先說個題外話:早些年我學C程序設計時,寫過一段解釋硬盤MBR分區表的代碼,對著磁盤編輯器怎麼看,怎麼對,可一執行,結果就錯了。當時調試也不太會,又根本沒聽過結構體對齊這一說,所以,問題解決不了,好幾天都十分糾結。後來萬般無奈請教一個朋友,才獲悉可能是結構體對齊的事,一查、一改,果真如此。
問題是解決了,可網上的資料多數只提到內存對齊是如何做的,卻鮮有提及為什麼這樣做(即使提,也相當簡單)。筆者是個超級健忘者,很難機械式的記住這些破規則,於是仔細想了想,總算明白了原因,這樣,這些對齊的規則也就不會再輕易忘記了。
不光結構體存在內存對齊一說,類(對象)也如此,甚至於所有變量在內存中的存儲也有對齊一說(只是這些對程序員是透明的,不需要關心)。實際上,這種對齊是為了在空間與復雜度上達到平衡的一種技術手段,簡單的講,是為了在可接受的空間浪費的前提下,盡可能的提高對相同運算過程的最少(快)處理。先舉個例子:
假設機器字長是32位的(即4字節,下面示例均按此字長),也就是說處理任何內存中的數據,其實都是按32位的單位進行的。現在有2個變量:
char A;
int B;
假設這2個變量是從內存地址0開始分配的,如果不考慮對齊,應該是這樣存儲的(見下圖,以intel上的little endian為例,為了形象,每16個字節分做一行,後同):

因為計算機的字長是4字節的,所以在處理變量A與B時的過程可能大致為:
A:將0x00-0x03共32位讀入寄存器,再通過左移24位再右移24位運算得到a的值(或與0x000000FF做與運算)
B:將0x00-0x03這32位讀入寄存器,通過位運算得到低24位的值;再將0x04-0x07這32位讀入寄存器,通過位運算得到高8位的值;再與最先得到的24位做位運算,才可得到整個32位的值。
上面敘述可知,對a的處理是最簡處理,可對b的處理,本身是個32位數,處理的時候卻得折成2部分,之後再合並,效率上就有些低了。
想解決這個問題,就需要付出幾個字節浪費的代價,改為下圖的分配方式:

按上面的分配方式,A的處理過程不變;B卻簡單得多了:只需將0x04-0x07這32位讀入寄存器就OK了。
我們可以具體談結構體或類成員的對齊了:
結構體在編譯成機器代碼後,其實就沒有本身的集合概念了,而類,實際上是個加強版的結構體,類的對象在實例化時,內存中申請的就是一些變量的空間集合(類似於結構體,同時也不包含函數指針)。這些集合中的每個變量,在使用中,都需要涉及上述的加工原則,自然也就需要在效率與空間之間做出權衡。
為了便捷加工連續多個相同類型原始變量,同時簡化原始變量尋址,再匯總上述最少處理原則,通常可以將原始變量的長度做為針對此變量的分配單位,比如內存可用64個單元,如果某原始變量長度為8字節,即使機器字長為4字節,分配的時候也以8字節對齊(看似IO次數是相同的),這樣,尋址、分配時,均可以按每8字節為單位進行,簡化了操作,也可以更高效。
系統默認的對齊規則,追求的至少兩點:1、變量的最高效加工 2、達到目的1的最少空間
舉個例子,一個結構體如下:
//by www.datahf.net zhangyu
typedef struct T
{
char c; //本身長度1字節
__int64 d; //本身長度8字節
int e; //本身長度4字節
short f; //本身長度2字節
char g; //本身長度1字節
short h; //本身長度2字節
};
假設定義了一個結構體變量C,在內存中分配到了0x00的位置,顯然:
對於成員C.c 無論如何,也是一次寄存器讀入,所以先占一個字節。
對於成員C.d 是個64位的變量,如果緊跟著C.c存儲,則讀入寄存器至少需要3次,為了實現最少的2次讀入,至少需要以4字節對齊;同時對於8字節的原始變量,為了在尋址單位上統一,則需要按8字節對齊,所以,應該分配到0x08-0xF的位置。
對於成員C.e 是個32位的變量,自然只需滿足分配起始為整數個32位即可,所以分配至0x10-0x13。
對於成員C.f 是個16位的變量,直接分配在0x14-0x16上,這樣,反正只需一次讀入寄存器後加工,邊界也與16位對齊。
對於成員C.g 是個8位的變量,本身也得一次讀入寄存器後加工,同時對於1個字節的變量,存儲在任何字節開始都是對齊,所以,分配到0x17的位置。
對於成員C.h 是個16位的變量,為了保證與16位邊界對齊,所以,分配到0x18-0x1A的位置。
分配圖如下(還不正確,耐心讀下去):

結構體C的占用空間到h結束就可以了嗎?我們找個示例:如果定義一個結構體數組 CA[2],按變量分配的原則,這2個結構體應該是在內存中連續存儲的,分配應該如下圖:

分析一下上圖,明顯可知,CA[1]的很多成員都不再對齊了,究其原因,是結構體的開始邊界不對齊。
那結構體的開始偏移滿足什麼條件才可以使其成員全部對齊呢。想一想就明白了:很簡單,保證結構體長度是原始成員最長分配的整數倍即可。
上述結構體應該按最長的.d成員對齊,即與8字節對齊,這樣正確的分配圖如下:

當然結構體T的長度:sizeof(T)==0x20;
再舉個例子,看看在默認對齊規則下,各結構體成員的對齊規則:
//by www.datahf.net zhangyu
typedef struct A
{
char c; //1個字節
int d; //4個字節,要與4字節對齊,所以分配至第4個字節處
short e; //2個字節, 上述兩個成員過後,本身就是與2對齊的,所以之前無填充
}; //整個結構體,最長的成員為4個字節,需要總長度與4字節對齊,所以, sizeof(A)==12
typedef struct B
{
char c; //1個字節
__int64 d; //8個字節,位置要與8字節對齊,所以分配到第8個字節處
int e; //4個字節,成員d結束於15字節,緊跟的16字節對齊於4字節,所以分配到16-19
short f; //2個字節,成員e結束於19字節,緊跟的20字節對齊於2字節,所以分配到20-21
A g; //結構體長為12字節,最長成員為4字節,需按4字節對齊,所以前面跳過2個字節,
//到24-35字節處
char h; //1個字節,分配到36字節處
int i; //4個字節,要對齊4字節,跳過3字節,分配到40-43 字節
}; //整個結構體的最大分配成員為8字節,所以結構體後面加5字節填充,被到48字節。故:
//sizeof(B)==48;
具體的分配圖如下:

上述全部測試代碼如下:
//by www.datahf.net zhangyu
#include "stdio.h"
typedef struct A
{
char c;
int d;
short e;
};
typedef struct B
{
char c;
__int64 d;
int e;
short f;
A g;
char h;
int i;
};
typedef struct C
{
char c;
__int64 d;
int e;
short f;
char g;
short h;
};
typedef struct D
{
char a;
short b;
char c;
};
int main()
{
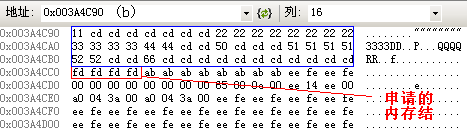
B *b=new B;
void *s[32];
s[0]=b;
s[1]=&b->c;
s[2]=&b->d;
s[3]=&b->e;
s[4]=&b->f;
s[5]=&b->g;
s[6]=&b->h;
s[7]=&b->g.c;
s[8]=&b->g.d;
s[9]=&b->g.e;
s[10]=&b->i;
b->c= 0x11;
b->d= 0x2222222222222222;
b->e= 0x33333333;
b->f=0x4444;
b->g.c=0x50;
b->g.d=0x51515151;
b->g.e=0x5252;
b->h=0x66;
int i1=sizeof(A);
int i2=sizeof(B);
int i3=sizeof(C);
int i4=sizeof(D);
printf("i1:%d\ni2:%d\ni3:%d\ni4:%d\n",i1,i2,i3,i4);//12 48 32 6
}
運行時的內存情況如下圖:
最後,簡單加工一下轉載過來的內存對齊正式原則:
先介紹四個概念:
1)數據類型自身的對齊值:基本數據類型的自身對齊值,等於sizeof(基本數據類型)。
2)指定對齊值:#pragma pack (value)時的指定對齊值value。
3)結構體或者類的自身對齊值:其成員中自身對齊值最大的那個值。
4)數據成員、結構體和類的有效對齊值:自身對齊值和指定對齊值中較小的那個值。
有效對齊值N是最終用來決定數據存放地址方式的值,最重要。有效對齊N,就是表示“對齊在N上”,也就是說該數據的"存放起始地址%N=0".而數據結構中的數據變量都是按定義的先後順序來排放的。第一個數據變量的起始地址就是 數據結構的起始地址。結構體的成員變量要對齊排放,結構體本身也要根據自身的有效對齊值圓整(就是結構體成員變量占用總長度需要是對結構體有效對齊值的整 數倍)
#pragma pack (value)來告訴編譯器,使用我們指定的對齊值來取代缺省的。
如#pragma pack (1) /*指定按2字節對齊*/
#pragma pack () /*取消指定對齊,恢復缺省對齊*/
作者“張宇(數據恢復)”