假如一個人自稱為程序高手,卻對內存一無所知,那麼我可以告訴你,他一定在吹牛。
![]()
![]()
![]()
![]()
<!-- frame contents -->
<!-- /frame contents -->
![]()
![]()
![]()
![]()
用C或C++寫程序,需要更多地關注內存,這不僅僅是因為內存的分配是否合理直接影響著程序的效率和性能,更為主要的是,當我們操作內存的時候一不小心就會出現問題,而且很多時候,這些問題都是不易發覺的,比如內存洩漏,比如懸掛指針。筆者今天在這裡並不是要討論如何避免這些問題,而是想從另外一個角度來熟悉C++內存對象。
我們知道,C++將內存劃分為三個邏輯區域:堆、棧和靜態存儲區。既然如此,我稱位於它們之中的對象分別為堆對象,棧對象以及靜態對象。那麼這些不同的內存對象有什麼區別了?堆對象和棧對象各有什麼優劣了?如何禁止創建堆對象或棧對象了?這些便是今天的主題。
一.基本概念
先來看看棧。棧,一般用於存放局部變量或對象,如我們在函數定義中用類似下面語句聲明的對象:
Type stack_object ;
stack_object便是一個棧對象,它的生命期是從定義點開始,當所在函數返回時,生命結束。
另外,幾乎所有的臨時對象都是棧對象。比如,下面的函數定義:
Type fun(Type object) ;
這個函數至少產生兩個臨時對象,首先,參數是按值傳遞的,所以會調用拷貝構造函數生成一個臨時對象object_copy1 ,在函數內部使用的不是使用的不是object,而是object_copy1,自然,object_copy1是一個棧對象,它在函數返回時被釋放;還有這個函數是值返回的,在函數返回時,假如我們不考慮返回值優化(NRV),那麼也會產生一個臨時對象object_copy2,這個臨時對象會在函數返回後一段時間內被釋放。比如某個函數中有如下代碼:
Type tt ,result ; //生成兩個棧對象
tt = fun(tt) ; //函數返回時,生成的是一個臨時對象object_copy2
上面的第二個語句的執行情況是這樣的,首先函數fun返回時生成一個臨時對象object_copy2 ,然後再調用賦值運算符執行
tt = object_copy2 ; //調用賦值運算符
看到了嗎?編譯器在我們毫無知覺的情況下,為我們生成了這麼多臨時對象,而生成這些臨時對象的時間和空間的開銷可能是很大的,所以,你也許明白了,為什麼對於“大”對象最好用const引用傳遞代替按值進行函數參數傳遞了。
接下來,看看堆。堆,又叫自由存儲區,它是在程序執行的過程中動態分配的,所以它最大的特性就是動態性。在C++中,所有堆對象的創建和銷毀都要由程序員負責,所以,假如處理不好,就會發生內存問題。假如分配了堆對象,卻忘記了釋放,就會產生內存洩漏;而假如已釋放了對象,卻沒有將相應的指針置為NULL,該指針就是所謂的“懸掛指針”,再度使用此指針時,就會出現非法訪問,嚴重時就導致程序崩潰。
那麼,C++中是怎樣分配堆對象的?唯一的方法就是用new(當然,用類malloc指令也可獲得C式堆內存),只要使用new,就會在堆中分配一塊內存,並且返回指向該堆對象的指針。
再來看看靜態存儲區。所有的靜態對象、全局對象都於靜態存儲區分配。關於全局對象,是在main()函數執行前就分配好了的。其實,在main()函數中的顯示代碼執行之前,會調用一個由編譯器生成的_main()函數,而_main()函數會進行所有全局對象的的構造及初始化工作。而在main()函數結束之前,會調用由編譯器生成的exit函數,來釋放所有的全局對象。比如下面的代碼:
void main(void)
{
… …// 顯式代碼
}
實際上,被轉化成這樣:
void main(void)
{
_main(); //隱式代碼,由編譯器產生,用以構造所有全局對象
… … // 顯式代碼
… …
exit() ; // 隱式代碼,由編譯器產生,用以釋放所有全局對象
}
所以,知道了這個之後,便可以由此引出一些技巧,如,假設我們要在main()函數執行之前做某些預備工作,那麼我們可以將這些預備工作寫到一個自定義的全局對象的構造函數中,這樣,在main()函數的顯式代碼執行之前,這個全局對象的構造函數會被調用,執行預期的動作,這樣就達到了我們的目的。 剛才講的是靜態存儲區中的全局對象,那麼,局部靜態對象了?局部靜態對象通常也是在函數中定義的,就像棧對象一樣,只不過,其前面多了個static要害字。局部靜態對象的生命期是從其所在函數第一次被調用,更確切地說,是當第一次執行到該靜態對象的聲明代碼時,產生該靜態局部對象,直到整個程序結束時,才銷毀該對象。
還有一種靜態對象,那就是它作為class的靜態成員。考慮這種情況時,就牽涉了一些較復雜的問題。
第一個問題是class的靜態成員對象的生命期,class的靜態成員對象隨著第一個class object的產生而產生,在整個程序結束時消亡。也就是有這樣的情況存在,在程序中我們定義了一個class,該類中有一個靜態對象作為成員,但是在程序執行過程中,假如我們沒有創建任何一個該class object,那麼也就不會產生該class所包含的那個靜態對象。還有,假如創建了多個class object,那麼所有這些object都共享那個靜態對象成員。
第二個問題是,當出現下列情況時:
class Base
{
public:
static Type s_object ;
}
class Derived1 : public Base / / 公共繼續
{
… …// other data
}
class Derived2 : public Base / / 公共繼續
{
… …// other data
}
Base example ;
Derivde1 example1 ;
Derivde2 example2 ;
example.s_object = …… ;
example1.s_object = …… ;
example2.s_object = …… ;
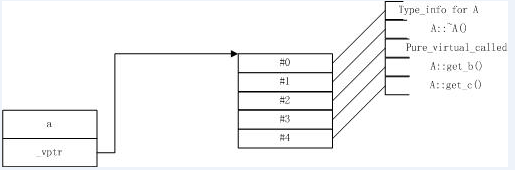
請注重上面標為黑體的三條語句,它們所訪問的s_object是同一個對象嗎?答案是肯定的,它們的確是指向同一個對象,這聽起來不像是真的,是嗎?但這是事實,你可以自己寫段簡單的代碼驗證一下。我要做的是來解釋為什麼會這樣? 我們知道,當一個類比如Derived1,從另一個類比如Base繼續時,那麼,可以看作一個Derived1對象中含有一個Base型的對象,這就是一個subobject。一個Derived1對象的大致內存布局如下:
讓我們想想,當我們將一個Derived1型的對象傳給一個接受非引用Base型參數的函數時會發生切割,那麼是怎麼切割的呢?相信現在你已經知道了,那就是僅僅取出了Derived1型的對象中的subobject,而忽略了所有Derived1自定義的其它數據成員,然後將這個subobject傳遞給函數(實際上,函數中使用的是這個subobject的拷貝)。
所有繼續Base類的派生類的對象都含有一個Base型的subobject(這是能用Base型指針指向一個Derived1對象的要害所在,自然也是多態的要害了),而所有的subobject和所有Base型的對象都共用同一個s_object對象,自然,從Base類派生的整個繼續體系中的類的實例都會共用同一個s_object對象了。上面提到的example、example1、example2的對象布局如下圖所示:
二.三種內存對象的比較
棧對象的優勢是在適當的時候自動生成,又在適當的時候自動銷毀,不需要程序員操心;而且棧對象的創建速度一般較堆對象快,因為分配堆對象時,會調用operator new操作,operator new會采用某種內存空間搜索算法,而該搜索過程可能是很費時間的,產生棧對象則沒有這麼麻煩,它僅僅需要移動棧頂指針就可以了。但是要注重的是,通常棧空間容量比較小,一般是1MB~2MB,所以體積比較大的對象不適合在棧中分配。非凡要注重遞歸函數中最好不要使用棧對象,因為隨著遞歸調用深度的增加,所需的棧空間也會線性增加,當所需棧空間不夠時,便會導致棧溢出,這樣就會產生運行時錯誤。
堆對象,其產生時刻和銷毀時刻都要程序員精確定義,也就是說,程序員對堆對象的生命具有完全的控制權。我們經常需要這樣的對象,比如,我們需要創建一個對象,能夠被多個函數所訪問,但是又不想使其成為全局的,那麼這個時候創建一個堆對象無疑是良好的選擇,然後在各個函數之間傳遞這個堆對象的指針,便可以實現對該對象的共享。另外,相比於棧空間,堆的容量要大得多。實際上,當物理內存不夠時,假如這時還需要生成新的堆對象,通常不會產生運行時錯誤,而是系統會使用虛擬內存來擴展實際的物理內存。
接下來看看static對象。
首先是全局對象。全局對象為類間通信和函數間通信提供了一種最簡單的方式,雖然這種方式並不優雅。一般而言,在完全的面向對象語言中,是不存在全局對象的,比如C#,因為全局對象意味著不安全和高耦合,在程序中過多地使用全局對象將大大降低程序的健壯性、穩定性、可維護性和可復用性。C++也完全可以剔除全局對象,但是最終沒有,我想原因之一是為了兼容C。
其次是類的靜態成員,上面已經提到,基類及其派生類的所有對象都共享這個靜態成員對象,所以當需要在這些class之間或這些class objects之間進行數據共享或通信時,這樣的靜態成員無疑是很好的選擇。
接著是靜態局部對象,主要可用於保存該對象所在函數被屢次調用期間的中間狀態,其中一個最顯著的例子就是遞歸函數,我們都知道遞歸函數是自己調用自己的函數,假如在遞歸函數中定義一個nonstatic局部對象,那麼當遞歸次數相當大時,所產生的開銷也是巨大的。這是因為nonstatic局部對象是棧對象,每遞歸調用一次,就會產生一個這樣的對象,每返回一次,就會釋放這個對象,而且,這樣的對象只局限於當前調用層,對於更深入的嵌套層和更淺露的外層,都是不可見的。每個層都有自己的局部對象和參數。
在遞歸函數設計中,可以使用static對象替代nonstatic局部對象(即棧對象),這不僅可以減少每次遞歸調用和返回時產生和釋放nonstatic對象的開銷,而且static對象還可以保存遞歸調用的中間狀態,並且可為各個調用層所訪問。
三.使用棧對象的意外收獲
前面已經介紹到,棧對象是在適當的時候創建,然後在適當的時候自動釋放的,也就是棧對象有自動治理功能。那麼棧對象會在什麼會自動釋放了?第一,在其生命期結束的時候;第二,在其所在的函數發生異常的時候。你也許說,這些都很正常啊,沒什麼大不了的。是的,沒什麼大不了的。但是只要我們再深入一點點,也許就有意外的收獲了。
棧對象,自動釋放時,會調用它自己的析構函數。假如我們在棧對象中封裝資源,而且在棧對象的析構函數中執行釋放資源的動作,那麼就會使資源洩漏的概率大大降低,因為棧對象可以自動的釋放資源,即使在所在函數發生異常的時候。實際的過程是這樣的:函數拋出異常時,會發生所謂的stack_unwinding(堆棧回滾),即堆棧會展開,由於是棧對象,自然存在於棧中,所以在堆棧回滾的過程中,棧對象的析構函數會被執行,從而釋放其所封裝的資源。除非,除非在析構函數執行的過程中再次拋出異常――而這種可能性是很小的,所以用棧對象封裝資源是比較安全的。基於此熟悉,我們就可以創建一個自己的句柄或代理來封裝資源了。智能指針(auto_ptr)中就使用了這種技術。在有這種需要的時候,我們就希望我們的資源封裝類只能在棧中創建,也就是要限制在堆中創建該資源封裝類的實例。
更多內容請看C/C++技術專題專題,或
四.禁止產生堆對象
上面已經提到,你決定禁止產生某種類型的堆對象,這時你可以自己創建一個資源封裝類,該類對象只能在棧中產生,這樣就能在異常的情況下自動釋放封裝的資源。
那麼怎樣禁止產生堆對象了?我們已經知道,產生堆對象的唯一方法是使用new操作,假如我們禁止使用new不就行了麼。再進一步,new操作執行時會調用operator new,而operator new是可以重載的。方法有了,就是使new operator 為private,為了對稱,最好將operator delete也重載為private。現在,你也許又有疑問了,難道創建棧對象不需要調用new嗎?是的,不需要,因為創建棧對象不需要搜索內存,而是直接調整堆棧指針,將對象壓棧,而operator new的主要任務是搜索合適的堆內存,為堆對象分配空間,這在上面已經提到過了。好,讓我們看看下面的示例代碼:
#include <stdlib.h> //需要用到C式內存分配函數
class Resource ; //代表需要被封裝的資源類
class NoHashObject
{
private:
Resource* ptr ;//指向被封裝的資源
... ... //其它數據成員
void* operator new(size_t size) //非嚴格實現,僅作示意之用
{
return malloc(size) ;
}
void operator delete(void* pp) //非嚴格實現,僅作示意之用
{
free(pp) ;
}
public:
NoHashObject()
{
//此處可以獲得需要封裝的資源,並讓ptr指針指向該資源
ptr = new Resource() ;
}
~NoHashObject()
{
delete ptr ; //釋放封裝的資源
}
};
NoHashObject現在就是一個禁止堆對象的類了,假如你寫下如下代碼:
NoHashObject* fp = new NoHashObject() ; //編譯期錯誤!
delete fp ;
上面代碼會產生編譯期錯誤。好了,現在你已經知道了如何設計一個禁止堆對象的類了,你也許和我一樣有這樣的疑問,難道在類NoHashObject的定義不能改變的情況下,就一定不能產生該類型的堆對象了嗎?不,還是有辦法的,我稱之為“暴力破解法”。C++是如此地強大,強大到你可以用它做你想做的任何事情。這裡主要用到的是技巧是指針類型的強制轉換。
void main(void)
{
char* temp = new char[sizeof(NoHashObject)] ;
//強制類型轉換,現在ptr是一個指向NoHashObject對象的指針
NoHashObject* obj_ptr = (NoHashObject*)temp ;
temp = NULL ; //防止通過temp指針修改NoHashObject對象
//再一次強制類型轉換,讓rp指針指向堆中NoHashObject對象的ptr成員
Resource* rp = (Resource*)obj_ptr ;
//初始化obj_ptr指向的NoHashObject對象的ptr成員
rp = new Resource() ;
//現在可以通過使用obj_ptr指針使用堆中的NoHashObject對象成員了
... ...
delete rp ;//釋放資源
temp = (char*)obj_ptr ;
obj_ptr = NULL ;//防止懸掛指針產生
delete [] temp ;//釋放NoHashObject對象所占的堆空間。
}
上面的實現是麻煩的,而且這種實現方式幾乎不會在實踐中使用,但是我還是寫出來路,因為理解它,對於我們理解C++內存對象是有好處的。對於上面的這麼多強制類型轉換,其最根本的是什麼了?我們可以這樣理解:
某塊內存中的數據是不變的,而類型就是我們戴上的眼鏡,當我們戴上一種眼鏡後,我們就會用對應的類型來解釋內存中的數據,這樣不同的解釋就得到了不同的信息。
所謂強制類型轉換實際上就是換上另一副眼鏡後再來看同樣的那塊內存數據。
另外要提醒的是,不同的編譯器對對象的成員數據的布局安排可能是不一樣的,比如,大多數編譯器將NoHashObject的ptr指針成員安排在對象空間的頭4個字節,這樣才會保證下面這條語句的轉換動作像我們預期的那樣執行:
Resource* rp = (Resource*)obj_ptr ;
但是,並不一定所有的編譯器都是如此。
既然我們可以禁止產生某種類型的堆對象,那麼可以設計一個類,使之不能產生棧對象嗎?當然可以。
五.禁止產生棧對象
前面已經提到了,創建棧對象時會移動棧頂指針以“挪出”適當大小的空間,然後在這個空間上直接調用對應的構造函數以形成一個棧對象,而當函數返回時,會調用其析構函數釋放這個對象,然後再調整棧頂指針收回那塊棧內存。在這個過程中是不需要operator new/delete操作的,所以將operator new/delete設置為private不能達到目的。當然從上面的敘述中,你也許已經想到了:將構造函數或析構函數設為私有的,這樣系統就不能調用構造/析構函數了,當然就不能在棧中生成對象了。
這樣的確可以,而且我也打算采用這種方案。但是在此之前,有一點需要考慮清楚,那就是,假如我們將構造函數設置為私有,那麼我們也就不能用new來直接產生堆對象了,因為new在為對象分配空間後也會調用它的構造函數啊。所以,我打算只將析構函數設置為private。再進一步,將析構函數設為private除了會限制棧對象生成外,還有其它影響嗎?是的,這還會限制繼續。
假如一個類不打算作為基類,通常采用的方案就是將其析構函數聲明為private。
為了限制棧對象,卻不限制繼續,我們可以將析構函數聲明為protected,這樣就兩全其美了。如下代碼所示:
class NoStackObject
{
protected:
~NoStackObject() { }
public:
void destroy()
{
delete this ;//調用保護析構函數
}
};
接著,可以像這樣使用NoStackObject類:
NoStackObject* hash_ptr = new NoStackObject() ;
... ... //對hash_ptr指向的對象進行操作
hash_ptr->destroy() ;
呵呵,是不是覺得有點怪怪的,我們用new創建一個對象,卻不是用delete去刪除它,而是要用destroy方法。很顯然,用戶是不習慣這種怪異的使用方式的。所以,我決定將構造函數也設為private或protected。這又回到了上面曾試圖避免的問題,即不用new,那麼該用什麼方式來生成一個對象了?我們可以用間接的辦法完成,即讓這個類提供一個static成員函數專門用於產生該類型的堆對象。(設計模式中的singleton模式就可以用這種方式實現。)讓我們來看看:
class NoStackObject
{
protected:
NoStackObject() { }
~NoStackObject() { }
public:
static NoStackObject* creatInstance()
{
return new NoStackObject() ;//調用保護的構造函數
}
void destroy()
{
delete this ;//調用保護的析構函數
}
};
現在可以這樣使用NoStackObject類了:
NoStackObject* hash_ptr = NoStackObject::creatInstance() ;
... ... //對hash_ptr指向的對象進行操作
hash_ptr->destroy() ;
hash_ptr = NULL ; //防止使用懸掛指針
現在感覺是不是好多了,生成對象和釋放對象的操作一致了。
ok,講到這裡,已經涉及了較多的東西,假如要把內存對象講得更深入更全面,那可能需要寫成一本書了,而就我自己的功力而言,可能是很難完全把握的。假如上面所寫的能使你有所收獲或啟發,我就滿足了。假如你要更進一步去了解內存對象方面的知識,那麼我可以推薦你看看《深入探索C++對象模型》這本書。
更多內容請看C/C++技術專題專題,或