越近了) 數據。
為創建 UTF-8 數據庫,發出 create db migrate using codeset utf-8 territory us 命令。
為數據庫啟用 XML(標准化越來越近了)
需要通過發出 dxxadm enable_db migrate 命令為每個數據庫啟用 XML(標准化越來越近了) Extender 支持。
XML(標准化越來越近了) 支持是 UTF-8 數據庫固有的功能。
安裝進行驗證所需的任何 DTD 或 XML(標准化越來越近了) 模式
用來進行驗證的所有 XML(標准化越來越近了) 模式位於文件系統中,不進行注冊。
用來進行驗證的任何 DTD 需要注冊並存儲在數據庫的特殊表 DTD_REF 中。
用來進行驗證的所有 XML(標准化越來越近了) 模式需要注冊在 XSR 中。
DTD 不能用於驗證,所以在大多數情況下 DTD 必須改為 XML(標准化越來越近了) 模式(仍然可以將它們注冊在 XSR 中,因為它們可以用於實體引用和默認值)。
創建 XML(標准化越來越近了) 到關系數據的映射
原樣存儲(xml(標准化越來越近了) 作為 xml(標准化越來越近了) CLOB 存儲在一個列中)和分解存儲(xml(標准化越來越近了) 中的數據分解存儲到關系表中)都需要 XML(標准化越來越近了) 到關系數據的映射。
使用專用的映射形式,DAD。
只有分解存儲需要 xml(標准化越來越近了) 到關系數據的映射。使用更標准且高效的映射技術,帶注釋的 XML(標准化越來越近了) 模式映射。
注冊並啟用映射
存儲原樣 xml(標准化越來越近了) 的 xml(標准化越來越近了) 列需要使用 DAD 映射來啟用,從而創建更新與此列相關聯的副表所需的觸發器。啟用 xml(標准化越來越近了) 列的命令是:db2XML(標准化越來越近了).dxxEnableColumn。
DAD 映射定義如何將 xml(標准化越來越近了) 文檔分解為關系表集合(xml(標准化越來越近了) 集合),可以注冊 DAD 映射並允許在 xml(標准化越來越近了) Extender 分解函數中使用。啟用 xml(標准化越來越近了) 集合的命令是:db2XML(標准化越來越近了).dxxEnableCollection。
xml(標准化越來越近了) 類型的列(存儲本機 XML(標准化越來越近了) 數據)沒有任何相關聯的映射,不需要啟用。
帶注釋的 xml(標准化越來越近了) 模式定義如何將 XML(標准化越來越近了) 文檔分解為關系表,需要將它們注冊在 XSR 中並啟用分解。這可以在注冊時進行:
COMPLETE XML(標准化越來越近了) SCHEMA PRODSCHEMA ENABLE DECOMPSITION
也可以在已經注冊 XML(標准化越來越近了) 模式之後啟用:
ALTER XSROBJECT PRODSCHEMA ENABLE DECOMPOSITION
在 XML(標准化越來越近了) 文檔上創建索引
對於 xml(標准化越來越近了) 列中的原樣文檔,可以建立間接索引,辦法是:將 XML(標准化越來越近了) 文檔中的部分數據分解到輔助(副)關系表中,然後為這些表創建索引,從而對分解的數據進行快速搜索。
注意: 實際上,這些映射定義 XML(標准化越來越近了) 列上的模式種類,如果輸入文檔的形態改變了,那麼需要修改映射信息和副表。
以本機方式存儲在 xml(標准化越來越近了) 列中的 xml(標准化越來越近了) 文檔可以建立 xml(標准化越來越近了) 索引。這些索引直接定位經過解析的樹中的存儲節點(而不是文檔)。這種 XML(標准化越來越近了) 索引是 DB2 Viper 中引入的新概念。
注意: 因為索引不與任何模式或映射相關聯,如果模式改變了,那麼可以定義新索引,而不必刪除現有索引。 為了了解遷移過程,先來看看在 DB2 Version 8.x 和 DB2 Viper 中創建能夠存儲 XML(標准化越來越近了) 數據的數據庫的一些基本步驟。
- 創建數據庫並啟用 XML(標准化越來越近了) 支持。
DB2 Version 8.x
db2 create db MIGRATE
dxxadm ENABLE_DB MIGRATE
DB2 Viper
db2 create db MIGRATE using codeset utf-8 territory us
- 注冊 DTD/XML(標准化越來越近了) 模式
DB2 Version 8.x。只能注冊 DTD。
insert into db2XML(標准化越來越近了).dtd_ref (dtdid, content, usage_count, author,
creator, updator) values ( 'customerdtd', db2xml(標准化越來越近了).XML(標准化越來越近了)CLOBFromFile(
'/home2/hardeep/migrate/customer.dtd'), 0, 'xml(標准化越來越近了)', 'xml(標准化越來越近了)', 'XML(標准化越來越近了)');
DB2 Viper。只能使用 XML(標准化越來越近了) 模式進行驗證。
db2 register XML(標准化越來越近了)schema http://migrate.db2 from
/home2/hardeep/migrate/customer.xsd as migrate.customer
db2 complete XML(標准化越來越近了)schema migrate.customer
- 創建表和存儲 XML(標准化越來越近了) 數據的列
DB2 Version 8.x。使用 xml(標准化越來越近了) Extender 數據類型 XML(標准化越來越近了)CLOB。
CREATE TABLE PurchaSEOrder ( POid BIGINT NOT NULL Prima(最完善的虛擬主機管理系統)RY KEY,
Info DB2xml(標准化越來越近了).XML(標准化越來越近了)CLOB)
注意: 列的類型可以是 xml(標准化越來越近了)CLOB、xml(標准化越來越近了)VARCHAR 和 XML(標准化越來越近了) FILE。
DB2 Viper。XML(標准化越來越近了) 類型的列。
CREATE TABLE PurchaSEOrder ( POid BIGINT NOT NULL Prima(最完善的虛擬主機管理系統)RY KEY,
Info XML(標准化越來越近了))
注意: 與 xml(標准化越來越近了)CLOB、xml(標准化越來越近了)VARCHAR 和 xml(標准化越來越近了) FILE 不同,XML(標准化越來越近了) 類型是一個標准的 SQL 類型。
- 在 XML(標准化越來越近了) 數據上創建索引。
DB2 Version 8.x。創建 DAD 映射並啟用 XML(標准化越來越近了) 列以便在副表上創建間接索引。
dxxadm enable_column migrate purchaSEOrder info
"/home2/hardeep/migrate/po.dad" -r poid
DB2 Viper。使用 xml(標准化越來越近了)pattern 創建 XML(標准化越來越近了) 索引。
create unique index order_key on purchaSEOrder (info) generate key
using XML(標准化越來越近了)pattern '/purchaSEOrder/@poid' as sql double;
- 創建將輸入的 XML(標准化越來越近了) 分解為關系數據的映射
DB2 Version 8.x。創建 DAD 映射並啟用 XML(標准化越來越近了) 集合。
dxxadm enable_collection migrate customerinfo
/home2/hardeep/migrate/customer.dad
DB2 Viper。對 XML(標准化越來越近了) 模式進行注釋並啟用它。
db2 register XML(標准化越來越近了)schema http://migrate.db2 from
/home2/hardeep/migrate/customer.xsd as migrate.customer
db2 complete XML(標准化越來越近了)schema migrate.customer ENABLE DECOMPOSITION
將現有的 XML(標准化越來越近了) 數據庫從 DB2 Version 8.x 遷移到 DB2 Viper
既然對數據庫設置方式的差異有了一些理解,就來看看將現有的 XML(標准化越來越近了) 數據庫從 DB2 Version 8.x 遷移到 DB2 Viper 所需的基本步驟。
為 DB2 Viper 創建新的 UTF-8 數據庫
首先需要理解的是,因為只支持對 XML(標准化越來越近了) 數據使用 UTF-8 編碼,所以如果現有的數據庫是非 UTF-8 的,那麼需要用 UTF-8 編碼頁集創建一個新數據庫。
使用以下命令創建新數據庫:
db2 create db migrate using codeset utf-8 territory us
接下來,需要將所有數據庫對象從原數據庫導出,然後將它們導入新數據庫(UTF-8)。這是一個手工操作。本文只討論與 XML(標准化越來越近了) 數據相關聯的 DB2 對象的遷移過程,其余部分請參閱 DB2 遷移文檔。
本文提供了一個遷移實用程序。它可以幫助您生成遷移數據庫對象所需的一些數據定義語言(DDL)腳本。
遷移 DTD 和 XML(標准化越來越近了) 模式
因為 DB2 Viper 不使用 DTD 進行 xml(標准化越來越近了) 驗證,所以必須將當前 xml(標准化越來越近了) 應用程序使用的任何 DTD 轉換為 XML(標准化越來越近了) 模式。為此,首先需要將 DTD 從現有的 DB2 Version 8.x 數據庫(DTD_REF 表)裝載到本地文件系統中。
select db2xml(標准化越來越近了).xml(標准化越來越近了)FileFromCLOB(db2XML(標准化越來越近了).clob(content),
'/home2/hardeep/migrate/customer.dtd') from db2XML(標准化越來越近了).dtd_ref where DTDID='customerdtd';
注意: 因為 XML(標准化越來越近了) 模式並不保存在數據庫中,可以從文件系統獲得它們。
將 DTD 從 DTD_REF 表復制到文件系統之後,需要將它轉換為 xml(標准化越來越近了) 模式。有許多免費的基於 Web 的 xml(標准化越來越近了) 實用工具可以幫助您在 DTD 和 XML(標准化越來越近了) 模式之間進行轉換(使用關鍵詞 DTD Schema convert 進行搜索)。
注冊 XML(標准化越來越近了) 模式
為了使用 xml(標准化越來越近了) 模式驗證 xml(標准化越來越近了) 文檔,首先需要在 XML(標准化越來越近了) 模式存儲庫中注冊它們。
db2 register XML(標准化越來越近了)schema http://migrate.db2 from
/home2/hardeep/migrate/po.xsd as migrate.po
db2 complete XML(標准化越來越近了)schema migrate.po
注意:大型模式需要在應用程序堆中有足夠的空間。
db2 update db cfg using applheapsz 1000
將包含 XML(標准化越來越近了) 數據的表遷移到新數據庫
在 DB2 Version 8.x 中,為了存儲原樣的 xml(標准化越來越近了) 文檔,列的類型可以是 CLOB、BLOB、VARCHAR 或 xml(標准化越來越近了) Extender 類型 DB2xml(標准化越來越近了).xml(標准化越來越近了)CLOB、DB2xml(標准化越來越近了).xml(標准化越來越近了)VARCHAR 或 DB2xml(標准化越來越近了).xml(標准化越來越近了)FILE。對於 DB2 Viper,列類型是 XML(標准化越來越近了)。
因此,在 DB2 Version 8.x 中可以用下面的命令創建包含 CLOB 列的表來存儲 XML(標准化越來越近了) 數據
CREATE TABLE Product(Pid VARCHAR(10) NOT NULL Prima(最完善的虛擬主機管理系統)RY KEY,
Name VARCHAR(128), Category VARCHAR(32),Price DECIMAL(30,2), Info CLOB);
而在 DB2 Viper 中應該創建 xml(標准化越來越近了) 列來存儲 XML(標准化越來越近了) 數據:
CREATE TABLE Product(Pid VARCHAR(10) NOT NULL Prima(最完善的虛擬主機管理系統)RY KEY,
Name VARCHAR(128), Category VARCHAR(32),
Price DECIMAL(30,2), Info XML(標准化越來越近了));
注意: 在上面的表中,如果 NAME、CATEGORY 和 PRICE 列中的數據是從 xml(標准化越來越近了) 文檔中提取的(為了創建關系索引),那麼新表就根本不需要這些列,因為現在可以在存儲的 XML(標准化越來越近了) 文檔本身上創建索引。這個表可以簡化為兩列。
CREATE TABLE Product(Pid VARCHAR(10) NOT NULL Prima(最完善的虛擬主機管理系統)RY KEY, Info XML(標准化越來越近了));
在 DB2 Version 8.x 中創建的 DB2xml(標准化越來越近了).XML(標准化越來越近了)CLOB 列:
CREATE TABLE PurchaSEOrder(Poid BIGINT NOT NULL Prima(最完善的虛擬主機管理系統)RY KEY,
Status VARCHAR(10) NOT NULL WITH DEFAULT 'New',
Info DB2xml(標准化越來越近了).XML(標准化越來越近了)CLOB NOT LOGGED NOT COMPACT NOT NULL);
現在也成為 XML(標准化越來越近了) 列:
CREATE TABLE PurchaSEOrder(Poid BIGINT NOT NULL Prima(最完善的虛擬主機管理系統)RY KEY,
Status VARCHAR(10) NOT NULL WITH DEFAULT 'New', Info XML(標准化越來越近了) NOT NULL);
將 XML(標准化越來越近了) 數據從 DB2 Version 8.x 遷移到 DB2 Viper 在新數據庫中創建所有的表之後,下一步是將數據導出原數據庫(DB2 Version 8.x)表並導入新數據庫(DB2 Viper)表。為了更好地理解這個過程,我們看看 DB2 Viper 的導入實用程序如何處理 XML(標准化越來越近了) 數據。
DB2 IMPORT 實用程序提供了用來自 xml(標准化越來越近了) 文件的數據填充 xml(標准化越來越近了) 列的簡便方法。這個實用程序使用一個分界的 ASCII 文件,其中包含的一個參數指定需要導入的每個 xml(標准化越來越近了) 文件。按照約定,這個文件的擴展名是 .DEL。文件中的每一行代表要導入表中的一行數據。如果一行包含 xml(標准化越來越近了) Data SpecifIEr(XDS),那麼 IMPORT 讀取引用的 XML(標准化越來越近了) 文件中的數據並將其導入 DB2。
從 DB2 Version 8.x 導出 XML(標准化越來越近了) 數據
因為 DB2 Version 8.x 的 EXPORT 實用程序不生成帶 XDS 的 .DEL 文件,DB2 Viper 的 IMPORT 實用程序也可以處理 DB2 Version 8.x 的 EXPORT 實用程序為大對象(LOB)創建的 .DEL 文件。
所以,對於 CLOB、BLOB、VARCHAR、DB2xml(標准化越來越近了).xml(標准化越來越近了)CLOB、DB2xml(標准化越來越近了).xml(標准化越來越近了)VARCHAR 或 DB2xml(標准化越來越近了).xml(標准化越來越近了)FILE 類型的列中存儲的 xml(標准化越來越近了) 數據,第一步是使用 EXPORT 和 LOB 選項導出包含 XML(標准化越來越近了) 數據的表。
EXPORT TO delfilename, OF DEL LOBS to lobfilespath MODIFIED BY
LOBSINFILE select statement
注意: 如以下例子所示,lobfilespath 路徑應該是存在的,delfilename 應該有完整的路徑,這個路徑也應該存在。
DB2 EXPORT to C:/temp/migration/export/prod.del of del LOBS
to C:/temp/migration/export/lobs modifIEd by LOBSINFILE
select pid,name,category,price,Info from product
注意: 在進行調用之前,路徑 C:/temp/migration/export/lobs 應該已經存在。
注意: 如果從新表中去掉了 name、category 和 price 列,那麼應該修改 select 語句,只選擇 pid 和 info 列。
這個調用的輸出生成一個 prod.del 文件和一個或多個包含 XML(標准化越來越近了) 數據的 lob 文件。
100-100-01,Denim Roll Cuff Crop Pants,pants,+024.89,prod.del.001.lob.0.474/
100-100-02,Bermuda Shorts,shorts,+09.99,prod.del.001.lob.474.488/
重點: 如果 xml(標准化越來越近了) 數據的列類型是 VARCHAR,那麼需要在 select 語句中將這個列轉換為 CLOB,以防止 XML(標准化越來越近了) 數據被放在 DEL 文件中。
DB2 export to C:/temp/migration/export/prod.del of del LOBS
to C:/temp/migration/export/lobs modifIEd by LOBSINFILE
select pid,name,category,price,cast(Info as clob) from product
cast (Info as clob) 確保 XML(標准化越來越近了) 數據導出到 lob 文件,而不是添加到分界的(DEL)文件中。
如果沒有轉換這個列,那麼輸出會像下面這樣:
100-100-01,Denim ,pants,+024.89,
100-100-02,Bermuda ,shorts,+09.99,
IMPORT 命令無法處理這種格式,因為它認為這是非良構的 XDS。
將 XML(標准化越來越近了) 數據導入 DB2 Viper
現在可以使用 IMPORT 實用程序將導出的數據導入新數據庫中創建的表中。傳遞 DEL 文件的名稱和 LOB 文件的路徑。
DB2 IMPORT FROM C:/temp/migration/export/prod.del OF DEL LOBS FROM
C:/temp/migration/export/lobs MODIFIED BY XML(標准化越來越近了)CHAR INSERT INTO product;
注意: 對於分解到關系列的 XML(標准化越來越近了) 數據,不需要遷移數據。
遷移 XML(標准化越來越近了) 數據上的索引
在 DB2 Version 8.x 中,xml(標准化越來越近了) 列中存儲的 xml(標准化越來越近了) 數據可以利用關系副表建立間接索引。將副表中的值與 XML(標准化越來越近了) 列中的文檔關聯起來的映射信息在 DAD 文件中定義。
由於 DB2 Viper 能夠創建直接定位 xml(標准化越來越近了) 文檔內部的路徑的 xml(標准化越來越近了) 索引,所以不再需要使用副表來建立間接關系索引。用來創建 xml(標准化越來越近了) 索引的一些關鍵參數與 DAD 映射中的參數相似。可以使用 DAD 映射中這些參數的值來創建 xml(標准化越來越近了) 索引。現在來分析一個 DAD 映射示例,這個 DAD 映射用來為 DB2xml(標准化越來越近了).XML(標准化越來越近了)CLOB 類型的 purchaSEOrder 列創建副表。
path="/purchaSEOrder/shipTo/name" multi_occurrence="NO"/>
這個映射中關鍵的參數是 //column/@path 和 //column/@type。
在 DB2 Viper 中相應的 XML(標准化越來越近了) 索引是:
create index order_name on purchaSEOrder (info) generate key using
XML(標准化越來越近了)pattern '/purchaSEOrder/ shipTo/name' as SQL VARCHAR(128);
DAD 中的 //column/@path 值與 xml(標准化越來越近了) 索引中的 XML(標准化越來越近了)pattern 相同,DAD 中的 //column/@type 值與 SQL 類型相同。
另一個重要之處是根 ID,當用這個 DAD 文件在 DB2 Version 8.x 中啟用 XML(標准化越來越近了) 列時,這個值傳遞給 enable_column 調用。
dxxadm enable_column migrate purchaSEOrder info
"/home2/hardeep/migrate/po.dad" -r poid
這個根 ID 標識出表中一個主鍵的名稱,這個主鍵被添加到副表中,用來將副表與包含 xml(標准化越來越近了) 列的表關聯起來。根 ID 的值在 xml(標准化越來越近了) 列上是惟一的。這個根 ID 對應於 xml(標准化越來越近了) 文檔中的路徑值,惟一地定義 XML(標准化越來越近了) 列中的這個文檔。
所以,當為 DB2 Viper 創建 xml(標准化越來越近了) 索引時,可以在 DB2 Version 8.x 中定義根 ID(主鍵)的路徑上創建惟一索引(如果主鍵在 XML(標准化越來越近了) 文檔中存在的話)。
create unique index order_key on purchaSEOrder (info) generate key using
XML(標准化越來越近了)pattern '/purchaSEOrder/@poid' as sql double;
遷移用來將 XML(標准化越來越近了) 數據分解為關系數據的映射文件
如果應用程序需要將輸入的 xml(標准化越來越近了) 數據分解為關系表,而且您感覺這種需要仍然存在,那麼需要將現有的 DAD 映射替換為帶注釋的 XML(標准化越來越近了) 模式映射。
表 4. xml(標准化越來越近了) 集合和帶注釋的 XML(標准化越來越近了) 模式之間的差異
XML(標准化越來越近了) 集合
新的分解
映射文件
DAD
帶注釋的模式
功能和性能
有限
功能得到了擴展,性能更好
DTD/模式
不需要。可以注冊,也可以不注冊。
需要。必須注冊。 注意: 在這兩種映射中,關系表都必須提前存在。
因為關於 xml(標准化越來越近了) 文檔和關系模式之間關系的映射信息存儲在 DAD 文件中,可以利用這些 DAD 文件來了解 xml(標准化越來越近了) 模式所需的注釋。要想找到一種可以自動地將 DAD 文件轉換為帶注釋的 xml(標准化越來越近了) 模式的工具,請參考 From DAD to annotated XML(標准化越來越近了) schema decomposition (developerWorks,2006 年 4 月)。
對 XML(標准化越來越近了) 模式進行注釋之後,可以在 XSR 中注冊並啟用它們。
db2 register XML(標准化越來越近了)schema http://migrate.db2 from
/home2/hardeep/migrate/customer.xsd as migrate.customer
db2 complete XML(標准化越來越近了)schema migrate.customer ENABLE DECOMPOSITION
數據庫遷移實用程序
本文提供了一個遷移實用程序的示例代碼。這個實用程序生成幫助進行數據遷移的腳本。生成的腳本幫助執行以下步驟:
遷移命令
Migrate -p[path] -d[database] -s[schema] -t[able] -c[olumn] -[b[ackup]]
- path: 導出文件的目標目錄。
- database: 數據庫的名稱。
- schema: 模式的名稱。
- table: 要遷移的表的名稱。
- column: 表中 XML(標准化越來越近了) 列的名稱。
- backup: 表是否需要在遷移之前備份到一個備份模式中。
這個實用程序將腳本文件 migrate_script.db2 寫到當前目錄。
編譯 Java 代碼
為編譯 Java 代碼,需要完成以下步驟:
- 創建目錄 /temp/migrate。
- 將 MigrateUtility_code.zip(可以在本文的 下載 一節中找到)復制到 temp 目錄。將 Migrate.java 和 XML(標准化越來越近了)Parse.Java 解壓到 /temp/samples 目錄。
- 編譯 Java 文件。
在 Microsoft Windows 上: 打開一個 db2 命令窗口。
SET CLASSPATH= .;%DB2PATH%\java\db2Java.zip;
%DB2PATH%\java\db2jcc.jar;%DB2PATH%\Java\db2jcc_license_cu.jar;
"%DB2PATH%\java\jdk\bin\javac.exe" -d . *.Java
在 AIX 上: 將 DB2PATH 設置為 DB2 SQLLIB 目錄。
CLASSPATH=$DB2PATH/java/sqlj.zip:$DB2PATH/java/db2Java.zip
$DB2PATH/java/jdk/bin/javac.exe" -d . *.Java
注意: 以上命令假設采用 sh 或 bash shell。對於 csh、tsh 和其他 shell,請做適當的修改。
- 運行實用程序。
"%DB2PATH%\java\jdk\jre\bin\Java.exe" Migrate -p /temp/migrate
d migrate -s hardeep -t purchaSEOrder -c info -b XML(標准化越來越近了)extenderdata
下面是一個生成的腳本示例:
CONNECT TO MIGRATE;
-- Scripts to backup data to schema- XML(標准化越來越近了)extenderdata
CREATE SCHEMA XML(標准化越來越近了)extenderdata;
CREATE TABLE "XML(標准化越來越近了)extenderdata"."PURCHASEORDER"( "POID" BIGINT NOT NULL,
"STATUS" VARCHAR(10) NOT NULL WITH DEFAULT 'New' ,
"INFO" "DB2xml(標准化越來越近了)"."XML(標准化越來越近了)CLOB" NOT LOGGED NOT COMPACT NOT NULL)
IN "USERSPACE1";
DECLARE bcurs_purchaseorder CURSOR FOR SELECT * FROM hardeep.purchaSEOrder;
LOAD FROM bcurs_purchaSEOrder OF cursor INSERT INTO XML(標准化越來越近了)extenderdata.purchaSEOrder;
-- Scripts to migrate data
export to /temp/migrate purchaseorder/ purchaSEOrder.del of del lobs to
/temp/migrate purchaseorder/lobs modifIEd by LOBSINFILE SELECT * from purchaSEOrder;
drop table purchaSEOrder;
CREATE TABLE purchaSEOrder ( "POID" BIGINT NOT NULL ,
"STATUS" VARCHAR(10) NOT NULL WITH DEFAULT 'New' ,
"INFO" XML(標准化越來越近了) NOT NULL ) IN "USERSPACE1";
import from /temp/migrate/purchaseorder/purchaSEOrder.del of del lobs
from /temp/migrate/purchaSEOrder/lobs modifIEd by XML(標准化越來越近了)CHAR INSERT INTO purchaSEOrder;
ALTER TABLE purchaSEOrder ADD Prima(最完善的虛擬主機管理系統)RY KEY ("POID");
-- Scripts to restore data from backup schema- XML(標准化越來越近了)extenderdata schema
CONNECT TO MIGRATE;
drop table purchaSEOrder;
CREATE TABLE "HARDEEP "."PURCHASEORDER" ( "POID" BIGINT NOT NULL ,
"STATUS" VARCHAR(10) NOT NULL WITH DEFAULT 'New' ,
"INFO" "DB2xml(標准化越來越近了)"."XML(標准化越來越近了)CLOB" NOT LOGGED NOT COMPACT NOT NULL ) IN "USERSPACE1";
ALTER TABLE "HARDEEP "."PURCHASEORDER" ADD Prima(最完善的虛擬主機管理系統)RY KEY ("POID");
DECLARE rcurs_purchaSEOrder CURSOR FOR SELECT * FROM XML(標准化越來越近了)extenderdata.purchaSEOrder;
LOAD FROM rcurs_purchaseorder OF cursor INSERT INTO hardeep.purchaSEOrder;
遷移 DB2 查詢
DB2 Viper 可以混合使用 SQL/xml(標准化越來越近了) 和 XQuery 同時查詢關系數據和 XML(標准化越來越近了) 數據。
由於原來對 xml(標准化越來越近了) 文檔進行分解的一些原因已經不存在了(比如使用關系列進行快速搜索),存儲 xml(標准化越來越近了) 數據所需的關系模式可以大大簡化。因此,應用程序中處理 xml(標准化越來越近了) 數據的代碼現在可以由 DB2 查詢來替換,可以使用 SQL/XML(標准化越來越近了) 和 XQuery 在數據庫服務器中提供同樣的功能。這對應用程序處理 XML(標准化越來越近了) 數據的方式的影響是非常驚人的:
- SQL 查詢中嵌入的業務邏輯現在獨立於應用程序環境。另外,使用 SQL/XML(標准化越來越近了) 或 XQuery 編寫的業務邏輯可以存儲在視圖或存儲過程中,可供重用。
- 中間層更簡潔、更容易管理。
- 數據庫變成一個數據和服務提供者,從而簡化了面向服務的體系結構(SOA)。
- 數據在經過充分過濾之後才會離開數據庫,這會減少數據庫和應用程序之間的通信量。
受影響的一些應用程序查詢見 表 5:
表 5. 受影響的應用程序
DB2 UDB Version 8.x
DB2 Viper
插入
將 xml(標准化越來越近了) 文檔存儲到 DB2XML(標准化越來越近了) 列中的插入調用與存儲 CLOB 的插入調用相似:
insert into customer (info) values (?)
需要分解為關系表的 xml(標准化越來越近了) 文檔使用 XML(標准化越來越近了) Extender 分解函數:
dxxInsertxml(標准化越來越近了),dxxShredXML(標准化越來越近了)
插入調用仍然是一樣的,除非文檔需要進行驗證。XML(標准化越來越近了) 模式驗證調用需要顯式地添加到 insert 語句中。
insert into customer (info) values (XML(標准化越來越近了)Validate(?))
需要分解為關系表的 xml(標准化越來越近了) 文檔使用帶注釋的 xml(標准化越來越近了) 模式 decompose 函數或 SQL/xml(標准化越來越近了) XML(標准化越來越近了)TABLE 函數。
更新
對於原樣存儲的 xml(標准化越來越近了) 文檔(比如 xml(標准化越來越近了)Clob 類型的列),可以使用 xml(標准化越來越近了) Extender UDF db2XML(標准化越來越近了).update 進行子文檔更新。
這個 UDF 還同步更新對應的副表。
對於原樣存儲的 xml(標准化越來越近了) 文檔(比如 XML(標准化越來越近了) 類型的列),沒有開箱即用的子文檔更新函數。
可以在本系列的第一篇文章 Partial updates to XML(標准化越來越近了) documents in DB2 Viper (developerWorks,2006 年 5 月)中找到一個用於子文檔更新的 Java 存儲過程。
DB2xml(標准化越來越近了)FUNCTIONS.XML(標准化越來越近了)UPDATE
查詢
對於利用副表存儲在 xml(標准化越來越近了) Extender 列中的 xml(標准化越來越近了) 文檔,可以使用許多 XML(標准化越來越近了) Extender 提取函數來獲得子文檔數據。
對於存儲在 xml(標准化越來越近了) 列中的 xml(標准化越來越近了) 文檔,可以使用 XQuery 查詢 xml(標准化越來越近了) 文檔的內部。有許多支持 XQuery 的 SQL/XML(標准化越來越近了) 函數:
- XML(標准化越來越近了)QUERY
- XML(標准化越來越近了)EXISTS
- XML(標准化越來越近了)TABLE
發布
原樣存儲的 xml(標准化越來越近了) 文檔可以使用 XSLT UDF 進行轉換,或者使用 xml(標准化越來越近了)SERALIZE 或 XML(標准化越來越近了)2CLOB 進行串行化。
可以使用 DAD 映射和 xml(標准化越來越近了) Extender 發布 UDF,或者使用 SQL/xml(標准化越來越近了) 發布函數將分解的 xml(標准化越來越近了) 數據發布為 XML(標准化越來越近了)。
xml(標准化越來越近了) 列中原樣存儲的 xml(標准化越來越近了) 文檔可以使用 XQuery 進行發布和轉換,或者使用 XML(標准化越來越近了)SERIALIZE 串行化成 SQL 字符串。
對於分解的 xml(標准化越來越近了) 數據,需要在查詢中使用 SQL/XML(標准化越來越近了) 發布函數。 將 XML(標准化越來越近了) 數據插入 DB2
單一列中原樣存儲的 XML(標准化越來越近了)
如果 xml(標准化越來越近了) 數據原樣存儲在現有的應用程序中,那麼對於處理 XML(標准化越來越近了) 數據插入的應用程序代碼和 DB2 查詢應該沒有重大影響。
DB2 Version 8.x。將數據存儲到 CLOB、VARCHAR、xml(標准化越來越近了)CLOB 或 XML(標准化越來越近了)VARCHAR 列中:
insert into customer (info) values (?)
DB2 Viper。XML(標准化越來越近了) 類型的列:
代碼仍然是一樣的,除非需要對數據進行解析或驗證。
insert into customer (info) values (?)
如果需要針對已注冊的 xml(標准化越來越近了) 模式來驗證數據,那麼要將 XML(標准化越來越近了)VALIDATE 添加到 insert 語句中。
insert into customer (info) values (XML(標准化越來越近了)Validate(?))
注意: 在 XML(標准化越來越近了) Extender 中,可以在副表的 DAD 映射中隱式地進行驗證。
如果需要修改 xml(標准化越來越近了) 文檔的默認解析,那麼可以在 insert 語句中使用 XML(標准化越來越近了)PARSE 來指定解析選項。
insert into customer (info) values (XML(標准化越來越近了)PARSE(DOCUMENT
cast(? as BLOB(2M)) preserve whitespace ))
注意: 原樣存儲的 xml(標准化越來越近了) 數據也可以分解並映射到關系表以便進行查詢。這可以使用 xml(標准化越來越近了) 列副表的 DAD 映射來實現,也可以在應用程序代碼中實現。因為在 DB2 Viper 中可以直接索引和搜索 xml(標准化越來越近了) 文檔內部的節點,所以不必僅僅為了進行查詢而將 XML(標准化越來越近了) 分解為關系數據。處理分解的應用程序代碼是多余的。
分解到關系表的 XML(標准化越來越近了)
對於仍然需要分解的 XML(標准化越來越近了) 文檔,處理數據插入和分解的查詢和應用程序代碼的變化很小。
DB2 Version 8.x。使用 xml(標准化越來越近了) Extender 分解函數 dxxInsertxml(標准化越來越近了) 和 dxxShredxml(標准化越來越近了) 進行 XML(標准化越來越近了) 文檔分解。
Call dxxShredXML(標准化越來越近了) (?, ?,?,? );
Call dxxInsertXML(標准化越來越近了)(customerdad, ?,?,? );
DB2 Viper。使用帶注釋的 xml(標准化越來越近了) 模式映射進行 XML(標准化越來越近了) 文‡檔分解。
Call xdbDecompXML(標准化越來越近了) (NULL,migrate.customer,?,?,1,NULL,NULL,NULL)
如果文檔分解到單一表中,那麼可以使用 XML(標准化越來越近了)TABLE 進行分解。
Insert into product(pid,info) select x.pid, X.doc from XML(標准化越來越近了)TABLE
('$info//product' passing xml(標准化越來越近了)parse( DOCUMENT cast(? as XML(標准化越來越近了)) ) AS "info"
COLUMNS PID VARCHAR(12) PATH '@pid', doc XML(標准化越來越近了) by ref PATH '/') as x
如果在應用程序中使用 DOM 進行分解,那麼不需要改變任何代碼,除非希望將分解改為帶注釋的 xml(標准化越來越近了) 模式或使用 XML(標准化越來越近了)TABLE。
更新 DB2 中存儲的 XML(標准化越來越近了) 文檔
DB2 Version 8.x xml(標准化越來越近了) Extender 提供了一個 UDF,可以部分更新 DB2 中的 xml(標准化越來越近了) 文檔。Update 接受一個位置路徑,指定要更新的元素或屬性。它返回與被更新列相似的數據類型。XML(標准化越來越近了) 文檔中與位置路徑匹配的每個元素或屬性的內容都更新為提供的值。
Update purchaSEOrder set status='shipped', info=db2XML(標准化越來越近了).update(
info,'/purchaSEOrder/@status','shipped') where poid=2001;
因為 Update UDF 一次只處理一個位置路徑,所以要想對文檔進行大量修改,就需要將文檔檢索到客戶機應用程序中,進行修改,然後使用 SQL update 語句將它插回數據庫中。
注意: xml(標准化越來越近了) Extender 列上的 update 觸發器還更新對應的副表,從而保持 XML(標准化越來越近了) 列中的數據與副表中的數據同步。
DB2 Viper 沒有提供任何對數據庫中的 XML(標准化越來越近了) 文檔進行子元素更新的函數。原因在於 XQuery 標准還沒有定義更新的語法,但是已經有一些提案正在接受審議。DB2 不希望在語言中引入只能短期使用的專用函數。
對這個問題的解決方案是一個 Java 存儲過程,這個過程可以在文章 Partial updates to xml(標准化越來越近了) documents in DB2 Viper (developerWorks,2006 年 5 月)中找到。這個存儲過程可以部分更新 DB2 中的 xml(標准化越來越近了) 文檔。更新存儲過程還能夠刪除、替換和追加 XML(標准化越來越近了) 文檔中的節點。
注意: 在幕後,這個存儲過程進行全文檔更新。
Call DB2xml(標准化越來越近了)FUNCTIONS.XML(標准化越來越近了)UPDATE (
'path="/purchaSEOrder/@status">shipped ',
'Select info from purchaSEOrder where poid=2001',
'update purchaSEOrder set info=? where poid=2001',?,?);
注意: 因為也公布了源代碼,所以既可以按原樣使用這個存儲過程,也可以模仿它編寫自己的 Java 存儲過程來操作 DB2 中的 XML(標准化越來越近了) 數據。
查詢並發布 DB2 中存儲的 XML(標准化越來越近了) 文檔
處理查詢和發布的應用程序代碼是受影響最大的代碼之一。對於 xml(標准化越來越近了) Extender 列中存儲的 XML(標准化越來越近了) 數據,SQL 查詢完全變了,因為它們涉及副表,而現在已經不再維護副表了。
以下 SQL 查詢兩個表,返回有縮略圖的產品的細節:
Select SQLPRODUCT.DETAILS, from SQLIMAGES,SQLPRODUCT
where SQLPRODUCT.PID=SQLIMAGES.PID and SQLIMAGES.TYPE='thumbnail'
這可以替換為針對一列的單一查詢:
for $product in db2-fn:xml(標准化越來越近了)column("XML(標准化越來越近了)PRODUCT.DESCRIPTION")/product
where $product/description/images/image/@type="thumbnail"
return $product/description/details/text()
提取並查詢 xml(標准化越來越近了) 文檔中的 XML(標准化越來越近了) 數據
DB2 xml(標准化越來越近了) Extender extract UDF 提供了許多從 xml(標准化越來越近了) 文檔中提取數據的標量函數和表函數。任何涉及使用 DB2 extract UDF 從 xml(標准化越來越近了) 文檔中提取數據的 SQL 語句也必須替換為對 xml(標准化越來越近了)EXIST、xml(標准化越來越近了)QUERY 或 XML(標准化越來越近了)TABLE 的等效調用。
select db2xml(標准化越來越近了).extractVarchar(info,'/customerinfo/name') from XML(標准化越來越近了)customer
可以替換為:
Select xml(標准化越來越近了)cast( XML(標准化越來越近了)Query('$cinfo/customerinfo/name'
passing info as "cinfo") as varchar(32)) from
XML(標准化越來越近了)customer
select info from customers where db2XML(標准化越來越近了).extractvarchar(info,'/customerinfo/name')=?
可以替換為:
select info from xml(標准化越來越近了)customer where XML(標准化越來越近了)Exists('
$cinfo/customerinfo[name=$name]' passing info as "cinfo",
cast(? as varchar(32)) as "name")
DB2 xml(標准化越來越近了) Extender 提供了 ExtractCLOB () 和 ExtractCLOBs () UDF,用於提取 XML(標准化越來越近了) 文檔的片段。
select db2XML(標准化越來越近了).extractclob(info,'/customerinfo/addr') as RESULT from
customer where cid = ?
可以替換為:
select x.add from xml(標准化越來越近了)customer, XML(標准化越來越近了)TABLE ('$info//customerinfo' passing
info AS "info" COLUMNS add XML(標准化越來越近了) by ref PATH 'addr') as x where cid = ?
轉換和發布 XML(標准化越來越近了) 數據
除了可以用來獲得子文檔信息的 extraction UDF 之外,DB2 XML(標准化越來越近了) Extender 還提供了用來轉換數據庫中的 XML(標准化越來越近了) 文檔的 XSLT UDF。
DB2 XML(標准化越來越近了) Extender 中定義的兩個 XSL UDF 是 XSLTransformToClob() 和 XSLTransformToFile()。
SELECT XSLTransformToClob( info, /temp/xslfilename.xsl) FROM xslcustomers
SELECT XSLTransformToClob( info, ?) FROM xslcustomers
Pass the XSL as a CLOB at runtime
盡管 DB2 Viper 的 XML(標准化越來越近了) Extender 支持提供了 XSL UDF,但是沒有用於 XSL 轉換的內置函數(這意味著,為了使用 XSLT UDF,需要啟用數據庫的 xml(標准化越來越近了) Extender 支持)。因為,XQuery 在功能上與 XSL 有許多重復的地方,可以結合使用 XQuery 和 SQL/xml(標准化越來越近了) 函數來轉換和發布 XML(標准化越來越近了) 文檔。
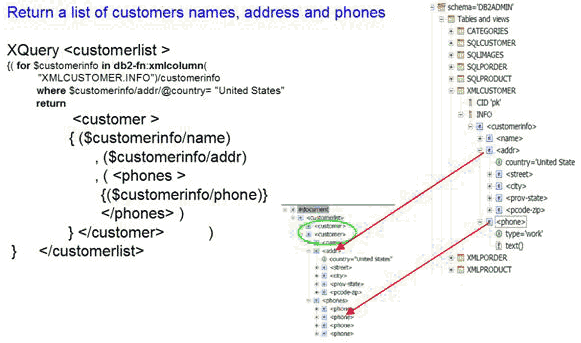
以下查詢演示如何使用 XQuery 來查詢和轉換本機存儲的 xml(標准化越來越近了) 文檔。這個 XQuery 構造稱為 “customer” 的新元素,並向其中添加來自 xml(標准化越來越近了)CUSTOMER 表中與條件(@country=United States)匹配的每個 XML(標准化越來越近了) 文檔的 name、address 和 phone 節點。然後,將這些 customer 元素返回到單一根節點 “customerlist” 中。
圖 7. 使用 XQuery 來查詢和轉換本機存儲的 XML(標准化越來越近了) 文檔
將關系數據轉換並發布為 XML(標准化越來越近了)
DB2 xml(標准化越來越近了) Extender DAD 文件和用於集合的存儲過程提供了雙向映射。可以使用同樣的映射進行分解和發布。不幸的是,帶注釋的 xml(標准化越來越近了) 模式沒有提供任何發布功能。所以,進行發布的惟一方法是使用 SQL/XML(標准化越來越近了) 函數。
考慮因素
本節包含在進行遷移時需要考慮到的一些因素。這包括一些限制或最佳實踐,可以幫助您在遷移 xml(標准化越來越近了) 應用程序時做出正確的決策。全面的考慮因素列表請參見 DB2 Viper 的文檔(Leveraging native XML(標准化越來越近了) support)和 ISV success with DB2 Viper: Prepare your applications, routines, and scripts for migration to DB2 Viper (developerWorks,2006 年 3 月)。
對 XML(標准化越來越近了) 列的限制
下面是對 XML(標准化越來越近了) 列的限制:
- XML(標准化越來越近了) 列不能作為鍵列的一部分,包括主鍵、外鍵、惟一鍵、
多維聚簇(MDC)表的維鍵、范圍聚簇表的序列鍵和分布或分區鍵。 - xml(標准化越來越近了) 列不能作為任何索引的一部分,除非是 XML(標准化越來越近了) 數據上的索引。
- XML(標准化越來越近了) 列不能具有由 WITH DEFAULT 子句指定的默認值;
如果這個列是可空的,那麼默認值是 NULL。 - XML(標准化越來越近了) 列不能用在物化查詢表中。
- XML(標准化越來越近了) 列不能用在范圍聚簇表中。
- XML(標准化越來越近了) 列不能用在 MDC 表中。
- 不能在 CHECK 約束中引用 XML(標准化越來越近了) 列。
- 不能在生成的列中引用 XML(標准化越來越近了) 列。
- 不能在觸發器中引用 XML(標准化越來越近了) 列。
- XML(標准化越來越近了) 模式
下面是與 XML(標准化越來越近了) 模式相關的考慮因素:
- 大型模式需要在應用程序堆中有足夠的空間。建議擴大應用程序堆,如下所示:
db2 update db cfg using applheapsz 1000
- 因為沒有 xml(標准化越來越近了) 模式與 xml(標准化越來越近了) 列相關聯,所以從技術上說可以在單一列中插入來自不同模式的 XML(標准化越來越近了) 文檔。
索引
只有滿足以下條件,才能將 XML(標准化越來越近了) 索引用於查詢謂詞:
- 索引包含查詢謂詞。例如,如果索引的限制性等於或小於謂詞。這包括名稱空間。
- 查詢謂詞匹配索引數據類型。
- 在謂詞和索引定義中以一致的方式使用 /text()。
盡可能使用完全指定的 XPath。避免使用通配符(*、//),避免使用 /text()。
/customerinfo/phone 而不是 //phone /customerinfo/addr/state 而不是 /customerinfo/*/state /customerinfo/name 而不是 /customerinfo/name/text() 帶注釋的 XML(標准化越來越近了) 模式
- 注釋不能用來驗證實例文檔。
- 大多數 XML(標准化越來越近了) 模式成分都可以有注釋。
- 在進行分解時,只查看屬於一個預定義名稱空間的元素聲明、屬性聲明和全局注釋上的注釋。
- 涉及遞歸的 XML(標准化越來越近了) 模式不能用於分解。它在注冊時會失敗。
- 驗證是可選的,可以用來添加默認值、修改文檔或修改分解的結果。
XML(標准化越來越近了)PARSE
要避免的最大的問題是導致輸入文檔的編碼不同於它的編碼聲明的編碼頁轉換,或引入替換字符的編碼頁轉換(如果目標編碼頁無法表示所有輸入字符,就會出現這種情況)。
- 強烈建議使用隱式的 xml(標准化越來越近了)PARSE。服務器期望接收 XML(標准化越來越近了) 類型,因此不進行任何編碼頁轉換。
insert into customer (cid, info) values (?,?)
- 使用顯式的 xml(標准化越來越近了)PARSE 會導致服務器期望接收字符或二進制類型(由 cast 子句決定)。使用 XML(標准化越來越近了)PARSE 並轉換到 CLOB 會使文檔的編碼頁轉換為服務器上的數據庫編碼頁。這通常是不必要或不合適的。
insert into customer (cid, info) values (?,XML(標准化越來越近了)PARSE(DOCUMENT
cast(? as CLOB(2M)) preserve whitespace ))
- 如果需要使用 xml(標准化越來越近了)PARSE 來修改默認的解析選項,那麼建議將數據轉換為二進制類型而不是字符類型。這會避免編碼頁轉換問題。因為以字節流形式讀取輸入的 XML(標准化越來越近了) 文件,所以在服務器上和 Java 端都不進行編碼頁轉換。轉換到 BLOB 可以防止在服務器上轉換文檔的編碼頁。
insert into customer (cid, info) values (?,XML(標准化越來越近了)PARSE(DOCUMENT
cast(? as BLOB(2M)) preserve whitespace ))
XML(標准化越來越近了)VALIDATE
下面是與 XML(標准化越來越近了)VALIDATE 相關的考慮因素:
XML(標准化越來越近了)QUERY
下面是與 XML(標准化越來越近了)QUERY 相關的考慮因素:
- 在純 XQuery 中不能綁定運行時謂詞,但是可以通過 SQL/xml(標准化越來越近了) 函數或謂詞(比如 xml(標准化越來越近了)QUERY 、xml(標准化越來越近了)TABLE 和 XML(標准化越來越近了)EXISTS)間接地應用運行時謂詞。
- 對於 XQuery 比較,如果基類型是已知的,那麼不進行隱式轉換,不允許非法比較。
XML(標准化越來越近了)EXISTS
下面是與 XML(標准化越來越近了)EXISTS 相關的考慮因素:
- 在 where 子句中使用 xml(標准化越來越近了)EXISTS 而不是 XML(標准化越來越近了)QUERY。
- 只有在查詢的結果是一個空序列時,xml(標准化越來越近了)EXISTS 才會返回 false(這意味著 XML(標准化越來越近了)EXISTS(false) 返回 true,因為這個查詢的結果不是一個空序列)。以下查詢返回顧客表中的所有行,因為當 customerinfo/name 不是 Hardeep 時,查詢返回一個包含 false 值的序列,而不是空序列。
select c.info from xml(標准化越來越近了)customer c where XML(標准化越來越近了)exists('
$i/customerinfo/name = "Hardeep" ' passing c.info as "i")
- 在 xml(標准化越來越近了)EXISTS 謂詞中使用方括號 []。如果將名稱檢查放在方括號中,那麼前面的查詢就會正常工作了,因為對於名稱不是 Hardeep 的所有 customerinfo,查詢現在返回空序列,XML(標准化越來越近了)EXISTS 返回 false。
select c.info from xml(標准化越來越近了)customer c where XML(標准化越來越近了)exists('
$i/customerinfo[name = "Hardeep"] ' passing c.info as "i")
- 將多個 xml(標准化越來越近了) 謂詞組合在一個 XML(標准化越來越近了)EXISTS 中。下面兩個查詢並不是一樣的:
select * from customer where XML(標准化越來越近了)exists('
$c/customerinfo[name = Hardeep]) and
XML(標准化越來越近了)exists('$c/customerinfo[phone = 555-555-555] '.)
select * from customer where XML(標准化越來越近了)exists('
$c/customerinfo[name=Hardeep and phone=555-555-555]...)
如果某個文檔包含兩個 customerinfo 元素,其中之一包含 name=hardeep 和 phone=111-111-111,另一個包含 name=Marja 和 phone=555-555-555,那麼第一個查詢返回這個文檔,而第二個查詢不返回它。