通過上篇文章給大家介紹了SqlServer應用之sys.dm_os_waiting_tasks 引發的疑問(上) ,說了一下sys.dm_exec_requests 和 sys.dm_os_waiting_tasks 在獲取並行等待的時候得不同結果,這一篇我們談論下我的第二個疑問:為什麼一個並行計劃(4線程)卻一下出現了那麼多等待,SQL的並行到底是怎麼執行的!!!!
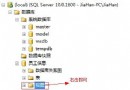
先貼以下上篇sys.dm_os_waiting_tasks 的結果圖:
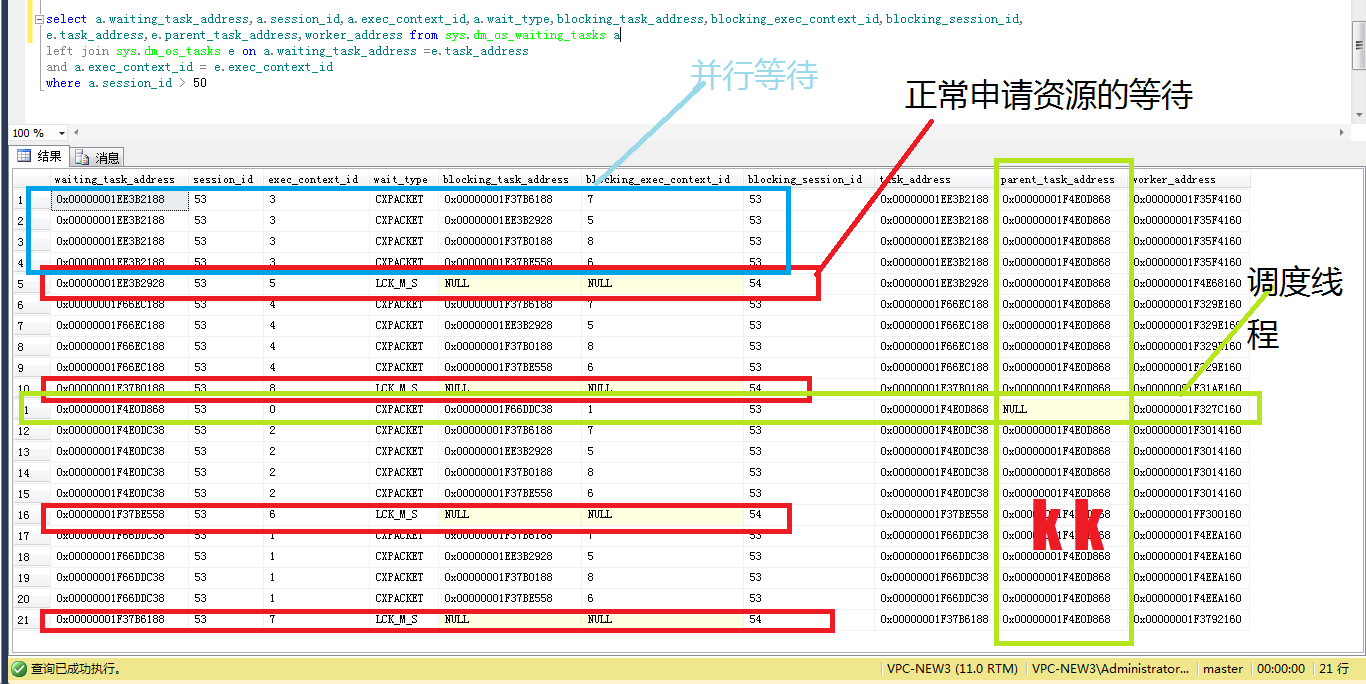
我們分析一下這個結果的task_address 可以看出去掉重復其實只有9個,也就是說一個並行(4線程,配置不同,情況也不同)會有9個task。 又是線程,又是task ,還有worker,schedulers 這些都是什麼? 這個有必要先說一下,因為這篇博客前我也是亂亂的。
scheduler
對於每個邏輯CPU,SQLSERVER會有一個scheduler與之對應,在SQL層面上代表CPU對象,只有拿到scheduler所有權的任務worker才能在這個邏輯CPU上運行
所謂邏輯CPU,就是SQLSERVER從Windows層面上看到的CPU數目,如果是一個雙核的CPU,那麼一個物理CPU在SQL看來就是兩個邏輯CPU。如果系統還使用了
超線程hyper-threaded ,那對SQLSERVER來講就是4個邏輯CPU
規則: 每個scheduler上的最大worker數目等於SQLSERVER的最大線程數除以scheduler的數目 ,在同一個時間點,只能有一個擁有scheduler的worker處於運行狀態,其他worker都必須處於等待狀態。這樣能降低每個邏輯CPU上的處於正在運行狀態的線程數目,降低context switch,提供可擴展性scheduler是SQLSERVER的一個邏輯概念,他不與物理CPU相綁定。也就是說,一個scheduler可以被Windows安排一會兒在這個CPU上,一會兒在那個CPU上。
但是,如果在sp_configure裡設置了CPU affinity mask,那麼scheduler就會固定在某個特定的CPU上
worker
每個worker跟一個線程(或纖程fiber)相對應,是SQLSERVER任務的執行單位。SQLSERVER不直接調度線程/纖程,而是調度worker,使得SQLSERVER能夠控制
任務調度
規則: 每個worker會固定代表一個線程(或纖程),並且和一個scheduler相綁定。如果scheduler是固定在某個CPU上的(通過設置CPU affinity mask),那麼worker也會固定在某個CPU上每個scheduler有worker的上限值,並且可以根據SQLSERVER工作負荷創建或釋放worker,每次worker都會去運行一個完整的任務(task)。在任務做完之前不會退出,除非這個任務主動進入等待狀態。
scheduler只在有新任務要運行,而當前沒有空閒的worker的情況下,才會創建新的worker。
某個worker空閒超過15分鐘,scheduler可能會刪除這個worker,以及其對應的線程。當SQLSERVER遇到內存壓力的時,也會大量刪除處於空閒狀態的worker,以節省multi-page的內存開銷各種CPU和SQLSERVER版本組合自動配置的最大工作線程數CPU數 32位計算機 64位計算機
<=4 256 512
8 288 576
16 352 704
32 480 960
task
在worker上運行的最小任務單元。最簡單的task就是一個簡單batch。例如,客戶發過來下面的請求:
SELECT @@SERVERNAME
GO
SELECT GETDATE()
GO
那麼這兩個batch就分別是兩個task。SQLSERVER會先分配給第一個batch(select @@servername)一個worker,將結果返回給客戶端,再分配第二個batch
(select getdate())一個worker。這兩個worker可能是不同的worker,甚至在不同的scheduler上只要一個task開始運行,他就不會從這個worker上被移出。例如,如果一個select語句被其他連接阻塞住,worker就不能繼續運行,只能進入等待狀態。但是這個select task 不會將這個worker釋放,讓他做其他任務。所以結果是這個worker所對應的線程會進入等待狀態
yielding
SQLOS的任務調度算法的核心,就是所有在邏輯scheduler上運行的worker都是非搶占式的 (non-preemptive)。worker始終在scheduler上運行,直到他運行結束,或者主動將scheduler讓出給其他worker為止。這個“讓出”scheduler的動作,我們叫yieding每個scheduler都會有一個runnable列表,所有等待CPU運行的worker都會在這個列表裡排隊,以先進先出的算法,等待SQL分配給他scheduler運行SQLSERVER定義了很多yieding的規則,約束一個task在scheduler運行的時間。如果task比較復雜,不能很快完成,會保證task在合適的時間點做yieding,不至於占用scheduler太多時間。
常見時間點:
1、當worker每次要去讀數據頁的時候,SQLSERVER會檢查這個worker已經在scheduler上運行了多久,如果已經超過4ms,就做yielding
2、每做64KB的結果集排序,就會做一次yielding
3、在做語句編譯compile的過程中(這個過程比較占CPU資源),經常會有yieding
4、如果客戶端不能及時把結果集取走,worker就會做yieding
5、一個batch裡的每一句話做完,都會做一次yieding
正常來講,哪怕一個task要做很久,他使用的worker是會經常做yieding的,不會長時間占用CPU不放。如果在一個scheduler上同時有很多worker要運行,SQLSERVER通過worker自動yielding的方式調度並發運行。這個比Windows用上下文切換context switch更有效
另附一張手繪圖
另外推薦一篇 SQL SERVER SQLOS的任務調度 微軟亞太的官方博客
我們大概了解了一下SQL SERVER SQLOS的任務調度 我們回到我們的並行話題看一下這個並行執行的調度情況:
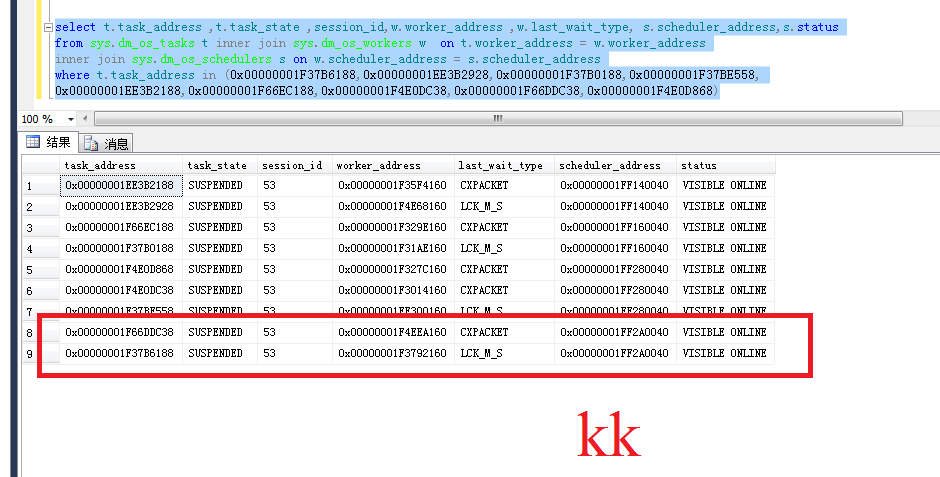
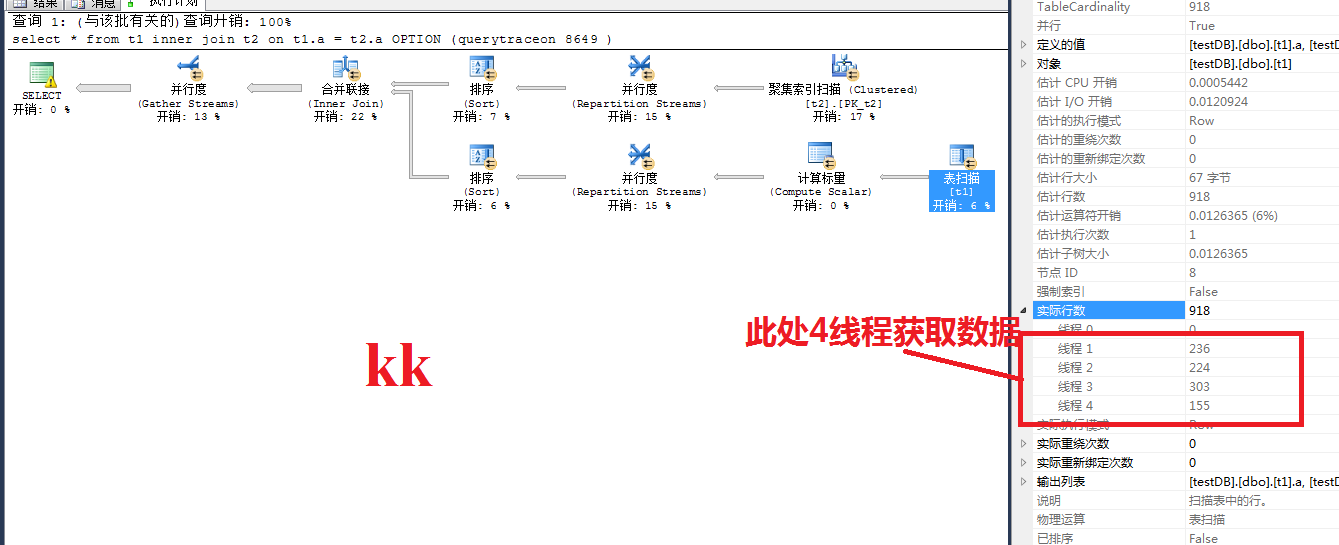
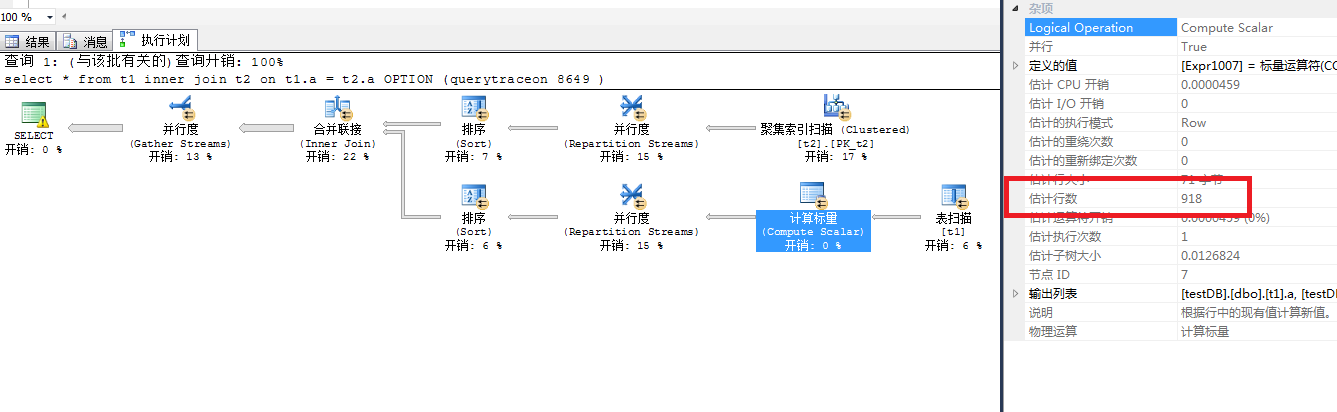
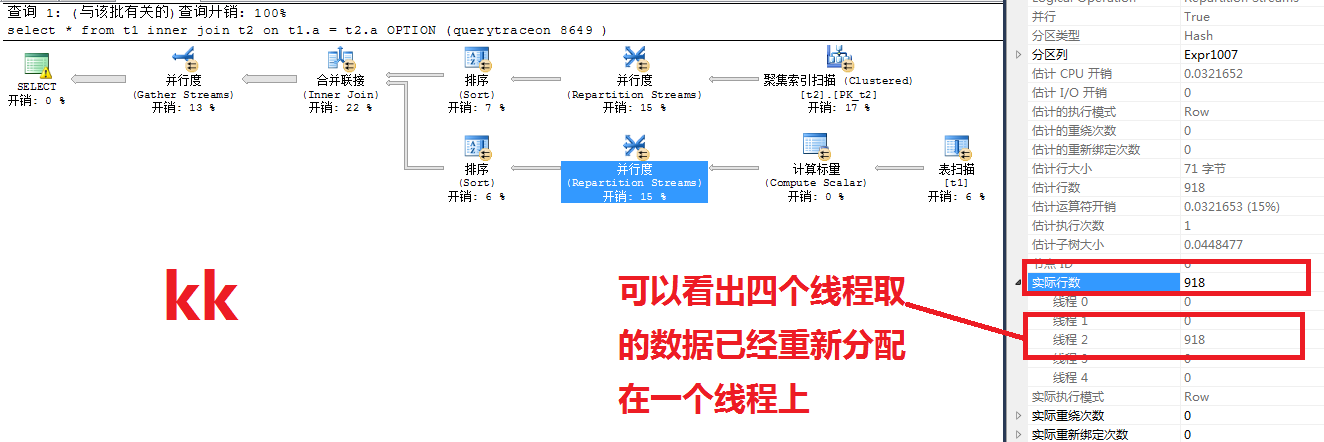
一個並行處理分配給了9個task,同時也啟用了9個worker,由4個scheduler調度,每個scheduler分別由一個申請數據,另一個等待。那麼申請數據的是可以理解的,等待的是干什麼的呢?個人理解和當前的執行計劃有關,4個線程取得數據後要做匯總的操作SQL不會等待數據獲取以後再開啟線程接收,而是接收線程在獲取數據的時候等待。
疑問得到解決了麼?因為已經標記為中篇,可見還是有疑問呀!!!!我們繼續下一篇吧....