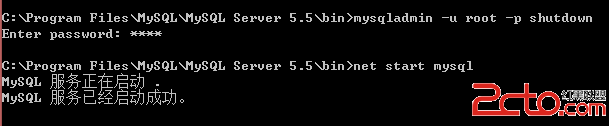
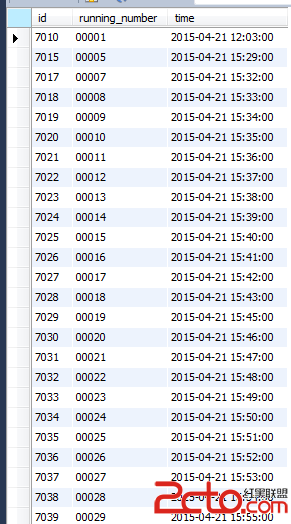
mysql邏輯架構如下:
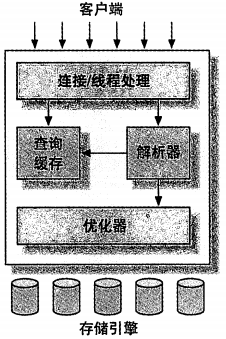
每個客戶端連接都會在服務器中擁有一個線程,這個連接的查詢只會在這個單獨的線程中執行。
MySQL是分層的架構。上層是服務器層的服務和查詢執行引擎,下層是存儲引擎。雖然有很多不同作用的插件API,但存儲引擎API還是最重要的。如果能理解MySQL在存儲引擎和服務層之間處理查詢時如何通過API來回交互,就能抓住MySQL的核心基礎架構的精髓。
數據庫系統實現了各種死鎖檢測和死鎖超時機制,InnoDB目前處理死鎖的機制是,將持有最少行級排它鎖的事務進行回滾。MySQL服務層不管理事務,事務是由下層的存儲引擎實現的。
注意,SQL語句一般以';'或者'\g'結束。
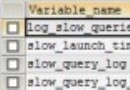
MySQL支持的其他show語句還有:
SQL語句中最常用的就是select語句了,它用來在一個或多個表中檢索數據,select使用示例如下:
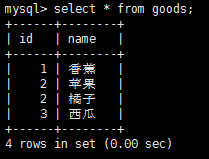
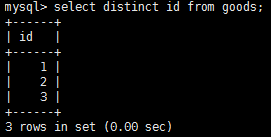
注意,select返回所有匹配的行,但是,如果我們不想每個值都每次出現,怎麼辦呢?例如,想讓上圖中輸出的id唯一,這樣可以再select語句中添加distinct關鍵字,select distinct id from goods,這樣顯示結果如下:
有時我們想限制輸出的結果,比如返回第一行或前幾行,可使用limit子句,如下所示:
當然,我們也可以使用完全限制來進行數據檢索:
select goods.id, goods.name from goods 輸出goods表中所有記錄
排序檢索數據主要使用select語句的order by子句,根據需要排序檢索出的數據,select語句默認返回結果是沒有特定順序的,在排序檢索數據時也可以指定排序的方向,比如升序或者降序等,order by子句默認為升序排列。
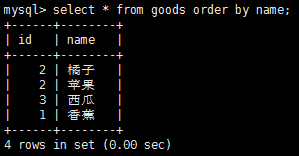
 (這個是降序配列)
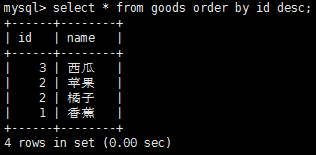
(這個是降序配列)
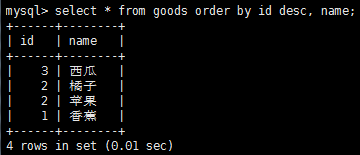
有時,我們需要對多個列排序怎麼辦呢?這時可以使用如下sql語句來執行,select * from goods order by id desc, name,注意,這裡是對id進行降序排列,如果id相同時,對name進行升序排列。如果想對多個列進行降序排列,需要對每個列指定desc關鍵字。
使用order by和limit的組合,我們能夠找到一個列中最高或者最低的值,比如這裡還用goods表做測試,先給goods表增加一個num字段(alter table goods add num int),並添加上對應的值,最後goods表內容為:
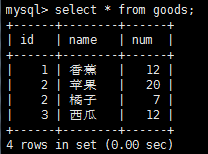
找出剩余數量最多的的水果是:
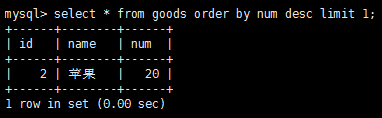
注意:select語句的order by子句對檢索出的數據進行排序,這個字句必須出現在select語句中的最後一條子句。至於為什麼,這個我暫時還不知道哈。。。
select語句中,數據可以根據where子句指定的過濾條件進行過濾,where子句在表名(from子句)之後給出,比如,select id, name from goods where id = 2,該語句只顯示id為2記錄的id和name。注意:如果同時使用where和order by子句,應該讓order by子句在where之後,否則會產生錯誤。
where子句操作符如下:
我們在創建表時,可以指定其中的列是否可以不包含值,在一個列不包含值時,其值為空值null,select語句有一個特殊的where子句,用來檢測具有null值的列,比如:select * from goods where num is null 就把num是空值得記錄給打印出來。
常用的select子句在過濾數據時使用的是單一的條件,為了進行更強的過濾控制,可以下多個where子句,這些子句有兩種方式:以and子句和or子句的方式使用。
假如多個and和or語句放在一起,則優先處理and操作符,此時可以使用圓括號來改變其優先順序。圓括號還可以指定in操作符的條件范圍,范圍中的每個條件都可以進行匹配。
where子句中的not操作符只有否定它之後的任何條件這一作用。
使用like操作符進行通配搜索,以便對數據進行復雜過濾。
百分號(%)操作符 搜索中,%表示任何字符出現任意次數。
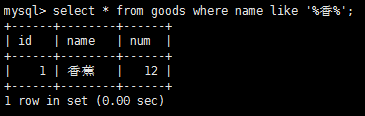
下劃線(_)通配符,它用來匹配單個字符而不是多個字符。
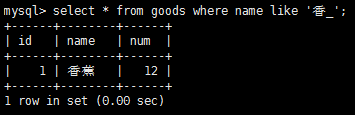
通配符很有用,但這是有代價的,通配符的搜索處理一般比其他搜索花費時間長,這裡有一些技巧:
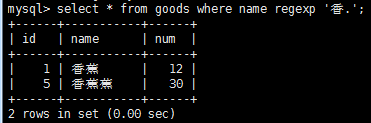
正則表達式的作用是匹配文本,將一個模式(正則表達式)與一個文本串進行比較。mysql的where子句對正則表達式提供了初步支持,允許你指定正則表達式 ,過濾select檢索出的數據。先看一下表記錄:
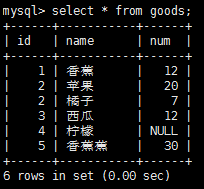
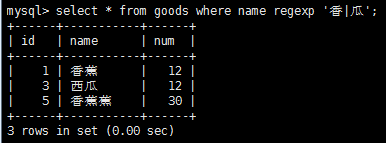
如果記錄匹配正則表達式,則就會被檢索出來,使用下面正則表達式重復元字符可以進行更強的控制。
注意:regexp和like作用類似,regexp和like不同之處在於,like匹配整個串而regexp匹配子串,利用定位符,通過'^'開始每個表達式,用'$'結束每個表達式,可以使regexp的作用和like一樣。
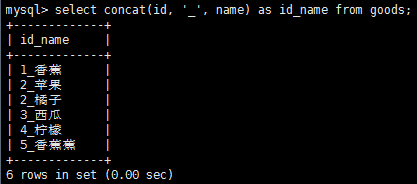
拼接將值連接到一起構成單個值,在mysql的select語句中,可使用concat()函數來拼接兩個列。
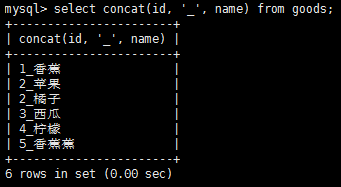
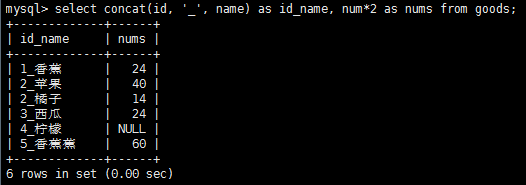
從上圖中我們可以看到新的計算列的名字只是一個值,我們可以使用別名來使得它更有意義。同時也可以對檢索出的數據進行算術運算,加減乘除都是支持的。
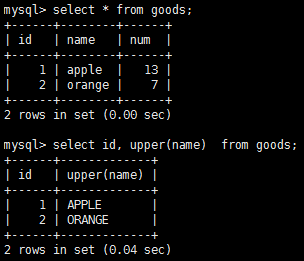
常用的文本處理函數
函數 說明 left() 返回串左邊的字 length() 返回串的長度 locate() 找出串的一個子串 lower() 將串轉換為小寫 ltrim() 去掉串左邊的空格 right() 返回串右邊的字符 rtrim() 返回串右邊的字符 soundex() 返回串的soundex值 substring() 返回子串的字符 upper() 將串轉換為大寫
經常需要匯總數據而不是把它們檢索出來,為此mysql提供了專門的函數,以便分析和報表生成。常用的例子有:確定表中行數、獲取表中行組的和、找出表列的最大值(最小值或平均值)。聚集函數運行在行組上,計算和放回單個值得函數,mysql提供了5個聚集函數,這些函數一般比自己的客戶端應用程序中計算要快得多。
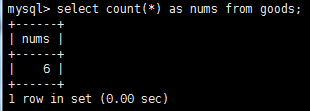
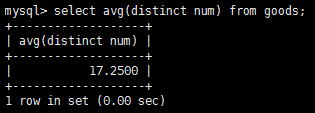
使用關鍵字distinct使得只選擇不同num的記錄來參與計算。
sql聚集函數可以用來匯總數據,這使得我們能夠對行計數、計算平均值、獲取最大最小值不用檢索所有數據。而創建分組允許把數據分為多個邏輯組,以便對每個組進行聚集計算。其涉及到group by子句和having子句。
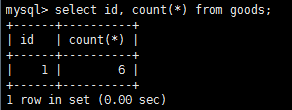
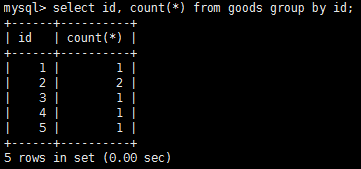
在使用group by子句前,需要知道一些重要的規定:
除了能用group by分組數據外,mysql還允許過濾分組,規定包括哪些分組,排除哪些分組。過濾分組需使用having子句,因為where過濾的是行而不是分組。注意:where是在數據分組前進行過濾,having是在數據分組後進行過濾。

group by和order by經常完成相同的工作,但是二者是非常不同的:
order by group by 排序產生的輸出 分組行,但輸出可能不是分組的順序 任意列都可以使用(甚至非選擇的列) 只可能使用選擇列或表達式列,而且必須使用每個選擇列表達式 不一定需要 如果與聚集函數一起使用列(或表達式),則必須使用下面是select語句中子句的順序,以在select中使用時必須遵循的次序為順序。
子句 說明 是否必須使用 select 要返回的列或表達式 是 from 從中檢索數據的表 僅再從表選擇數據時使用 where 行級過濾 否 group by 分組說明 僅在按組計算聚集時使用 having 組級過濾 否 order by 輸出排序順序 否 limit 要檢索的行數 否
什麼是子查詢呢?子查詢就是嵌套在其他查詢中的查詢, 在where子句中使用子查詢,應該保證select語句具有和where子句中相同數目的列,通常,子查詢將返回單個列並且與單個列匹配。
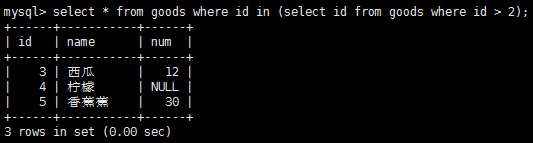
外鍵為某一個表中的一列,它包含另一個表的主鍵值,定義了兩個表的關系。如果數據存儲在多個表中,使用連接可用單條select語句檢索出需要的數據。應該保證所有的連聯結都有where子句,否則mysql將返回比想要的多的多的數據,因為此時檢索出的行數目是第一個表行數乘以第二個表行數。
聯結是SQL中最重要最強大的特性。關系表的設計就是要保證把信息分解成多個表,一類數據一個表。各表通過某些常用的值(即關系設計中的關系relational)互相關聯。
SELECT vend_name, prod_name, prod_price FROM vecdors, products WHERE vendors.vend_id = products.vend_id ORDER BY vend_name, prod_name; 創建連接表
使用WHERE子句作為過濾條件,它只包含匹配給定給定條件的行。沒有WHERE子句,第一個表中的每個行將於第二個表中的每個行配對,而不管它們邏輯上是否可以配對在一起。SQL對一條SELECT語句中可以聯結的表的數目沒有限制。
基於兩個表之間相等測試的聯接稱為內部聯接。其實,對於這種聯結可以使用稍微不同的語法來明確指定聯結的類型,下面的SELECT語句返回與前面例子完全相同的數據。
SELECT vend_name, prod_name, prod_price FROM vendors INNER JOIN products ON vendors.vend_id = products.vend_id;
除了可以給列名和計算字段其別名外,還可以給表起別名。
除了使用內部聯接(或稱為等值聯接)的簡單鏈接,還可以使用自聯結、自然聯結、外部鏈接。
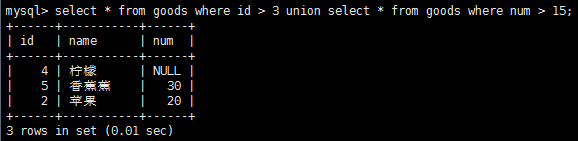
利用union操作符和組合多條SQL查詢,讓給出的多條select語句結果組合成單個結果集。注意,union必須有2條或者2條以上的select語句組成,union中每個查詢必須包含相同的列、表達式或聚集函數(不過每個列不需要以相同的次序列出)。union會自動去除重復的行,這個是默認的行為,如果不想這樣,使用union all而不是使用union。
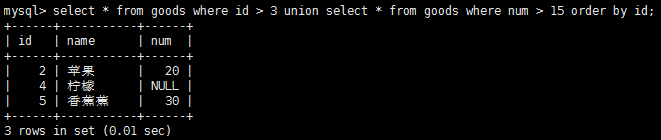
如何對union語句的輸出進行排序呢?使用order by子句時,必須放在union最後一條select語句之後,對於結果集,只能有一種排序規則,所以不允許使用功能多條order by子句。
插入語句insert一般會有產生輸出,一般只會打印影響的行數。insert時如果不提供列名,則必須給每個表列提供一個值,如果提供列名,則必須對每個列出的列給出一個值,否則報錯。
插入一個完整的行:
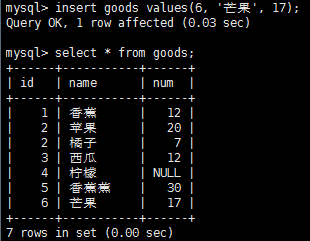
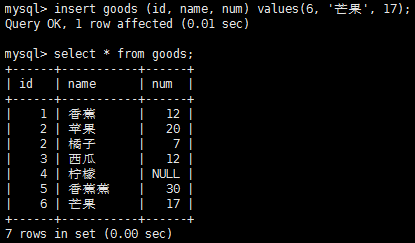
插入多個行:

分別使用update語句和delete語句來進行更新和刪除數據操作。先把goods表中數據清除掉一部分,goods表數據如下:
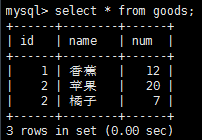
注意,這裡有一些使用update和delete語句的一些注意事項:
利用create table創建表,必須給出表的名字,在關鍵字create table只有給出;表列的名字和定義,用逗號隔開。
create table vendors (
vend_id int not null auto_increment,
vend_name char(50) not null,
vend_address char(50) null default '*',
vend_city char(40) null,
primary key (vend_id)
) engine=InnoDB;
這條語句創建一個vendors表,vend_id和vend_name是必須的,指定為not null,其他的為非必須的,指定為null,null為默認設置。auto_increment關鍵字告訴mysql,本列每當增加一行時自動增量,可以保證該列值唯一。每個表只允許有一個auto_increment列,而且它必須被索引(如,通過使它為主鍵)。default為默認值。
注意,主鍵必須唯一,表中的每個行必須具有唯一的主鍵,如果主鍵使用單個列,則它的值必須唯一;如果使用多個列,則這些列的組合必須唯一。外鍵不能垮跨越引擎。mysql內部打包了多種引擎,以下幾個是需要知道的引擎:
使用alter table語句更新表結構。
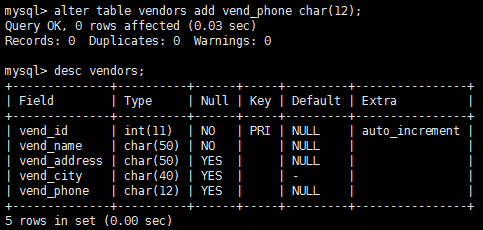
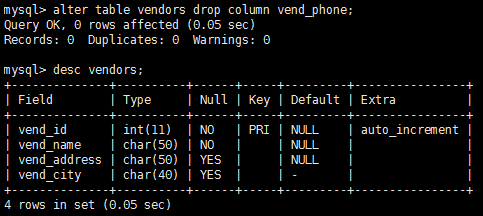
刪除表(不是其內容,而是整個表)使用drop語句即可。drop table table_name; 這條語句刪除table_name表,只要它存在,注意,刪除表時沒有確認,也不能撤銷。
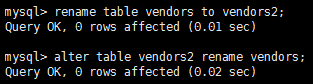
使用rename table語句重命名表。
視圖是虛擬的表,與包含數據的表不一樣,視圖只包含使用時動態檢索數據的查詢。視圖僅僅是用來查看存儲在別處數據的一種設施,視圖本身不包含數據,因此它們返回的數據是從其他表中檢索出來的。視圖提供了一種MySQL的SELECT語句層次的封裝,可用來簡化數據處理以及重新格式化基礎數據或保護基礎數據。
使用視圖的常見應用:
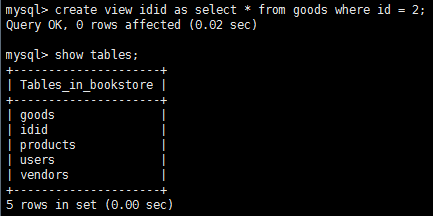
使用視圖簡化復雜的聯結,視圖使用create view語句來創建,使用show create view viewname來查看創建視圖的語句;用drop刪除視圖,語法為drop view viewname。
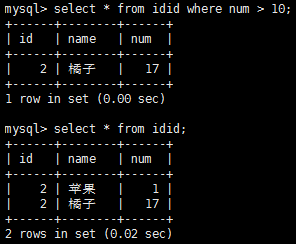
通常,視圖是可更新的(可以對它們使用insert、update和delete),更新一個視圖將更新其基表,因為視圖本身是沒有任何數據的。但是,並非所有的視圖是可更新的,如果mysql不能正確的確定被更新的基數據,則不能被更新,即如果有一下操作,視圖不允許更新:分組、聯結、子查詢、並、聚集函數、distinct等。
1、MySQL必知必會
2、SQL 教程
3、高性能MySQL