tokenizer 庫提供預定義好的四個分詞對象, 其中char_delimiters_separator已棄用. 其他如下:
char_separator有兩個構造函數
1 char_separator()
使用函數 std::isspace() 來識別被棄分隔符,同時使用 std::ispunct() 來識別保留分隔符。另外,拋棄空白單詞。(見例2)
1 char_separator(// 不保留的分隔符 2 const Char* dropped_delims, 3 // 保留的分隔符 4 const Char* kept_delims = 0, 5 // 默認不保留空格分隔符, 反之加上改參數keep_empty_tokens 6 empty_token_policy empty_tokens = drop_empty_tokens)
該函數創建一個 char_separator 對象,該對象被用於創建一個 token_iterator 或 tokenizer 以執行單詞分解。dropped_delims 和 kept_delims 都是字符串,其中的每個字符被用作分解時的分隔符。當在輸入序列中遇到一個分隔符時,當前單詞即完成,並開始下一個新單詞。dropped_delims 中的分隔符不出現在輸出的單詞中,而 kept_delims 中的分隔符則會作為單詞輸出。如果 empty_tokens 為 drop_empty_tokens, 則空白單詞不會出現在輸出中。如果 empty_tokens 為 keep_empty_tokens 則空白單詞將出現在輸出中。 (見例3)
escaped_list_separator有兩個構造函數,下面三個字符做為分隔符: '\' , ',' , '"'
1 explicit escaped_list_separator(Char e = '\\', Char c = ',',Char q = '\"');

1 escaped_list_separator(string_type e, string_type c, string_type q):
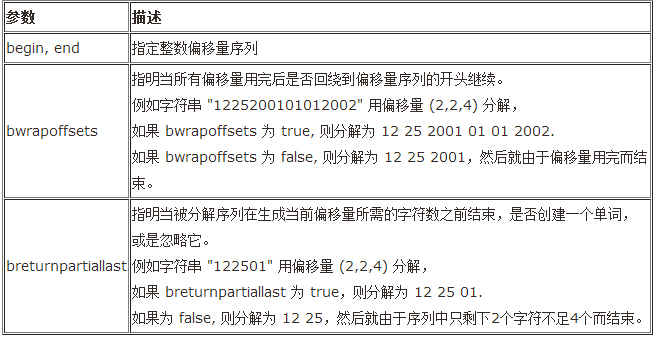
offset_separator 有一個有用的構造函數
1 template<typename Iter> 2 offset_separator(Iter begin,Iter end,bool bwrapoffsets = true, bool breturnpartiallast = true);
1 void test_string_tokenizer()
2 {
3 using namespace boost;
4
5 // 1. 使用缺省模板參數創建分詞對象, 默認把所有的空格和標點作為分隔符.
6 {
7 std::string str("Link raise the master-sword.");
8
9 tokenizer<> tok(str);
10 for (BOOST_AUTO(pos, tok.begin()); pos != tok.end(); ++pos)
11 std::cout << "[" << *pos << "]";
12 std::cout << std::endl;
13 // [Link][raise][the][master][sword]
14 }
15
16 // 2. char_separator()
17 {
18 std::string str("Link raise the master-sword.");
19
20 // 一個char_separator對象, 默認構造函數(保留標點但將它看作分隔符)
21 char_separator<char> sep;
22 tokenizer<char_separator<char> > tok(str, sep);
23 for (BOOST_AUTO(pos, tok.begin()); pos != tok.end(); ++pos)
24 std::cout << "[" << *pos << "]";
25 std::cout << std::endl;
26 // [Link][raise][the][master][-][sword][.]
27 }
28
29 // 3. char_separator(const Char* dropped_delims,
30 // const Char* kept_delims = 0,
31 // empty_token_policy empty_tokens = drop_empty_tokens)
32 {
33 std::string str = ";!!;Hello|world||-foo--bar;yow;baz|";
34
35 char_separator<char> sep1("-;|");
36 tokenizer<char_separator<char> > tok1(str, sep1);
37 for (BOOST_AUTO(pos, tok1.begin()); pos != tok1.end(); ++pos)
38 std::cout << "[" << *pos << "]";
39 std::cout << std::endl;
40 // [!!][Hello][world][foo][bar][yow][baz]
41
42 char_separator<char> sep2("-;", "|", keep_empty_tokens);
43 tokenizer<char_separator<char> > tok2(str, sep2);
44 for (BOOST_AUTO(pos, tok2.begin()); pos != tok2.end(); ++pos)
45 std::cout << "[" << *pos << "]";
46 std::cout << std::endl;
47 // [][!!][Hello][|][world][|][][|][][foo][][bar][yow][baz][|][]
48 }
49
50 // 4. escaped_list_separator
51 {
52 std::string str = "Field 1,\"putting quotes around fields, allows commas\",Field 3";
53
54 tokenizer<escaped_list_separator<char> > tok(str);
55 for (BOOST_AUTO(pos, tok.begin()); pos != tok.end(); ++pos)
56 std::cout << "[" << *pos << "]";
57 std::cout << std::endl;
58 // [Field 1][putting quotes around fields, allows commas][Field 3]
59 // 引號內的逗號不可做為分隔符.
60 }
61
62 // 5. offset_separator
63 {
64 std::string str = "12252001400";
65
66 int offsets[] = { 2, 2, 4 };
67 offset_separator f(offsets, offsets + 3);
68 tokenizer<offset_separator> tok(str, f);
69
70 for (BOOST_AUTO(pos, tok.begin()); pos != tok.end(); ++pos)
71 std::cout << "[" << *pos << "]";
72 std::cout << std::endl;
73 // [12][25][2001][40][0]
74 }
75 }