作者:zyl910
如今,UTF-8字符串的使用頻率越來越多了。但是在VC中,不能直接處理UTF-8字符串,得專門去寫UTF-8與窄字符串、寬字符串、TCHAR字符串相互轉換的代碼。不僅費時費力,而且稍不留心就容易造成內存洩露問題。於是我便想專門編寫個庫來解決UTF-8字符串編碼問題。
特性——
支持 TCHAR,能隨時切換項目字符集配置。
兼容 32位(x86)與64位(x64)Windows環境。
兼容 VC2005 及更高版本的 VC。
ATL中的字符串轉換宏用起來很方便,於是我打算參考它,做一套字符串轉換宏。
轉換宏的命名規則——
C<SourceType>2[C]<DestinationType>[EX]
<SourceType>、<DestinationType>:字符串類型。可以為 A(char), W(wchar_t), T(TCHAR), U8(UTF-8) 。
[C]:是否是常量。
[EX]:是不是加強版。即是否具有 t_nBufferLength 這樣的模板參數。
例如常用轉換宏有——
CU82A: 將 UTF-8字符串 轉為 窄字符串。
CA2U8: 將 窄字符串 轉為 UTF-8字符串。
CU82W: 將 UTF-8字符串 轉為 寬字符串。
CW2U8: 將 寬字符串 轉為 UTF-8字符串。
CU82T: 將 UTF-8字符串 轉為 TCHAR字符串。
CT2U8: 將 TCHAR字符串 轉為 UTF-8字符串。
范例代碼——
#include <stdio.h>
#include <locale.h>
#include <tchar.h>
#include "zlatlcv.h"
// "Welcome": English, Traditional Chinese, Japanese, Korean.
const char* psa = "A_Welcome_歡迎_ようこそ_환영."; //!< UTF-8 string( Auto. File used UTF-8 encoding).
const wchar_t* psw = L"W_Welcome_\u6B61\u8FCE_\u3088\u3046\u3053\u305D_\uD658\uC601."; //!< Wide char string.
int _tmain(int argc, _TCHAR* argv[])
{
// init.
setlocale(LC_ALL, ""); // 使用客戶環境的缺省locale.
// title.
_tprintf(_T("zlatlcv v1.0 (%dbit)\n"), (int)(8*sizeof(int*)));
_tprintf(_T("sizeof(wchar_t): %d\n"), (int)(sizeof(wchar_t)));
_tprintf(_T("sizeof(TCHAR): %d\n"), (int)(sizeof(TCHAR)));
_tprintf(_T("\n"));
// printf.
fflush(stdout);
printf("printf A:\t%s\n", psa);
printf("printf W:\t%ls\n", psw);
printf("\n");
// UTF-8 to string (UTF-8 轉 各種字符串).
//CA2AZ psaa(psa, CP_UTF8, 0);
CU82A psaa(psa);
CU82W psaw(psa);
printf("printf A from UTF-8:\t%s\n", psaa);
printf("printf W from UTF-8:\t%ls\n", psaw);
printf("\n");
// string to UTF-8 (各種字符串 轉 UTF-8).
CA2U8 psau8(psaa);
CW2U8 pswu8(psaw);
fflush(stdout);
printf("printf UTF-8 from A:\t%s\n", psau8);
printf("printf UTF-8 from W:\t%s\n", pswu8);
// _tprintf.
CA2CT psat(psa);
CW2CT pswt(psw);
CU82T psu8t(psa);
fflush(stdout);
_tprintf(_T("_tprintf A:\t%s\n"), psat);
_tprintf(_T("_tprintf W:\t%s\n"), pswt);
_tprintf(_T("_tprintf U8:\t%s\n"), psu8t);
return 0;
}
運行效果——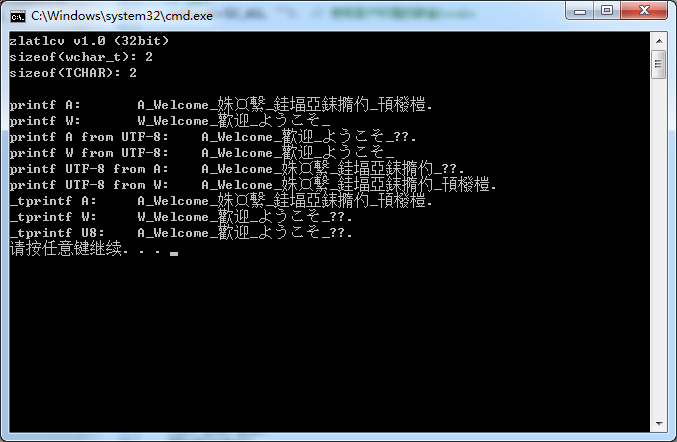
源碼下載——
https://github.com/zyl910/zlatlcv