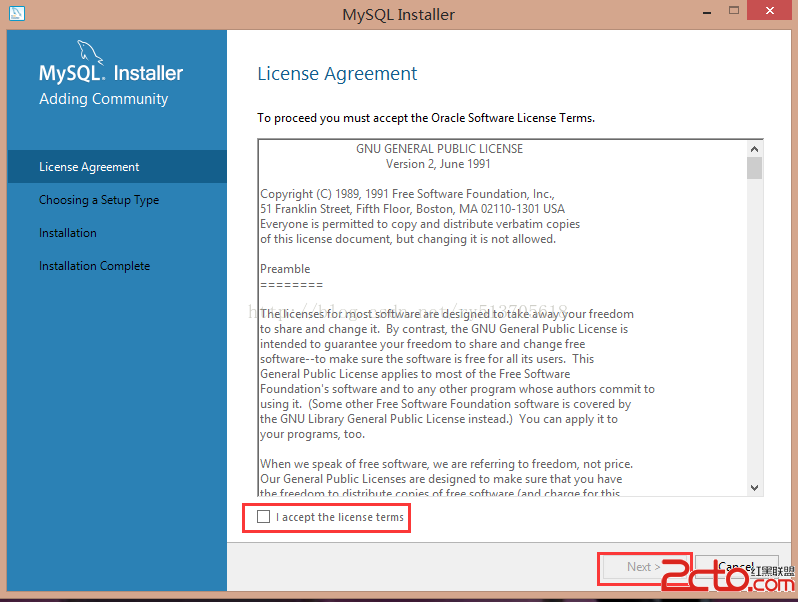
作為Java程序員,MySQL數據庫大家平時應該都沒少使用吧,對MySQL數據庫的引擎應該也有所了解,這篇文章就讓我詳細的說說MySQL數據庫的Innodb和MyIASM兩種引擎以及其索引結構。也來鞏固一下自己對這塊知識的掌握。
Innodb引擎提供了對數據庫ACID事務的支持,並且實現了SQL標准的四種隔離級別,關於數據庫事務與其隔離級別的內容請見數據庫事務與其隔離級別這篇文章。該引擎還提供了行級鎖和外鍵約束,它的設計目標是處理大容量數據庫系統,它本身其實就是基於MySQL後台的完整數據庫系統,MySQL運行時Innodb會在內存中建立緩沖池,用於緩沖數據和索引。但是該引擎不支持FULLTEXT類型的索引,而且它沒有保存表的行數,當SELECT COUNT(*) FROM TABLE時需要掃描全表。當需要使用數據庫事務時,該引擎當然是首選。由於鎖的粒度更小,寫操作不會鎖定全表,所以在並發較高時,使用Innodb引擎會提升效率。但是使用行級鎖也不是絕對的,如果在執行一個SQL語句時MySQL不能確定要掃描的范圍,InnoDB表同樣會鎖全表。
MyIASM是MySQL默認的引擎,但是它沒有提供對數據庫事務的支持,也不支持行級鎖和外鍵,因此當INSERT(插入)或UPDATE(更新)數據時即寫操作需要鎖定整個表,效率便會低一些。不過和Innodb不同,MyIASM中存儲了表的行數,於是SELECT COUNT(*) FROM TABLE時只需要直接讀取已經保存好的值而不需要進行全表掃描。如果表的讀操作遠遠多於寫操作且不需要數據庫事務的支持,那麼MyIASM也是很好的選擇。
大尺寸的數據集趨向於選擇InnoDB引擎,因為它支持事務處理和故障恢復。數據庫的大小決定了故障恢復的時間長短,InnoDB可以利用事務日志進行數據恢復,這會比較快。主鍵查詢在InnoDB引擎下也會相當快,不過需要注意的是如果主鍵太長也會導致性能問題,關於這個問題我會在下文中講到。大批的INSERT語句(在每個INSERT語句中寫入多行,批量插入)在MyISAM下會快一些,但是UPDATE語句在InnoDB下則會更快一些,尤其是在並發量大的時候。
索引(Index)是幫助MySQL高效獲取數據的數據結構。MyIASM和Innodb都使用了樹這種數據結構做為索引,關於樹我也曾經寫過一篇文章樹是一種偉大的數據結構,只是自己的理解,有興趣的朋友可以去閱讀。下面我接著講這兩種引擎使用的索引結構,講到這裡,首先應該談一下B-Tree和B+Tree。
B+Tree是B-Tree的變種,那麼我就先講B-Tree吧,相信大家都知道紅黑樹,這是我前段時間學《算法》一書時,實現的一顆紅黑樹,大家可以參考。其實紅黑樹類似2,3-查找樹,這種樹既有2叉結點又有3叉結點。B-Tree也與之類似,它的每個結點做多可以有d個分支(叉),d稱為B-Tree的度,如下圖所示,它的每個結點可以有4個元素,5個分支,於是它的度為5。B-Tree中的元素是有序的,比如圖中元素7左邊的指針指向的結點中的元素都小於7,而元素7和16之間的指針指向的結點中的元素都處於7和16之間,正是滿足這樣的關系,才能高效的查找:首先從根節點進行二分查找,找到就返回對應的值,否則就進入相應的區間結點遞歸的查找,直到找到對應的元素或找到null指針,找到null指針則表示查找失敗。這個查找是十分高效的,其時間復雜度為O(logN)(以d為底,當d很大時,樹的高度就很低),因為每次檢索最多只需要檢索樹高h個結點。

接下來就該講B+Tree了,它是B-Tree的變種,如下面兩張圖所示:

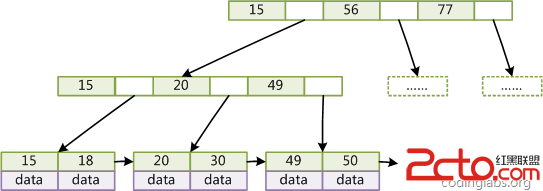 vcHLx/i85LLp0a/Qp8LKoaM8L3A+DQo8aDMgaWQ9"myisam引擎的索引結構">MyISAM引擎的索引結構
vcHLx/i85LLp0a/Qp8LKoaM8L3A+DQo8aDMgaWQ9"myisam引擎的索引結構">MyISAM引擎的索引結構
MyISAM引擎的索引結構為B+Tree,其中B+Tree的數據域存儲的內容為實際數據的地址,也就是說它的索引和實際的數據是分開的,只不過是用索引指向了實際的數據,這種索引就是所謂的非聚集索引。
MyISAM引擎的索引結構同樣也是B+Tree,但是Innodb的索引文件本身就是數據文件,即B+Tree的數據域存儲的就是實際的數據,這種索引就是聚集索引。這個索引的key就是數據表的主鍵,因此InnoDB表數據文件本身就是主索引。
因為InnoDB的數據文件本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識數據記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含字段作為主鍵,這個字段長度為6個字節,類型為長整形。
並且和MyISAM不同,InnoDB的輔助索引數據域存儲的也是相應記錄主鍵的值而不是地址,所以當以輔助索引查找時,會先根據輔助索引找到主鍵,再根據主鍵索引找到實際的數據。所以Innodb不建議使用過長的主鍵,否則會使輔助索引變得過大。建議使用自增的字段作為主鍵,這樣B+Tree的每一個結點都會被順序的填滿,而不會頻繁的分裂調整,會有效的提升插入數據的效率。