第5.2.3節 通過“偏移”訪問數組元素和結構體成員
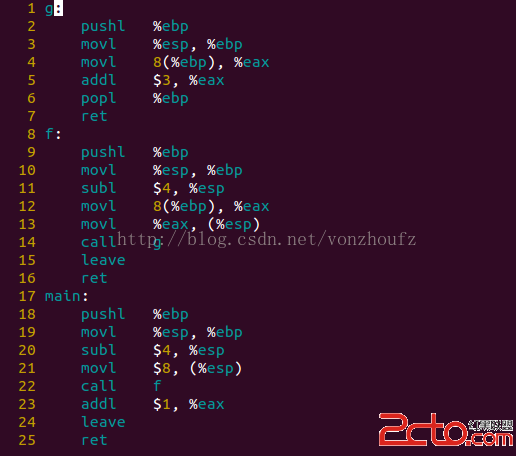
在上一節小節,我們舉例介紹了對“數組元素和結構體成員”的訪問,我們采用的是“基地址+偏移”的模式來計算其內存單元的地址。對於數組元素arr2[i][2]來說,數組索引值i為變量,對應的地址要表達為“基地址+常量偏移+非常量偏移”;對於結構體成員dt.b來說,其地址可表達為“基地址+常量偏移”。下面,我們還是結合一個簡單的例子來說明相關概念,如圖5.2.9所示,第1至14行給出了一個簡單的C程序,第16至30為UCC編譯器生成的中間代碼,第33至46行是UCC編譯器生成的匯編代碼,而第49至58則是GCC編譯器生成的匯編代碼。由於第10行的arr[i]含有“非常量偏移”,C編譯器需要生成代碼來計算這些偏移,再與數組首地址進行相加。在匯編代碼中,用於尋址的指令相當靈活,對於“arr[i]=30;”來說,GCC所生成的代碼就與UCC不同,如圖5.2.9第50至51行所示。UCC編譯器采用的是形如第34至38行的指令,第34至35行用於計算“非常量偏移”,即i*4,通過把i左移2位來實現,第36行通過leal指令來取數組arr的首地址,第37行進行把基地址和偏移相加,所得結果存於寄存器ecx,之後通過第38行的寄存器間接尋址就可完成賦值。第19行的中間代碼“t1:&arr”對應第36行的匯編代碼 “leal arr,%ecx”。我們還發現,第11行的C代碼“arr[2] = 50;”對應的匯編代碼為第40行的“movl $50,arr+8”。在匯編代碼中出現的符號arr可看成是一個地址常量,該movl指令把常數50送到(arr+8)所對應的內存單元中。
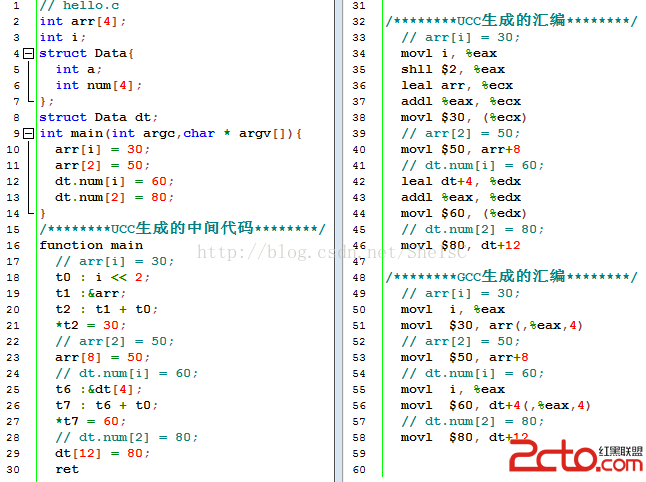
圖5.2.9 對數組元素的尋址
在中間代碼層次,一個符號對象struct symbol(或其“子類”對象,例如struct variableSymbol)可作為三地址碼中的目的操作數或源操作數。UCC編譯器在為“抽象語法樹上的arr結點”生成中間代碼時,並沒有考慮其所處的上下文,為了能生成形如第36行的匯編指令,UCC編譯器需要產生一條形如第19行的中間代碼“t1:&arr;”,其中的臨時變量t1存放了數組arr的首地址。雖然數組中的內容可能會被修改,數組arr的地址在數組生命周期內並不會發生變化,所以&arr可以當作公共子表達式來使用,當我們在第11行遇到另一棵抽象語法子樹上的arr結點時,我們就可重用臨時變量t1中的值。如果t1對應的寄存器為eax,在匯編層次,我們可為第11行的C語句“arr[2]=50;”生成以下匯編代碼。
leal arr, %eax; //取數組arr的地址
addl $8, %eax; //arr[2]在數組arr中的偏移為常量8
movl $50,(%eax); //通過寄存器間接尋址來進行賦值
這些匯編代碼可以實現C語句“arr[2] = 50;”所要求的語義,但並不是很高效,我們可用圖5.2.9第40行的“movl $50,arr+8”來實現一樣的功能。在知道基地址和偏移的前提下,我們可以通過UCC編譯器中的函數Offset,來產生“訪問數組元素或結構體成員”的中間代碼,如圖5.2.9第18至20行所示;而函數AddressOf則可以生成第19行的“t1:&arr;”的取地址指令。
函數Offset的代碼如圖5.2.10所示,當C程序員訪問數組元素或結構體成員時,第2行的參數addr是數組元素或結構體成員的基地址,參數voff是“非常量偏移VariableOffset”。當訪問圖5.2.9第12行的結構體成員dt.num時,由於結構體成員dt.num在結構體對象dt中的偏移是固定的,此時voff參數為NULL。但在訪問dt.num[i]時,數組元素dt.num[i]在數組dt.num中的偏移為(i*4),這不是常量,此時voff不為NULL,而訪問arr[i]時voff也不為NULL。第2行的另一個參數coff代表“常量偏移ConstOffset”,訪問圖5.2.9第11行的arr[2]時,coff的值為2*sizeof(int),即8。圖5.2.10第3至8行的代碼用於產生代碼,進行基地址、非常量偏移和“常量偏移”這三者的加法運算,得到地址後,再由第7行的Deref進行“間接尋址操作”,這樣我們就可以為“arr[i] = 30;”生成形如圖5.2.9第18至21行的中間代碼。當C程序員要訪問arr[2]時,此時圖5.2.10第8行注釋中的t1就對應參數addr,voff為NULL,而coff的值為8,為了能產生形如圖5.2.9第40行的匯編代碼“movl $50,arr+8”,而不是生成“leal arr, %eax; addl $8, %eax; movl $50,(%eax);”這3條低效的代碼,我們在第11行調用CreateOffset函數創建了一個新的符號對象,用來在中間代碼層次表示形如arr[8]這樣的符號。對於圖5.2.10第13至14注釋中所示的代碼而言,ptr是指向int[4]數組的指針,C程序員通過(*ptr)[2]來訪問數組元素時,UCC編譯器會在語義檢查CheckUnaryExpression時構造成一棵形如([] ([] ptr 0) 8)的語法樹,在翻譯這個語法樹時,我們會計算出基地址為ptr,而偏移為8,此時我們把這兩者相加,再通過間接尋址才能訪問到相應的數組元素,第15行調用的Deref完成此功能。如果我們把C程序員寫的(*ptr)[2],錯誤地表示為中間代碼層次的符號ptr[8],則最終生成的匯編代碼會是“movl $50,ptr+8”。假設數組arr的首地址是10000,而全局變量ptr的地址為20000,則變量ptr中的內容為10000,在此movl指令中,ptr是地址常數20000,該movl指令會把常數50傳送到地址20008對應的內存單元。不過,按C的語義,(*ptr)[2]實際應訪問C的數組元素arr[2],數組元素arr[2]的地址為10008,因此“movl $50,ptr+8”是條錯誤的指令。所以,在中間代碼層次,我們不可用符號ptr[8]來表示相應的數組元素(*ptr)[2],而是要生成的形如“t5 : ptr + 8; *t5 = 60;”的代碼,這些中間代碼是通過圖5.2.10第15行的函數Deref來產生,Deref是Dereference的縮寫,表示“提領操作”,也有譯為“解引用”,實際上進行的操作是“間接尋址”。
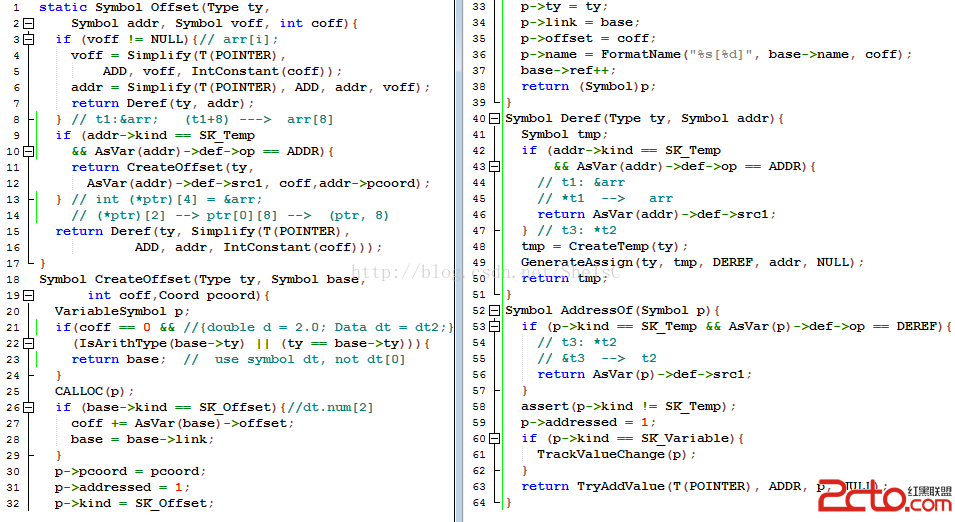
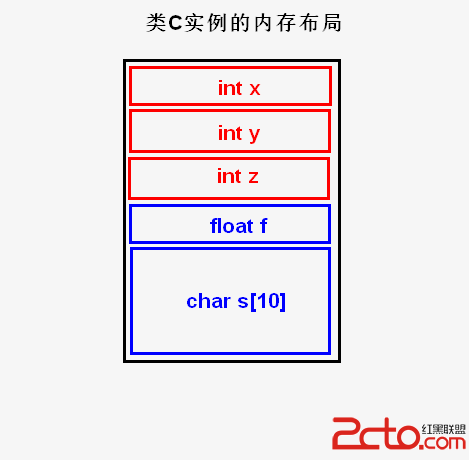
圖5.2.10 Offset()
當要訪問結構體成員dt.num,或者要訪問的數組元素不存在“非常量偏移”(例如arr[2])時,我們可用第18至39行的CreateOffset來為其創建一個符號對象,第18行的base代表基地址,第19行的coff代表“常量偏移”。如果偏移coff為0,比如當我們要初始化圖5.2.10第21行注釋中的局部變量d和dt時,第22行的條件就會成立,此時我們直接返回base即可。但是如果我們要訪問的是dt.a時,按圖5.2.9第4至7行的結構體定義,dt.a在對象dt中的偏移為0,但dt.a和dt的類型不一樣,因此我們需要為dt.a創建一個新的符號對象,而不能使用和dt一樣的符號對象,此時第22行的條件就不成立。第25行用於在堆空間中分配一個符號對象,第30行設該符號在C源代碼中的坐標,第31行置標志位addreesed為1,表示該對象被進行過“取地址操作”(這樣,數組元素和結構體成員作表達式中的操作數時,該表達式就不再被當作公共子表達式,我們在第5.2節介紹過相關概念),第32行設置該符號對象的類型為SK_Offset,第33行設置其類型,第34行保存其基地址對應的符號對象,第35行存放常量偏移,第36行用於生成形如“arr[8]”的符號名。當第18行的參數base本身就對應一個數組元素或者“結構體成員”時,例如dt.num[2]中的dt.num,對於dt.num來說,其基地址為dt,按圖5.2.9第4至7行的定義,dt.num在結構體對象dt中的偏移為4,而數組元素dt.num[2]在數組dt.num中的偏移為8,在中間代碼層次,我們可以把兩者相加,得到dt.num[2]在結構體對象中的偏移為12,圖5.2.10第26至29行的代碼用於完成這些操作。
圖5.2.10第40行的函數Deref主要用來生成一條形如“t3:*t2”的間接尋址指令,其中t2中存放的一個地址,*t2表示取“這個地址對應內存單元中的內容”,並把該內容存於臨時變量t3中,符號t3就作為“間接尋址”的結果返回。當然如果第40行的參數addr形如第44行的t1,而t1由中間代碼“t1:&arr”創建,則間接尋址操作*t1可簡化為對arr的訪問。
而圖5.2.10第52行的函數AddressOf用於在必要時生成形如“t:&num”的取地址指令,其中的num是應是左值(具有C程序員可見的地址)。如果第52行的參數p是進行“間接尋址”後所得的結果t3,其中t3對應的間接尋址指令為“t3: *t2”,則“取地址操作&t3”可簡化為t2,第52至57行的if語句對此進行判斷,此時直接返回t2即可。當num被取地址後,UCC通過調用第61行的TrackValueChange函數,來使以num為操作數的公共子表達式失效。UCC用這樣的策略避免了“別名分析”這樣的復雜過程,當然這會影響生成代碼的質量,UCC編譯器在優化上做得還不夠。由於num在其生命周期內的地址是不會變化的,所以對num進行取地址後的值就可以作為公共子表達式使用,第63行調用的TryAddValue用於此目的。
對一個全局變量或靜態變量number來講,我們可以這樣來理解出現在C程序中的符號number。在C代碼中,我們可把符號number理解為“number相應內存單元中的內容,number位於賦值號右側,則對該內存單元進行讀操作;而number位於賦值號左側時,則對該內存單元進行寫操作”。C程序員如果要獲取該內存單元的地址,則使用表達式&number。
// C代碼,number對應全局靜態區中的一個內存單元
number = 30; //number位於賦值號左側,表示要改寫number的內容
a = number; //number位於賦值號右側,表示要讀取number的內容
但在匯編代碼層次,我們可以把符號number看成是地址常數,在請求分頁的操作系統中,連接器最終會為全局變量和靜態變量分配一個虛空間中的內存單元,相當於把匯編代碼中的符號number替換為一個地址常數。如果要訪問相應內存單元的內容,則使用如下movl指令;而如果要獲取該內存單元的地址,可使用leal指令,如下所示。
// 若全局變量number的地址為0x804a060
movl number, %eax; //寄存器eax中的內容為30
leal number, %ebx; //寄存器ebx中的內容為0x804a060
如果number只是個局部變量,由於其存儲空間位於棧中,是動態分配的,其符號名number根本就不會出現在匯編代碼中,而是用形如“-4(%ebp)”這樣的符號來表示,其中寄存器ebp在運行時會指向棧空間,在編譯時,我們只能算出局部變量number在棧中的偏移,其基地址是未知的,運行時會由寄存器ebp來指向。
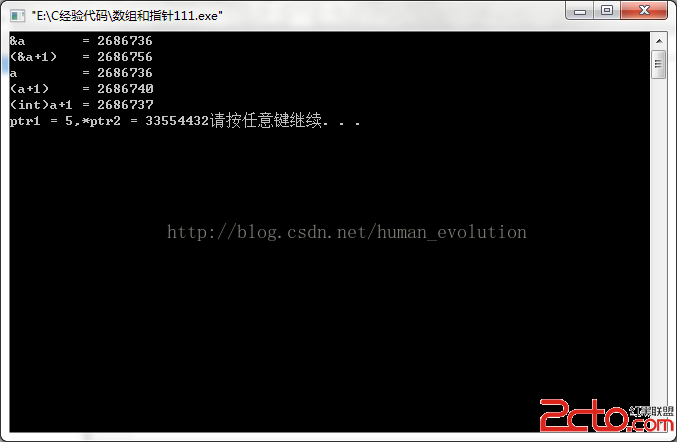
當然在C語言中,數組名是個特例,按照我們前面的理解,在C語言層次,符號arr就應代表數組的內容。但C編譯器會根據上下文來對數組名進行不同的處理,這會造成語義上的不一致。這也是數組名給不少C程序員帶來諸多困惑的源頭,例如arr和&arr到底有何區別之類。對以下數組arr來說,在符號表中,符號arr的類型始終都是int[4]的數組類型,但當符號arr被用在不同場合時,其對應表達式的類型並不一致。
int arr[4];
(1) sizeof(arr) 的值為16,其中的表達式arr為數組類型int[4];
(2) arr+1,這裡的arr被當成數組第0個元素的地址,而arr[0]的類型為int,則&arr[0]的類型為 int *,所以此處表達式arr的類型也為int *
(3) &arr +1, 其中表達式arr的類型為數組類型int[4];
而&arr是指向數組int[4]的指針類型,即int(*)[4]。
我們可以大膽地猜測,C的設計者是出於運行時效率的考慮,才會在一些情況下“把
數組名arr當作第0個數組元素arr[0]的首地址”。例如,在以下函數調用“f(bigArr)”中,若符號bigArr代表的是數組的內容,則在傳參時我們需要傳遞4000字節的數據,這要占用較多的棧空間,同時大量數據的復制也要耗費不少時間。此時,若由C編譯器把f(bigArr)中的bigArr當作bigArr[0]的地址,則只要傳遞一個地址就可以了,同時函數f的形參int num[1000]也可由C編譯器隱式地調整為int * num。但是這並不能完全阻止C程序員傳遞數組的內容,C程序員還是可以寫出如下struct Container,通過給函數k傳遞一個struct Container對象,C編譯器還是會復制其中的數組data。
int bigArr[1000]; void f(int num[1000]){ } void g(void){ f(bigArr); } struct Container{ int data[1000]; }; void k(struct Container d){ }
如果從語義一致上的角度出發,在C語言層次,讓數組名bigArr代表數組中的內容其實也是很好的設計,這或許還更符合“提供機制,而非策略”的思想,C編譯器提供傳參的各種機制,至於C程序員要選用哪一種,也許由C程序員根據應用的上下文來決定會更好些,如下函數聲明h1、h2和h3所示。這可能與設計上的審美有關,不過,當一個決定已成了標准,我們就要嚴格遵守。
void h1(int arr[1000]);
void h2(int * arr);
void h3(int (*ptr)[1000]);
理解了圖5.2.10中的Offset等函數後,由於處理完了“尋址”的問題,我們再來看
tranexpr.c中的表達式翻譯就會輕松許多。在下一小節中,我們將對tranexpr.c中用於翻譯結構體成員訪問的函數CheckMemberAccess,及用於翻譯數組元素訪問的函數CheckPostfixExpression等進行討論。