為了速度和正確性,請對齊你的數據.
概述:對於所有直接操作內存的程序員來說,數據對齊都是很重要的問題.數據對齊對你的程序的表現甚至能否正常運行都會產生影響.就像本文章闡述的一樣,理解了對齊的本質還能夠解釋一些處理器的"奇怪的"行為.
內存存取粒度
程序員通常傾向於認為內存就像一個字節數組.在C及其衍生語言中,char * 用來指代"一塊內存",甚至在JAVA中也有byte[]類型來指代物理內存.

Figure 1. 程序員是如何看內存的
然而,你的處理器並不是按字節塊來存取內存的.它一般會以雙字節,四字節,8字節,16字節甚至32字節為單位來存取內存.我們將上述這些存取單位稱為內存存取粒度.

Figure 2. 處理器是如何看內存的
高層(語言)程序員認為的內存形態和處理器對內存的實際處理方式之間的差異產生了許多有趣的問題,本文旨在闡述這些問題.
如果你不理解內存對齊,你編寫的程序將有可能產生下面的問題,按嚴重程度遞增:
程序運行速度變慢
應用程序產生死鎖
操作系統崩潰
你的程序會毫無征兆的出錯,產生錯誤的結果(silently fail如何翻譯?)
內存對齊基礎
為了說明內存對齊背後的原理,我們考察一個任務,並觀察內存存取粒度是如何對該任務產生影響的.這個任務很簡單:先從地址0讀取4個字節到寄存器,然後從地址1讀取4個字節到寄存器.
首先考察內存存取粒度為1byte的情況:

Figure 3. 單字節存取
這迎合了那些天真的程序員的觀點:從地址0和地址1讀取4字節數據都需要相同的4次操作.現在再看看存取粒度為雙字節的處理器(像最初的68000處理器)的情況:

Figure 4. 雙字節存取
從地址0讀取數據,雙字節存取粒度的處理器讀內存的次數是單字節存取粒度處理器的一半.因為每次內存存取都會產生一個固定的開銷,最小化內存存取次數將提升程序的性能.
但從地址1讀取數據時由於地址1沒有和處理器的內存存取邊界對齊,處理器就會做一些額外的工作.地址1這樣的地址被稱作非對齊地址.由於地址1是非對齊的,雙字節存取粒度的處理器必須再讀一次內存才能獲取想要的4個字節,這減緩了操作的速度.
最後我們再看一下存取粒度為4字節的處理器(像68030,PowerPC® 601)的情況:
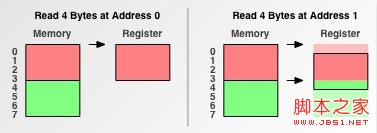
Figure 5. 四字節存取
在對齊的內存地址上,四字節存取粒度處理器可以一次性的將4個字節全部讀出;而在非對齊的內存地址上,讀取次數將加倍.
既然你理解了內存對齊背後的原理,那麼你就可以探索該領域相關的一些問題了.
懶惰的處理器
處理器對非對齊內存的存取有一些技巧.考慮上面的四字節存取粒度處理器從地址1讀取4字節的情況,你肯定想到了下面的解決方法:
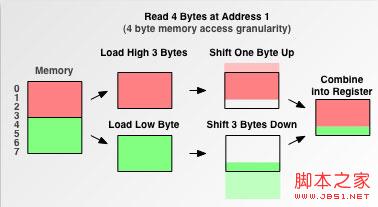
Figure 6. 處理器如何處理非對齊內存地址
處理器先從非對齊地址讀取第一個4字節塊,剔除不想要的字節,然後讀取下一個4字節塊,同樣剔除不要的數據,最後留下的兩塊數據合並放入寄存器.這需要做很多工作.
有些處理器並不情願為你做這些工作.
最初的68000處理器的存取粒度是雙字節,沒有應對非對齊內存地址的電路系統.當遇到非對齊內存地址的存取時,它將拋出一個異常.最初的Mac OS並沒有妥善處理這個異常,它會直接要求用戶重啟機器.悲劇.
隨後的680x0系列,像68020,放寬了這個的限制,支持了非對齊內存地址存取的相關操作.這解釋了為什麼一些在68020上正常運行的舊軟件會在68000上崩潰.這也解釋了為什麼當時一些老Mac編程人員會將指針初始化成奇數地址.在最初的Mac機器上如果指針在使用前沒有被重新賦值成有效地址,Mac會立即跳到調試器.通常他們通過檢查調用堆棧會找到問題所在.
所有的處理器都使用有限的晶體管來完成工作.支持非對齊內存地址的存取操作會消減"晶體管預算",這些晶體管原本可以用來提升其他模塊的速度或者增加新的功能.
以速度的名義犧牲非對齊內存存取功能的一個例子就是MIPS.為了提升速度,MIPS幾乎廢除了所有的瑣碎功能.
PowerPC各取所長.目前所有的PowPC都硬件支持非對齊的32位整型的存取.雖然犧牲掉了一部分性能,但這些損失在逐漸減少.
另一方面,現今的PowPC處理器缺少對非對齊的64-bit浮點型數據的存取的硬件支持.當被要求從非對齊內存讀取浮點數時,PowerPC會拋出異常並讓操作系統來處理內存對齊這樣的雜事.軟件解決內存對齊要比硬件慢得多.
psting 1. 每次處理一個字節
代碼如下:
void Munge8( void *data, uint32_t size ){
uint8_t *data8 = (uint8_t*)data;
uint8_t *data8End = data8 +size;
while( data8 != data8End ){
*data8++ = -*data8;
}
}
運行這個函數需要67364微秒,現在修改成每次處理2個字節,這將使存取次數減半:
psting 2.每次處理2個字節
代碼如下:
void Munge16( void *data, uint32_t size ){
uint16_t *data16 = (uint16_t*)data;
uint16_t *data16End = data16 + (size>> 1); /* Divide size by 2. */
uint8_t *data8 = (uint8_t*)data16End;
uint8_t *data8End = data8 + (size& 0x00000001); /* Strip upper 31 bits. */
while( data16 != data16End ){
*data16++ = -*data16;
}
while( data8 != data8End ){
*data8++ = -*data8;
}
}
如果處理的內存地址是對齊的話,上述函數處理同一個緩沖區需要48765微秒--比Munge8快38%.如果緩沖區不是對齊的,處理時間會增加到66385微秒--比對齊情況下慢了27%.下圖展示了對齊內存和非對齊內存之間的性能對比.
速度
下面編寫一些測試來說明非對齊內存對性能造成的損失.過程很簡單:從一個10MB的緩沖區中讀取,取反,並寫回數據.這些測試有兩個變量:
處理緩沖區的處理粒度,單位bytes. 一開始每次處理1個字節,然後2個字節,4個字節和8個字節.
緩沖區的對准. 用每次增加緩沖區的指針來交錯調整內存地址,然後重新做每個測試.
這些測試運行在800MHz的PowerBook G4上.為了最小化中斷引起的波動,這裡取十次結果的平均值.第一個是處理粒度為單字節的情況:
psting 1. 每次處理一個字節
代碼如下:
void Munge8( void *data, uint32_t size ){
uint8_t *data8 = (uint8_t*)data;
uint8_t *data8End = data8 +size;
while( data8 != data8End ){
*data8++ = -*data8;
}
}
運行這個函數需要67364微秒,現在修改成每次處理2個字節,這將使存取次數減半:
psting 2.每次處理2個字節
代碼如下:
void Munge16( void *data, uint32_t size ){
uint16_t *data16 = (uint16_t*)data;
uint16_t *data16End = data16 + (size>> 1); /* Divide size by 2. */
uint8_t *data8 = (uint8_t*)data16End;
uint8_t *data8End = data8 + (size& 0x00000001); /* Strip upper 31 bits. */
while( data16 != data16End ){
*data16++ = -*data16;
}
while( data8 != data8End ){
*data8++ = -*data8;
}
}
如果處理的內存地址是對齊的話,上述函數處理同一個緩沖區需要48765微秒--比Munge8快38%.如果緩沖區不是對齊的,處理時間會增加到66385微秒--比對齊情況下慢了27%.下圖展示了對齊內存和非對齊內存之間的性能對比.
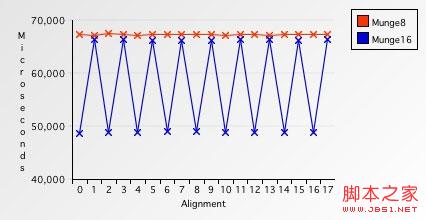
Figure7. 單字節存取 vs.雙字節存取
第一個讓人注意到的現象是單字節存取結果很均勻,且都很慢.第二個是雙字節存取時,每當地址是單數時,變慢的27%就會出現.
下面加大賭注,每次處理4個字節:
psting 3. 每次處理4個字節
代碼如下:
void Munge32( void *data, uint32_t size ){
uint32_t *data32 = (uint32_t*)data;
uint32_t *data32End = data32 + (size>> 2); /* Divide size by 4. */
uint8_t *data8 = (uint8_t*)data32End;
uint8_t *data8End = data8 + (size& 0x00000003); /* Strip upper 30 bits. */
while( data32 != data32End ){
*data32++ = -*data32;
}
while( data8 != data8End ){
*data8++ = -*data8;
}
}
對於對齊的緩沖區,函數需要43043微秒;對於非對齊的緩沖區,函數需要55775微秒.因此,在所測試的機器上,非對齊地址的四字節存取速度比對齊地址的雙字節存取速度要慢.
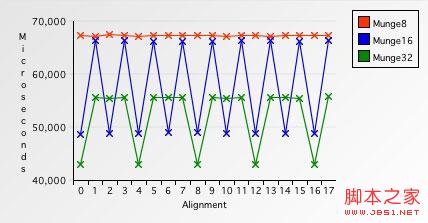
Figure8. 單字節vs.雙字節vs.四字節存取
現在來最恐怖的:每次處理8個字節:
psting 4.每次處理8個字節
代碼如下:
void Munge64( void *data, uint32_t size ){
double *data64 = (double*)data;
double *data64End = data64 + (size>> 3); /* Divide size by 8. */
uint8_t *data8 = (uint8_t*)data64End;
uint8_t *data8End = data8 + (size& 0x00000007); /* Strip upper 29 bits. */
while( data64 != data64End ){
*data64++ = -*data64;
}
while( data8 != data8End ){
*data8++ = -*data8;
}
}
Munge64處理對齊的緩沖區需要39085微秒--大約比對齊的Munge32快10%.但是,在非對齊緩沖區上的處理時間是讓人驚訝的1841155微秒--比對齊的慢了兩個數量級,慢了足足4610%.
怎麼回事?因為我們現今所使用的PowerPC缺少對存取非對齊內存的浮點數的硬件支持.對每次非對齊內存的存取,處理器都拋出一個異常.操作系統獲取該異常並軟件實現內存對齊.下圖顯示了非對齊內存存取帶來的不利後果.
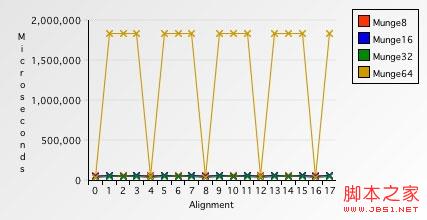
Figure 9. 多字節存取對比
單字節,雙字節和四字節的細節都被掩蓋了.或許去除頂部以後的圖形,如下圖,更清晰:

Figure 10. 多字節存取對比 #2
在這些數據背後還隱藏著一個微妙的現象.比較8字節粒度時邊界是4的倍數的內存的存取速度:

Figure10. 多字節存取對比 #3
你會發現8字節粒度時邊界為4和12字節的內存存取速度要比相同情況下的4和2字節粒度的慢.即使PowerPC硬件支持4字節對齊的8字節雙浮點型數據的存取,你還是要承擔額外的開銷造成的損失.誠然,這種損失絕不會像4610%那麼大,但還是不能忽略的.這個實驗告訴我們:存取非對齊內存時,大粒度的存取可能會比小粒度存取還要慢