傳統數據庫架構
縱觀各傳統商業數據庫軟件,多以集中式架構為主,鮮有以分布式為設計理念的架構。這些傳統數據庫軟件的最大特點就是將所有的數據都集中在一個數據庫中,依靠大型高端設備來提供高處理能力和擴展性。
集中式數據庫架構在擴展性方面主要依賴於主機和存放數據的存儲設備的擴展能力,也就是說依賴硬件本身的縱向擴展能力,很難做到較好的橫向擴展。而其可靠性也同樣是以硬件設備為依托,主要通過Share Storage的方式來實現。如大家所熟知的傳統商業數據庫代表廠商Oracle的RAC,就是一個非常典型的Share Everything 的集中式架構。
我們可以通過圖1來簡單地描繪一下傳統數據庫的典型架構:傳統架構在主機端大多通過兩台主機共享存儲設備,平時其中一台主機使用存儲通過數據庫軟件來管理。這樣的架構只能有一台主機(RAC除外)上的數據庫能夠提供服務,另一台主機只能是作為熱備冗余,不能啟動數據庫實例提供服務。所以,其處理能力就完全取決於這台主機的最大擴展能力,很難通過增加主機數量來增加處理能力。而單台主機的擴展能力畢竟是有限的,即使是某些廠商的大型機,同樣也有其擴展限制。此外,傳統架構對高端設備的依賴,無疑將直接導致系統成本的大幅度增加,甚至可能會導致系統被主機和硬件廠商所“綁架”,不得不持續增加投入成本。
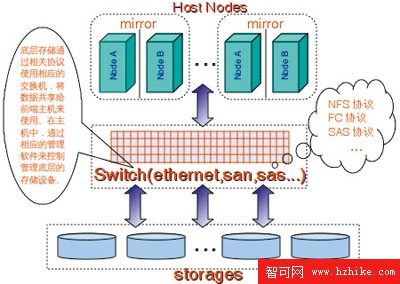
圖1 傳統數據庫的典型架構
基於MySQL的可擴展和高可靠
MySQL作為開源數據庫的佼佼者,無論是軟件本身的設計思想,還是推崇給廣大使用者們常用的架構思路都和傳統的商業數據庫軟件大相徑庭。 MySQL棄用了傳統的Share-Everything的思想,而采用了Share-Nothing的思想。MySQL的Replication實現機制,以及MySQL Cluster的架構設計,都體現了這一思想。也正因如此,給MySQL在可擴展性和高可靠性方面帶來了非常靈活的架構設計思路,也讓我們的數據庫可以擺脫對高端設備的依賴,使用上性價比高很多的PC Server。
可擴展性
在提升擴展性方面,最為常用的是通過MySQL自身的Replication功能,將同一份MySQL的數據以異步的方式同時復制到另外的一台或多台MySQL主機上,並讓這些MySQL主機同時對外提供查詢服務。每增加一個復制的節點,查詢處理能力也得到相應的增加,新增節點的處理能力就是整個系統增加的處理能力。由於MySQL Replication主要是邏輯方式,同一個集群中可有多家廠商的硬件,也可以使用不同的OS,所以可以做到完全不受任何軟/硬件平台限制,擺脫對單一平台的依賴。
人們可能會對MySQL Replication的功能特性不滿意,進而通過第三方開源軟件,甚至是通過解析其開源的通信協議自行開發出來的復制軟件來進行數據實時(或者異步)復制來達到 Replication完全相同甚至更好的效果。傳統數據庫可能也具有某項功能實現數據的復制,但與MySQL相比,由於只依靠數據庫本身特性來完成,在架構的靈活性和可控性方面存在一些不足。
最後,在提升擴展性方面不得不說的數據切分(橫向/縱向)的思想,同樣可以在MySQL數據庫上得到靈活的發揮,無論是以功能模塊的方式進行縱向的切分,還是以某個特定鍵(字段)的類HASH分段的方式進行橫向的切分,抑或是通過數據庫本身的Partition功能進行切分,都可以在 MySQL上得到很好的實現。當然,無論是切分前的數據分散,還是切分後的數據路由和合並都離不開應用層的協作與配合,除非通過MySQL Cluster來實現。對於提升擴展性的架構,通過圖2會有一個更為直觀的展現。
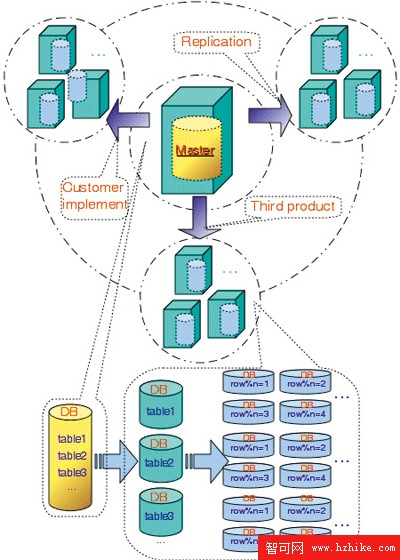
圖2 能夠提升擴展性的架構
圖中以“Master”為核心,通過不同的方式以三條“路線”將數據復制到相應的 MySQL 集群中對外提供服務。實際的架構中,Master就是一個數據寫入點,復制出去的集群則可以對外提供相應的查詢請求。常見的Web應用系統中,查詢請求遠遠大於寫入請求,所以非常適合通過MySQL 數據庫使用類似的架構思想來解決實際的擴展性問題。
高可靠性
在保證高可靠性方面,同樣可以通過MySQL的 Replication 為基礎,加以應用層架構的簡單配合或一些開源的第三方HA管理軟件來設計出多種非常靈活的高可靠架構。
對於數據寫入點,可以通過MySQL的Replication功能,將兩台MySQL主機設置成雙A的狀態,並通過HA管理軟件,對MySQL 的狀態檢測,來判定MySQL的狀態,並對外提供供單一的服務 IP 地址,以確保在任何時候有一台MySQL崩潰後馬上切換到另外一台MySQL上提供服務。這樣自動的方式非常方便地讓我們的寫入點擁有高可靠性。如果我們的應用程序也可以自動判斷當一個點失效後馬上自動切換到另外一個點就更好,基本上可以做到對外部完全透明的切換,對可用性的影響之小,比現在一些知名廠商的專業HA管理都要好很多。
對於數據查詢點,高可靠性的實現就更容易了,可從雙A的兩台Master端中的任意一台上通過數據復制搭建多個具有完全相同數據拷貝的 MySQL節點,來保證任何時刻都可以有多台MySQL對外提供數據查詢服務。當一台MySQL崩潰,系統馬上將該節點從可以服務的節點中剔除出去。通過應用架構的幫助這是非常容易做到的事情。
圖3是高可靠性實例圖。1描繪了基本架構,2、3和4分別描繪了當讀節點失效以及寫節點中的任何一個失效後的高可靠性實現。在高可靠性方面,除了自行控制將數據復制到多個MySQL主機上的方式之外,MySQL還提供了更為高級的方案——MySQL Cluster,一個完全的分布式數據庫集群,而且是一個非常典型的Share-Nothing的分布式數據庫架構。數據層和SQL層分離,每份數據都以兩份或更多份拷貝存放在不同的數據節點上,整個數據層的所有節點以分布式計算的思想共同處理整個數據庫的數據,在保證高並發的處理能力的同時,以數據冗余的方式保證了高可靠性。
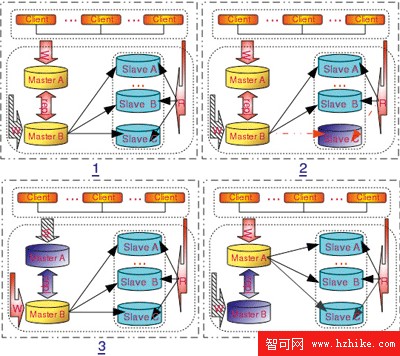
圖3 高可靠性實例圖
構建基於MySQL、Cache 和Search的數據層
隨著Web應用系統負載的增速越來越快,常讓系統不堪重壓,數據庫系統尤甚。而隨著對用戶體驗關注度的提高,響應速度和使用的便利性則成為不可避免的話題。無論如何優化都不可能避免磁盤物理I/O的響應速度與內存中的I/O速度不匹配的問題,所以很自然地想到了通過內存Cache的方式來提高響應速度。
在使用的便利性方面最為典型的就是數據搜索。關系型數據庫的特性,決定了它很難提供類似於Google那樣的可以全文檢索的搜索系統。我們再次以借助“外力”的方式來完善服務,將數據庫中的數據通過利用Lucene或者Egothor等類似的搜索引擎系統,或者是利用Sphinx之類的軟件和數據庫集成,為數據庫增加全文檢索的能力。
可以設計出一個以數據庫(My-SQL)來完成持久化和常規的數據訪問功能,以分布式內存Cache系統來提供對響應速度和並發能力極高的數據的訪問,以第三方或者自行研發的分布式全文搜索系統來提供全文檢索服務的全方位的分布式數據服務層,中間則通過應用架構的幫助實現一個統一的數據訪問層,來控制數據的讀取寫入檢索等操作,如圖4所示:讓MySQL中的數據同步(或異步)寫入到Cache和Search系統的實現方式很多,如對實時性要求不是很高,也不希望Data Proxy Layer中有太多的控制邏輯,完全可以通過隊列的方式以異步的方式實現;如對實時性要求較高,也可以通過 Data Proxy Layer這一層應用來控制Cache和Search中的數據更新;甚至還可以通過MySQL的用戶自定義函數,以Trigger的方式將數據實時地更新到Cache集群。類似的方式可以想出很多,關鍵是要根據應用場景,來選擇最合適、最簡單的方式來實現。
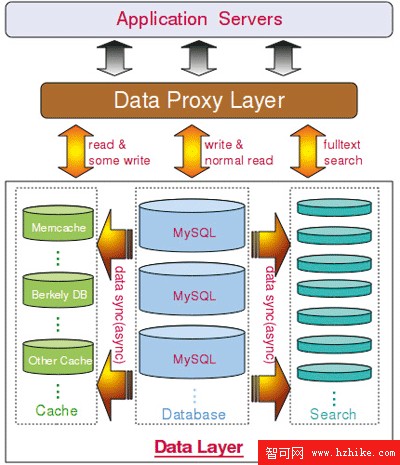
圖4 數據寫入Cache和Search系統的實現方式
架構無所謂最好的,只有最合適的。任何架構都有其適用的場景,也有其相應的生命周期。應用場景或業務量的變化,都可能導致架構不足以應對的現象。引用一句電影台詞:“出來混,遲早要還的!”