前段時間剛看完c++語法部分的內容,現在開始著手研究下,用c++實現下一些基本的排序算法。所謂遞歸,就是方法自己調用自己,從而實現代碼上的簡化,同時也簡化閱讀人員的可讀性。
遞歸的優勢在於:當要求解一個問題時,在求解過程中,會碰到同樣的處理過程。這個求解的過程就是遞歸的方法,不斷遞歸的就是這個處理過程,而遞歸讓這個問題逐漸變小,最終回到遞歸基上。
遞歸基:就是當問題足夠簡單時,或者已經不能再分解時,所能給出的返回結果,即為遞歸基。
這樣說可能太抽象了,上例子了:比如:我們求解n!(n的階乘),即1*2*3...n;
數學上: f(n) = n*f(n-1);(n>=2,n是自然數),這個式子有個好名叫遞推公式
可以看出:f(n)和f(n-1)它們是同樣的問題,所以處理過程一定是一樣的,只是規模上的問題。
該問題的詳細過程:當要求得f(n)時,我們要知道f(n-1),
求f(n-1)時,需求f(n-2)的值
...
最終要求f(1)的值,---------遞歸基的位置上
#include<iostream>
int fun(int num);
int main()
{
using namespace std;
int num=5;
cout << fun(num);
return 0;
}
int fun(int num)
{
if(num==1)
{
return 1;
}
return num*fun(num-1);
}
從上述代碼可以看出,f(n)調用了f(n-1)的結果,同理f(n-1)會繼續調用本身的方法,最終都會回歸到遞歸基。
方法代碼簡化:int fun(int num)
{
return num==1?1:num*fun(num-1);
}
常談的斐波那契數列,又稱黃金分割數列,指的是這樣一個數列:1、1、2、3、5、8、13、21、……
在數學上,斐波納契數列以如下被以遞歸的方法定義:F(0)=0,F(1)=1,F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)
從遞推公式中可以看出,它調用了自身,只是處理的規模變成了n-1和n-2;典型的遞歸式。
數列定義中可以看出遞歸基為:F(0)=0,F(1)=1;問題最終都會分解到遞歸基上。
上代碼:
#include<iostream>
int Fibonacci(int num);
int main()
{
using namespace std;
int num=5;
cout << Fibonacci(num);
return 0;
}
int Fibonacci(int num)
{
return num<=1?num:Fibonacci(num-1)+Fibonacci(num-2);
}
程序還真是簡單。
遞歸有個概略印象了,但程序並不是簡潔就行了,還得運行起來快速。所以時間復雜度是必須考慮的,目前對空間復雜度方面暫時不考慮.
其運行圖解如下圖:
我們根據遞推公式:T(n) = T(n-1)+T(n-2)
這是一個常系數的二階線性齊次遞推關系式,其求解方法就簡單了:
得出其特征方程:
可以得到其解,呵呵,黃金分割數要出現了
(黃金分割數的相反數哦。。。。。。)
從而得出復雜度如下:
呵呵,我們平時只記個O(2^n),其實它的時間復雜度是這樣的,很奇怪吧。但確實如此,可見此算法不是個高效的算法,當n達到一定的值時,出結果的速度會長達很久很久,舉個例子吧,若n取100吧,2GHz的處理器,1s鐘能處理2g次,即2^31次,而1年相當於2^25次方,所以n取100時,需要 2^(100-25-31)
") 年,這得等多久啊。。。。。。。。。。
年,這得等多久啊。。。。。。。。。。
所以這不是一個合理的算法。。。。。。
分析上述高時間復雜度產生原因:有些已經計算過值,如F(5),在計算F(6)時,它會調用F(5),此時需重復計算F(5)的值,這樣的多次的重復的計算,造就了如此高的時間復雜度。
若我們采取將這些計算過的值放在一個備忘表中,這樣在下次調用中,直接從備忘表中取,我們可以瞬間降低時間開銷。哈哈,是如此。
上述迭代是一種自上而下的算法,下面我們來看看自下而上的算法。
采用循環迭代的方法:
直接上代碼:
#include<iostream>
int Fibonacci(int num);
int main()
{
using namespace std;
int num=5;
cout << Fibonacci(num);
return 0;
}
int Fibonacci(int num)
{
int result=0;
int sum=1;
if(num<2)
return num;
int i=1;
while(i<num)
{
sum += result;
result = sum-result;
i++;
}
return sum;
}
圖解:
從上可以看出,有時遞歸並不是一定是解決問題最好的辦法,有時也許循環迭代倒是處理問題的好方法
遞歸4—遞歸的弱點
之所以沒有把這段歸為算法的討論,因為這裡討論的不在是算法,而只是討論一下濫用遞歸的不好的一面。
遞歸的用法似乎是很容易的,但是遞歸還是有她的致命弱點,那就是如果運用不恰當,濫用遞歸,程序的運行效率會非常的低,低到什麼程度,低到出乎你的想像!當然,平時的小程序是看不出什麼的,但是一旦在大項目裡濫用遞歸,效率問題將引起程序的實用性的大大降低!
例子:求1到200的自然數的和。
第一種做法:
#include <stdio.h>
void main()
{
int i;
int sum=0;
for(i=1;i<=200;i++)
{
sum+=i;
}
printf("%d\n",sum);
}
該代碼中使用變量2個,計算200次。再看下個代碼:
#include <stdio.h>
int add(int i)
{
if(i==1)
{
return i;
}
else
{
return i+add(i-1);
}
}
void main()
{
int i;
int sum=0;
sum=add(200);
printf("%d\n",sum);
}
但看add()函數,每次調用要聲明一個變量,每次調用要計算一次,所以應該是200個變量,200次計算,對比一下想想,如果程序要求遞歸次數非常多的時候,而且類似與這種情況,我們還能用遞歸去做嗎?這個時候寧願麻煩點去考慮其他辦法,也要嘗試擺脫遞歸的干擾。
21:21 | 添加評論 | 固定鏈接 | 引用通告 (0) | 記錄它 | 計算機與 Internet
程序算法5—遞歸3—遞歸的再次挖掘
遞歸的魅力就在於遞歸的代碼,寫出來實在是太簡練了,而且能解決很多看起來似乎有規律但是又不是一下子能表達清楚的一些問題。思路清晰了,遞歸一寫出來問題立即就解決了,給人一重感覺,遞歸這麼好用。我們在此再更深的挖掘一下遞歸的用法。
之前再強調一點,也許有人會問,你前邊的例子用遞歸似乎是更麻煩了。是,是麻煩了,因為為了方便理解,只能舉一些容易理解的例子,一般等實際應用遞歸的時候,遠遠不是這種狀態。
好了我們現在看一個數字的序列;有一組數的集合{1,2,4,7,11,16,22,29,37,46,56……}我故意多給幾項,一般是只給前4項讓你找規律的。序列給了,要求是求前50項的和。規律?有?還是沒有?一看就象有,但是又看不出來,我多給了幾項,應該很快看出來了,哦,原來每相鄰的兩項的差是個自然數排列,2-1=1,4-2=2,7-4=3,11-7=4,16-11=5……
好了,把規律找出來了,一開始可能覺得沒頭緒,沒問題,咱們把這個序列存放到一個數組總可以吧!那我們就聲明一個數組,存放前50個數據,一個一個相加總可以了。於是有了下邊的寫法:
#include <stdio.h>
void main()
{
int i,a[50],sum=0;
a[0]=1;
for(i=1;i<50;i++)
{
......余下全文>>
首先要理解遞歸本身其實是一項非常重要的算法技巧。
遞歸滿足兩個條件:
1,不斷調用函數本身,也就是遞歸函數。
2,調用是有限的,也就是遞歸出口。
為了理解方便,下面是用一個最簡單的例子:求N的階乘。
n!(階乘)定義:
n!數學意思為n! = n*(n-1)! & 1!=1;
其實根據上面遞歸定義結合分析下就可以n階乘的遞歸算法:
1,構造一個遞歸函數,不斷乘以自身和使用自身減一後調用同樣函數.
2,定義出口,當函數參數等於1時結束;
如果用ISO C++語言描述如下:
int Factorial(int n){
if( n > 1){
return n*Factorial(n-1);//遞歸函數調用
}
else if(n == 1){
return 1; //遞歸出口
}
else{
return ERROR;//報告輸入錯誤
}
}
這裡討論主要的不是上面這個簡單的例子,而是下面的一些改良.
因為遞歸設計大量的堆棧操作,所以一般都會考慮將遞歸轉為非遞歸來執行.
這裡用上面這個程序作一個分析例子來分析.
假設這裡執行Factorial(4),那麼程序會按照下面方式來執行:
(1)執行Factorial(4)判斷n > 1執行Factorial(3),並且將Factorial(4)函數相關信息存入一個堆棧.
(2)執行Factorial(3)判斷n > 1執行Factorial(2),並且將Factorial(3)函數相關信息存入一個堆棧.
(3)執行Factorial(2)判斷n > 1執行Factorial(1),並且將Factorial(2)函數相關信息存入一個堆棧.
(4)執行Factorial(1)判斷n == 1執行返回1;
(5)將Factorial(2)函數從堆棧中彈出,執行2*1,並且返回2.
(6)將Factorial(3)函數從堆棧中彈出,執行2*3,並且返回6.
(7)將Factorial(4)函數從堆棧中彈出,執行6*4,並且返回24.
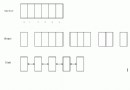
如下圖所示:
Factorial(4)
-->Factorial(3);
-->Factorial(2);
-->Factorail(1);
<--Factorail(1);
<--Factorial(2);
<--Factorial(3);
<--結果
可以看到中間涉及的堆棧操作是很大的開銷,每次需要保存當前函數的所有信息.
為了避免這樣情況,可以使用下面這幾種方法來實現遞歸到非遞歸的轉換.
(1) 循環方法
循環方法是所有遞歸到非遞歸的轉換中最理想的方法,可以將開銷減少到最小.
不過也是分析起來最復雜的,對於簡單的遞歸可以用這樣的方法來處理.
例如:Factorial計算
這裡回到n!(階乘)定義上面來分析,這裡將n!數學意思為n! = n*(n-1)! & 1!=1;做一個擴展可以到到n!另外一個表示方法n! = n*(n-1)*(n-2)*....*1;
這樣就可以很容易得到另外一個定義:
n!表示執行n次循環計算一個增量k,初始k=1和結果t=1;每次t乘以k++的值.
ISO C++實現代碼如下:
Factorial(int n){
int k = 1 ;//增量
int ......余下全文>>