首先是昨天在北京大學oj網上看到一個簡單的算法題目,雖然簡單,但是如何完成一段高效、簡潔、讓人容易看懂的代碼對於我這個基礎不好,剛剛進入計算機行業的小白來說還是有意義的。而且在寫代碼的過程中,會發現自己平時學習中不會發現的問題,所以想寫下這個博客,主要是便於自己對算法的理解。
來,上題。
DNA Sorting Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 91599 Accepted: 36781Description
One measure of ``unsortedness'' in a sequence is the number of pairs of entries that are out of order with respect to each other. For instance, in the letter sequence ``DAABEC'', this measure is 5, since D is greater than four letters to its right and E is greater than one letter to its right. This measure is called the number of inversions in the sequence. The sequence ``AACEDGG'' has only one inversion (E and D)---it is nearly sorted---while the sequence ``ZWQM'' has 6 inversions (it is as unsorted as can be---exactly the reverse of sorted).Input
The first line contains two integers: a positive integer n (0 < n <= 50) giving the length of the strings; and a positive integer m (0 < m <= 100) giving the number of strings. These are followed by m lines, each containing a string of length n.Output
Output the list of input strings, arranged from ``most sorted'' to ``least sorted''. Since two strings can be equally sorted, then output them according to the orginal order.Sample Input
10 6 AACATGAAGG TTTTGGCCAA TTTGGCCAAA GATCAGATTT CCCGGGGGGA ATCGATGCAT
Sample Output
CCCGGGGGGA AACATGAAGG GATCAGATTT ATCGATGCAT TTTTGGCCAA TTTGGCCAAA
#01、這是一個很簡單的題目,基本上就是看完題目,思路就出來的那種。這個題目主要要解決以下幾個小麻煩。
0X001:存放DNA序列的數據結構,存放這種類型的數據,最好的當然是二維數組啦。m,n是在程序運行過程中用戶輸入的,顯然不能直接char N_DNA[n][m]來定義。
雖然題目中給出了m和n都要小於等於50,但是設一個太大的數組,還有很多空間浪費,作為一個較真的程序員,顯然是心裡過不去的。
如是,我們可以采用下面的方法定義數組,並分配空間。
1 template <typename T>
2 //定義Arr數據類型
3 class Arr
4 {
5 public:
6 Arr(int length)
7 {
8 this->length = length;
9 data = new T[length];
10 }
11 T *data;
12 unsigned int length;
13 };
14 typedef Arr<char>* P_of_Arr;//P_of_Arr是一維Arr數組的指針類型
15 void main()
16 {
17 int m, n;
18 scanf("%d %d", &m, &n);
19 //構造N_DNA數組
20 Arr<P_of_Arr> N_DNA(n);
21 //給N_DNA的data數組的每個指針分配空間
22 int t;
23 for (t = 0; t < n; t++)
24 {
25 N_DNA.data[t] = new Arr<char>(m);
26 }
27 }
這裡面主要用到兩個c++的知識,寫出來,加強一下自己的理解。
其一就是temptale的使用,關鍵字template在這裡的作用讓class Arr的類型多向化,就是讓class Arr可以有多種理解,就是讓class Arr成為一個模板,當在其他一些相似但是又不相同的環境下可以被再次使用。通俗點講,就是先假裝,T是已經定義的類型。讓編譯器認可它,不報錯。在Arr定義變量的時候,再來補上T的類型。因此,這樣用template模板定義的類型,可以在不同的類型T的環境中使用。
其二是new的使用,首先我們定義一個Arr數組Arr<P_of_Arr> N_DNA(n);我們可以看到Arr構造函數裡面,this->length = length;data = new T[length];將n傳給Arr域裡面的length,並且分配一個T[n]空間的數組,並把指針傳給data(注意,這裡data是二重指針,也就是數組是data[n],其中data[0,1....n]也是指針,因為定義Arr時,T是P_of_Arr,而typedef Arr<char>* P_of_Arr;//P_of_Arr是一維Arr數組的指針類型)。
int t;
for (t = 0; t < n; t++)
{
N_DNA.data[t] = new Arr<char>(m);
}
然後我們循環,依次給data[0,1...n]分配空間.每一個data[i]指向一個一維的Arr類型的數據。
至此,我們就分配了N_DNA.data[n]->data[m]的數組。
#02數據的輸入,cin的理解,cin是C++庫函數裡面的一系列函數,cin>>/cin.get/cin.getline...這些函數的用法在這裡不再贅述。
可以參考以下兩篇博客,裡面講的比較清楚
個人體會就是在使用和理解這些函數時,了解兩個方面問題。
第一、space,tab,Enter是否被從緩沖區中捨棄。<sapce,tab,Enter>
第二、cin.getline在超出范圍時,通過怎樣影響輸入標志位,來影響後續的輸入。<failbit,eofbit,badbit//goodbit>
參考博客:
http://www.cnblogs.com/A-Song/archive/2012/01/29/2331204.html
http://blog.csdn.net/dongtingzhizi/article/details/2299365
之後就是非常常規簡單的代碼了,定義一個數組rel記錄DNA的逆值,然後依次按照逆值從小到大輸出DNA序列。
完全的代碼如下:
1 #define _CRT_SECURE_NO_WARNINGS
2 #include<iostream>
3 using namespace std;
4 #define MAX 12768
5 template <typename T>
6 class Arr
7 {
8 public:
9 Arr(int length)
10 {
11 this->length = length;
12 data = new T[length];
13 }
14 T *data;
15 unsigned int length;
16 };
17 typedef Arr<char>* P_of_Arr;
18 int main(void)
19 {
20 int m, n;
21 scanf("%d %d", &m, &n);
22 //構造N_DNA數組
23 Arr<P_of_Arr> N_DNA(n);
24 int t;
25 for (t = 0; t < n; t++)
26 {
27 N_DNA.data[t] = new Arr<char>(m);
28 }
29 int i,j,k;
30 int *rel = new int[n];
31 //輸入DNA序列
32 cin.getline(N_DNA.data[0]->data, m + 1);
33 for (i = 0; i < n; i++)
34 cin.getline(N_DNA.data[i]->data, m+1);
35 //循環遍歷,用rel記錄各個DNA序列的逆值
36 for (k = 0; k < n; k++)
37 {
38 rel[k] = 0;
39 for (i = 0; i < m; i++)
40 for (j = i; j < m; j++)
41 if (N_DNA.data[k]->data[i]>N_DNA.data[k]->data[j])
42 rel[k]++;
43 }
44 int *usedrel = new int[n];//標志rel是否被用
45 //初始化全為0
46 for (i = 0; i < n; i++)
47 usedrel[i] = 0;
48 //查找最小的逆值得DNA序列,並輸出
49 for (i = 0; i < n; i++)
50 {
51 k = -1;//記錄最小逆值的地址
52 int min=MAX;//記錄最小的逆值
53 for (j = 0; j < n; j++)
54 if (rel[j] < min&&usedrel[j]==0)
55 {
56 min = rel[j];
57 k = j;
58 }
59 usedrel[k] = 1;//標記已經被訪問
60 for (j = 0; j < m; j++)
61 cout << N_DNA.data[k]->data[j];
62 cout << endl;
63 }
64 return 0;
65 }
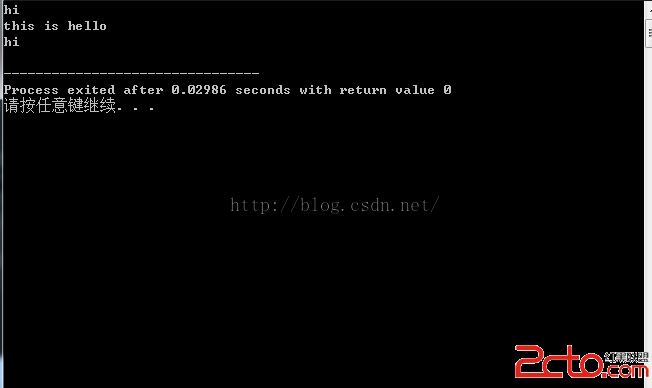
運行結果如下:
 由於題目對於輸入輸出有要求,所以沒有將輸入輸出分開。
由於題目對於輸入輸出有要求,所以沒有將輸入輸出分開。