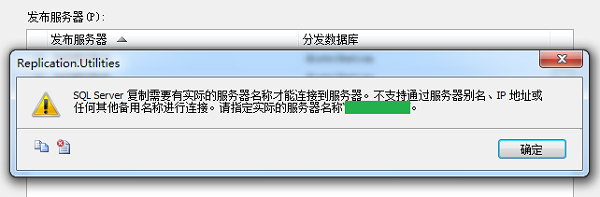
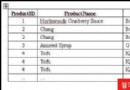
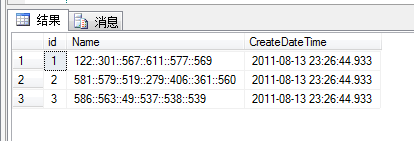
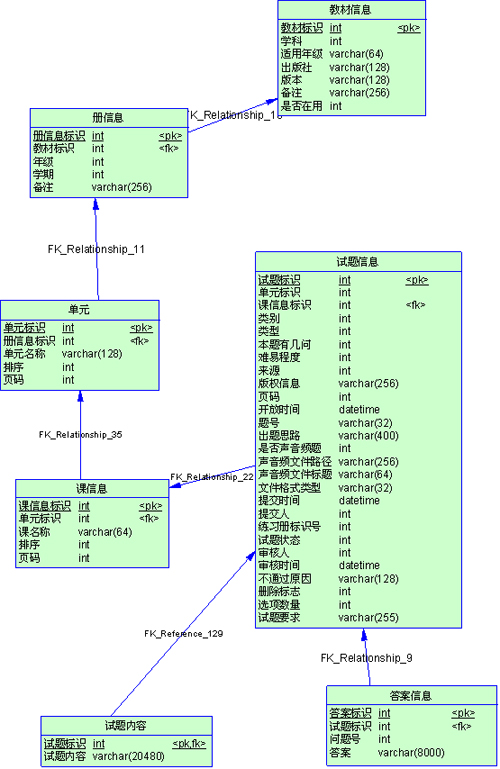
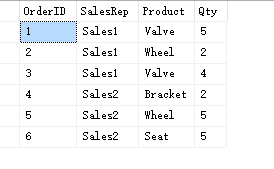
數據庫中刪除重復記錄一直是件挺煩人的事,本人收集了Ora
新增的APPLY表運算符把右表表達式應用到左表表達式
接上篇Mysql數據庫性能優化二對表進行水平劃分
Sql Server 2016 有一個新功能叫 Row-Le
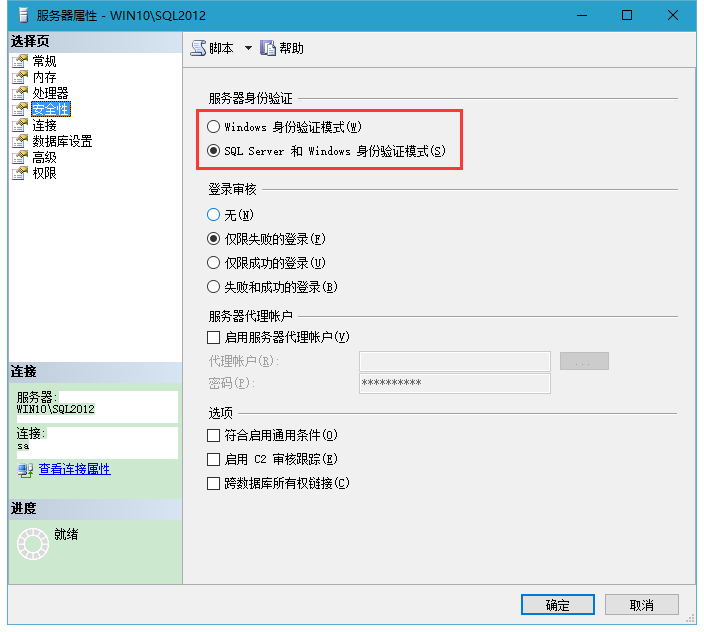
在保密你的服務器和數據,防備當前復雜的攻擊,SQL Serv
想必每個DBA都喜歡挑戰數據導入時間,用時越短工作效率越高