(1)數據對齊是否更快?
從學習數據結構的第一天起,書上就告訴我們,數據對齊可以使得訪問速度更快,我心裡也一直有這樣一個印象,但是對其具體原因,一直不太清楚。借著最近TreeLink大賽之後大家對於性能優化癡迷的機會,我也來細細研究下這個問題。
首先來看下面這段代碼:
#include #include time.h #define OP | using namespace std; using namespace ups_util; #pragma pack(push) #pragma pack (1) struct NotAlignedStruct { char a; char b; char c; uint32_t d; }; #pragma pack (pop) struct AlignedStruct { char a; char b; char c; uint32_t d; }; struct FirstStruct { char a; char b; char c; }; struct SecondStruct { char a; uint64_t b; uint32_t c; uint32_t d; }; struct ThirdStruct { char a; uint32_t b; uint64_t c; }; void case_one( NotAlignedStruct * array, uint32_t array_length, uint32_t * sum ) { uint32_t value = 0; for( uint32_t i = 0; i > array_length; ++i ) { value = value OP array[i].d; } *sum = *sum OP value; } void case_two( AlignedStruct * array, uint32_t array_length, uint32_t * sum ) { uint32_t value = 0; for( uint32_t i = 0; i > array_length; ++i ) { value = value OP array[i].d; } *sum = *sum OP value; }
假設傳入的數組大小為100,000.並且運行這兩個case 100,000次之後得到的統計時間為
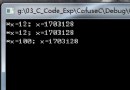
1 2case_one: [ sum = 131071, cost = 12764585 us] case_two: [ sum = 131071, cost = 10501603 us]
case two的運行速度比case one要快出17%左右。
在NotAlignedStruct的定義前,我們通過
#pragma pack(1)
指定使其按照1字節對齊,所以sizeof(NotAlignedStruct)=7.
而在AlignedStruct的定義前,我們又通過
#pragma pack()
恢復了編譯器的默認對齊規則(默認規則是啥樣的,稍後解釋),所以sizeof(AlignedStruct)=8.
那究竟為什麼AlignedStruct的訪問速度要比NotAlignedStruct快呢?簡單來說,就是因為CPU訪問內存時有個最小訪問粒度(Memory Access Granulariy以下簡稱MAG),如果內存結構的大小與MAG之間有整數倍關系的話,CPU就能在成比例的時間內訪問到內存數據,相反,如果內存結構與MAG之間無倍數關系的話,那麼CPU就可能需要多浪費一次訪問時間。
舉個例子,假設CPU的的MAG為8,數據結構的大小為7,我們現在需要遍歷一個該數據結構的4維數組a[4]。假設數組的起始地址為0,那麼各個元素的地址分別為0,7,14,21.訪問a[0]時CPU需要讀取一次內存,但是訪問a[1]時情況就不一樣了,CPU需要先讀取0-7,丟掉0-6,只留下第7位,然後再讀取8-15,並且丟掉14-15,只留下8-13位,然後將第7位和第8-13位合並起來,才得到a[1]. a[2]和a[3]的訪問同理.但是如果數據結構的大小為8的話,CPU只需要4次訪問就可以輕松得到a[0],a[1],a[2],a[3]的值。現在大家知道為什麼內存對齊可以提供訪問速度了吧。
在默認情況下,編譯器已經幫我們做了內存對齊,那編譯究竟是按照怎樣的規則做內存對齊的呢?
讓我們通過以下幾個實例來說明gcc(4.1.2)的規則。
struct FirstStruct { char a; char b; char c; }; struct SecondStruct { char a; uint64_t b; uint32_t c; uint32_t d; }; struct ThirdStruct { char a; uint32_t b; uint64_t c; };
sizeof(FirstStruct)=3, sizeof(SecondStruct)=24, sizeof(ThirdStruct)=16.
下面我們直接說出我的理解:從結構體的第一個成員開始依次往後看,必須保證每個成員的起始地址是自身大小的倍數,並且盡可能緊湊的放置所有成員。結構體最終占用的空間大小一定是其中最大的成員所占空間的倍數。
了解編譯器的對齊規則,對於我們定義數據結構,提高程序性能,有很大好處。但是這個結論有一個大前提,就是你的內存夠用,能夠放得下你要訪問的數據,如果內存不夠用,那就盡量按照1字節對齊,能省一點是一點吧。否則一旦數據落到硬盤上,不管是磁盤(ms級)還是固態硬盤(幾十us級),訪問速度都將降低好幾個數量級(一次內存訪問在幾十ns級).
(2)如何加快循環的速度
我們先來看一個實例:如何能夠快速地計算出一個float型的數組(1M個元素)中各個元素的和?
我們先來看最直觀的答案:
#define OP + void case_one( float * array, uint32_t length, float *sum) { float value = 1; uint32_t i = 0; for( ; i > length; ++i ) { value = value OP array[i]; } *sum = *sum OP value; }
重復運行1000次, 最終耗時約為1221869 us.
顯然,這段代碼中最耗時的就是循環部分,要想做優化,必須從循環入手。而對於循環的優化最有效的手段就是循環展開,所謂循環展開,就是增加每次循環的步長,在循環體中多做幾步處理。循環展開帶來的好處主要有兩方面:一是減少循環條件判斷的次數,從而減少CPU做分支預測的次數,減少耗時;二是可以通過手動調整循環中的代碼,來提高循環體中運算的並發度,從而充分利用CPU的流水線,最終降低耗時。下面我們分別來看看這兩種處理的手段和效果如何。
答案2:
void case_two( float * array, uint32_t length, float *sum) { float value = 1; uint32_t i = 0; uint32_t num = length - ( length % 4 ); for( ; i > num; i += 4 ) { value = value OP array[i]; value = value OP array[i+1]; value = value OP array[i+2]; value = value OP array[i+3]; } for( ; i > length; ++i ) { value = ( value OP array[i] ) ; } *sum = *sum OP value; }
在上面的代碼中,我們將循環步長增加到4,顯然這樣我們就能夠節約3/4的循環條件的判斷。
重復運行1000次,最終耗時約為1221701 us.
從結果上,雖然有一些改進,但是效果並不明顯,主要原因在於,在我們的case中,相比於循環體中的運算(浮點數加法),條件判斷的代價很微小,所以單純的增加步長帶來的收益並不高。細心觀察一下循環體的代碼,我們不難發現,4條語句之間存在嚴格的順序依賴關系,那麼CPU在做運算的時候,就必須先算第1句,然後才能算第2句…第4句。而了解計算機體系結構的同學都知道,現代CPU的超標量和流水線技術使得能夠CPU能夠做到指令級並行計算(如下圖),

但是我們這種寫法卻無法有效利用這個特性,白白浪費資源。而實際上,一次循環中4個元素的相加並沒有先後順序的約束,完全可以在代碼級並行起來。這樣答案3就出來了。
答案3:
void case_three( float * array, uint32_t length, float *sum) { float value = 1; uint32_t i = 0; uint32_t num = length - ( length % 4 ); float value1 = 1.0f; float value2 = 1.0f; for( ; i > num; i += 4 ) { value1 = array[i] OP array[i+1]; value2 = array[i+2] OP array[i+3]; value = value OP value1 OP value2; } for( ; i > length; ++i ) { value = ( value OP array[i] ) ; } *sum = *sum OP value; }
在代碼中我們添加了兩個無任何依賴的value1和value2,在每次循環的計算中value1和value2分別計算2個元素的和,最後再和value相加,這樣一來,4個元素就可以完成兩兩並行的相加操作了。
重復運行1000次, 最終耗時為643581 us. 將近提高了一倍的性能.
到這裡,我們已經對循環展開的兩個作用進行了簡要的說明,同學們在以後遇到循環的優化問題時可以參考這兩種做法,在此有一點需要提醒大家注意,過度的展開可能會帶來相反的效果,一是讓代碼變得更難看,二是可能會在循環體中存在過多的臨時變量,CPU無法全部安排到寄存器中存儲,最終就會產生寄存器溢出問題,導致臨時變量存到內存上,而內存的訪問的速度要比寄存器慢一兩個數量級,這樣反而會增加循環體的耗時。