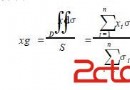C++編程語言是一款應用廣泛,支持多種程序設計的計算機編程語言。我們今天就會為大家詳細介紹其中C++多態性的一些基本知識,以方便大家在學習過程中對此能夠有一個充分的掌握。
前幾天筆試的時候碰到考C++多態性的題目,因為不是自己的專業不是純做軟件開發,C++學習不是很好,做得有點混亂。回來以後立刻查了相關資料,大概明白了一點,可能以後解題的時候不會亂了。
先摘下一些網上的書上的基本概念。
多態性可以簡單地概括為“一個接口,多種方法”,程序在運行時才決定調用的函數,它是面向對象編程領域的核心概念。多態(polymorphisn),字面意思多種形狀。
C++多態性是通過虛函數來實現的,虛函數允許子類重新定義成員函數,而子類重新定義父類的做法稱為覆蓋(override),或者稱為重寫。這裡我覺得要補充,重寫的話可以有兩種,直接重寫成員函數和重寫虛函數,只有重寫了虛函數的才能算作是體現了C++多態性)而重載則是允許有多個同名的函數,而這些函數的參數列表不同,允許參數個數不同,參數類型不同,或者兩者都不同。編譯器會根據這些函數的不同列表,將同名的函數的名稱做修飾,從而生成一些不同名稱的預處理函數,來實現同名函數調用時的重載問題。但這並沒有體現多態性。
多態與非多態的實質區別就是函數地址是早綁定還是晚綁定。如果函數的調用,在編譯器編譯期間就可以確定函數的調用地址,並生產代碼,是靜態的,就是說地址是早綁定的。而如果函數調用的地址不能在編譯器期間確定,需要在運行時才確定,這就屬於晚綁定。
那麼多態的作用是什麼呢,封裝可以使得代碼模塊化,繼承可以擴展已存在的代碼,他們的目的都是為了代碼重用。而多態的目的則是為了接口重用。也就是說,不論傳遞過來的究竟是那個類的對象,函數都能夠通過同一個接口調用到適應各自對象的實現方法。
最常見的用法就是聲明基類的指針,利用該指針指向任意一個子類對象,調用相應的虛函數,可以根據指向的子類的不同而實現不同的方法。如果沒有使用虛函數的話,即沒有利用C++多態性,則利用基類指針調用相應的函數的時候,將總被限制在基類函數本身,而無法調用到子類中被重寫過的函數。因為沒有多態性,函數調用的地址將是一定的,而固定的地址將始終調用到同一個函數,這就無法實現一個接口,多種方法的目的了。
筆試的題目
- #include <stdio.h>
- class A
- {
- public:
- void foo()
- {
- printf("1");
- }
- virtual void fuu()
- {
- printf("2");
- }
- };
- class B:public A
- {
- public:
- void foo()
- {
- printf("3");
- }
- void fuu()
- {
- printf("4");
- }
- };
- int main()
- {
- A a;
- B b;
- A *p = &a;
- p->foo();
- p->fuu();
- p = &b;
- p->foo();
- p->fuu();
- return 0;
- }
第一個p->foo()和p->fuu()都很好理解,本身是基類指針,指向的又是基類對象,調用的都是基類本身的函數,因此輸出結果就是1、2。
第二個p->foo()和p->fuu()則是基類指針指向子類對象,正式體現多態的用法,p->foo()由於指針是個基類指針,指向是一個固定偏移量的函數,因此此時指向的就只能是基類的foo()函數的代碼了,因此輸出的結果還是1。而p->fuu()指針是基類指針,指向的fuu是一個虛函數,由於每個虛函數都有一個虛函數列表,此時p調用fuu()並不是直接調用函數,而是通過虛函數列表找到相應的函數的地址,因此根據指向的對象不同,函數地址也將不同,這裡將找到對應的子類的fuu()函數的地址,因此輸出的結果也會是子類的結果4.
筆試的題目中還有一個另類測試方法。即
- B *ptr = (B *)&a;
- ptr->foo();
- ptr->fuu();
問這兩調用的輸出結果。這是一個用子類的指針去指向一個強制轉換為子類地址的基類對象。結果,這兩句調用的輸出結果是3,2。
並不是很理解這種用法,從原理上來解釋,由於B是子類指針,雖然被賦予了基類對象地址,但是ptr->foo()在調用的時候,由於地址偏移量固定,偏移量是子類對象的偏移量,於是即使在指向了一個基類對象的情況下,還是調用到了子類的函數,雖然可能從始到終都沒有子類對象的實例化出現。
而ptr->fuu()的調用,可能還是因為C++多態性的原因,由於指向的是一個基類對象,通過虛函數列表的引用,找到了基類中foo()函數的地址,因此調用了基類的函數。由此可見多態性的強大,可以適應各種變化,不論指針是基類的還是子類的,都能找到正確的實現方法。