我們常常考究一個算法的時間復雜度或空間復雜度,如果我們有絕對足夠的時間或空間,那麼算法就不需要了,可惜這種條件是不存在的,只是在某些情況下相對來說我們不用去考慮其中一個。今天我們討論的“緩存”,自然就是“用空間換時間”的算法。緩存就是把一些數據暫時存放於某些地方,可能是內存,也有可能硬盤。總之,目的就是為了避免某些耗時的操作。我們常見的耗時的操作,比如數據庫的查詢、一些數據的計算結果,或者是為了減輕服務器的壓力。其實減輕壓力也是因查詢或計算,雖然短耗時,但操作很頻繁,累加起來也很長,造成嚴重排隊等情況,服務器抗不住。
概念性的東西暫就不說了,說多了都是故事。現在我們來談談各種緩存。
初學.NET的朋友開始就會接觸到DataSet類,雲裡霧裡的看著DataSet的例子程序,也不管是咋回事,用就是了。其實DataSet就是緩存,當我們去讀取一段數據集合的時候,如果每讀取一條數據就處理一條的話,那麼我們的程序和數據庫會一直連接著。假如處理一條數據的耗時可以忽略不計,或者只有你一個人使用這個數據庫的話,那麼數據庫一直連著也無所謂,我們寫代碼完全可以不用DataSet類。但是事實上不耗時不可能的,如果耗時嚴重的話,就會一直占用這數據庫連接,直到我們處理完畢。如果這種查詢過多,連接數就會占用過多,而且數據庫在某些操作時會鎖住表,這就會造成其他的請求等待,會出現查詢超時,程序異常等現象。所以,我們必須先把數據拿出來,再對這些數據進行相關的處理,盡早的關閉數據庫連接,好讓數據庫處理其他的請求。 所以,適時地選用DataSet或DataReader是比較重要的(說明:DataReader就是hold住連接的讀取方式)。
你可能會迷惑,不知不覺中使用了緩存(DataSet),這都是.net幫你完成的事。可是,你可能還是不太清楚該如何使用緩存,或者說何時使用緩存。不用著急,我們一一來看。
上面說過,我們緩存的數據無非就是一些數據庫的查詢、計算結果和頻繁查詢。那麼,我們在實際開發中會碰到哪些這種數據呢? 其實仔細想想這是非常常見的,比如用戶登錄後的個人資料,當他每次點擊連接後造成頁面刷新,我們總不能都要去重新查詢數據庫吧?我們常常用Session來存儲這個人的信息,當他退出系統後我們把Session清理掉,所以Session也是緩存,只不過他也是.NET給我們提供好的類,sorry,我又舉了一個你不想看到的例子,哈哈。其實Session是私有化的數據,Session的數據訪問必須通過SessionID(詳情我就不多言了,大家google下),還不足以說明緩存的意義。如果把這個問題延伸下去,假如我們開發的是一個多用戶的Blog系統, 每當我們訪問其中一個博客時都要去查詢這個博主的資料,假如A和B同時訪問一個博客時,最理想的狀態就是只查詢一次,而不是兩個人都去訪問數據庫!是不是呢?其實。。。是也不是!(故事裡的事,說是就是,不是也是;說不是就不是,是也不是。 :)。之所以說不是,是因為假如我們的博客網站每天就幾個人訪問,而且一直發展不起來,我們就沒必要用緩存,因為使用緩存帶來了更多的開發復雜度,因為每當我們去更新博主的資料的時候不單單要更新數據庫的信息,我們還要去處理緩存。但是如果我們的博客訪問量非常大,就像博客園似的,如果再不緩存,那數據庫服務器早就Gameover了:),那麼現在就來看怎麼用緩存的吧。
.Net Framework提供了現成的緩存類供我們使用,常見的是 System.Web.HttpRuntime.Cache。每當我們去執行 BlogDataProvier.GetBlogInfo()方法時(假定這個方法是我們獲取博主信息的方法,顧名思義嘛),需要在查詢之前先從緩存獲取數據,假如數據不存在的話,再去數據庫獲取,並且把得到的結果存入緩存,並且返回該結果既可。下面我把這個方法的偽代碼寫出來,好讓從來沒用過緩存的朋友大致了解一下。
- public class SqlDataProvider
- {
- public static object GetBlogInfo(string username)
- {
- //這裡是從數據庫獲取BlogInfo
- return null;
- }
- }
- public class BlogDataProvider
- {
- public static object GetBlogInfo(string username)
- {
- var cacheKey = "Blog_" + username;
- var blog = CacheHelper.Get(cacheKey);
- if (blog == null)
- {
- blog = SqlDataProvider.GetBlogInfo(username);
- CacheHelper.Set(cacheKey, blog);
- }
- return blog;
- }
- }
- public class CacheHelper
- {
- public static object Get(string key)
- {
- return System.Web.HttpRuntime.Cache.Get(key);
- }
- public static void Set(string key, object value)
- {
- System.Web.HttpRuntime.Cache.Insert(key, value);
- }
- }
緩存,兩個字道出了其實際意義,一個是“存”,我們剛剛存了;另一個是“緩”,暫緩,緩存一般只是用來暫時存儲,其命運都會被刪除或替換掉,所以緩存有個時效問題。如果你說你的數據永遠都不會過期,那麼說真的,我建議你直接寫在代碼裡就可以了。
上面的例子讓我們了解到了HttpCache類。看來我們可以用它來解決絕大部分的緩存問題,主要是公共數據的緩存(所謂公共數據就是你我都可以訪問的同一數據)。希望新手朋友捧著MSDN仔細學習該類的用法,真的很重要哦,不是嗎?
開始我們說了“拿空間換時間”,目前只提到了緩存一些頻繁查詢的情況,犧牲空間緩存時間的明顯些的例子有嗎?沒問題,你看好咯!
說之前先插一句,我們公司現在在招人,其中一道筆試題是介紹一下List和Dictionary的區別和用途。很遺憾,面試了很多人,只有一個同學回答的到位,其他的說什麼的都有。你想好怎麼回答了嗎?:)如果你看了下面發現和你現在想的一致而且你還需要找一份有挑戰的工作的話,給我消息哦。
其實用List,Dictionary泛型就是用來迷魂人的,哈哈,就會有些同學往泛型上面扯,結果上當咯,我完全可以用ArrayList和Hashtable來問。
List是什麼數據結構?數組!而且是動態的數組,之所以動態就是可以視情況動態申請空間。Dictionary是什麼結構?有的同學回答是字典。字典是什麼數據結構? 散列表!散列,一聽這名字就知道是散開分布的數據表。怎麼個“散”法? 自然是按照Key來散,每個Key對應一個Value,所以我們常叫做“鍵值對”,Key和Value是成對的。我們把Dictionary看作是一個數組,那麼每個Key的hash值(什麼是hash值?在.net裡任何類型都有GetHashCode方法,返回int值,有木有),便是數組的下標,而該數組的元素值就是Value!所以我們在獲取Dictionary的某個Key的Value時,速度是非常快的,可以直接通過已知的下標拿到值,這個時間復雜度是O(1)。快不快啊?好快好快。但是,你有木有想到,所有的Key的hash值是按順序來的嗎?顯然不是,鬼知道你用的什麼key,所以,Dictionary的這個數組很長很長,浪費了很多空位置,所以,那就是 空間 換 時間。當然GetHashCode的算法不同,Key對應的值的分布也有區別,有的比較緊密有的比較松散,常見的算法比如一致性hash算法。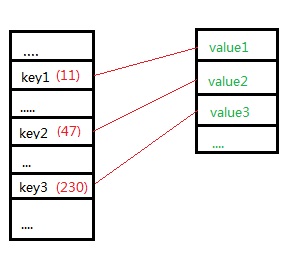
dictionary的實際內存分布
如上圖所示,dict的分布是不緊湊的,犧牲了很多空間,但可以最快速的找到數據,所以dict或hash或map等,不管什麼叫什麼類,總之都是hashtable,它們的用途主要就是查詢。所以,如果我們把博客按用戶名作key緩存起來的話,用戶訪問博客時都是使用的username,所以我們甚至不需要blogId,就可以拿到博主的信息,根本沒走數據庫。
而list這種排列緊湊的數據集合一般用於批處理。當然還有兼顧空間和速度的數據結構,那就是樹結構,在查找時不需要所有數據都進行遍歷,時間復雜度一般是O(logn),而且空間是緊湊的,采用的是鏈表結構,而不是緊湊的數組。所以在時間和空間上都不比前兩者,但用途卻十分廣大,我們所用的數據庫的索引基本上都是用的樹。這樣既保證了占用空間小,查詢的速度也不慢。
上面這一段我們介紹了hash表的基本原理,現在我們明白了緩存的優勢,在實際的項目使用中,我們除了使用系統提供的Cache類以外,完全可以自己嘗試寫緩存類,為什麼不呢?呵呵。我們把一個變量斯static,然後再public,就等於是全局變量了,我們可以到處訪問到他,而且我們還要用dict,因為他足夠快!還不快動手去寫一個,回來再接著看!
剛才提到了“緩”字,緩也有不同的策略,比如最常見的按時間緩存,在單位時間內該數據有效,每當訪問時都要判斷緩存的數據是否過期,再決定Get還是Remove。除了時間策略,還有使用熱度策略,由於內存有限,所以我們的緩存也不是無限申請的,是時候限制長度了。限制了長度就意味著有人能進來就得有人要出去。這就是Remove策略。我們可以對所有的緩存打上標記,來標記他的熱度,每次添加緩存的時候把熱度最低的緩存剔除掉(假如已經達到限制的話)。每次獲取緩存的時候給該緩存熱度+1。這是多人性化的設計,不是嗎? 我上篇博文中已經貼出了這類的代碼。有興趣的朋友給你們個傳送門。
我們繼續用博客園作例子,我們知道博客園的訪問量已經很大了(具體多大,俺不知道,反正以前發表評論經常超時,官方團隊解決後還發表博文說咋解決的,結果評論裡一大票同學都說怎麼不用緩存阿:)。
當網站訪問量達到一定程度後,一台機器很難處理太多的httprequest,這個時候我們必須使用多台機器。假如你的程序沒同時跑在多台機器上的話,你對緩存的理解恐怕不會很深,因為誰都要會這種經歷:哎呀 sessio不能分布式阿? 哎呀媽呀,我的緩存不能在兩台機器上阿,這可咋整?!
其實這也不能怪你,要怪就怪微軟吧。因為IIS,我們的web程序駐留在一個進程裡,每個httprequest會有一個線程來處理,所以你甚至都沒用過多線程。害人啊,哈哈。但隨著項目經驗的增加,特別是大項目的歷練後,也沒什麼了。之所以說是微軟的錯,是因為人家php阿,ruby阿,人家的服務端(apache,nginx等)都是多進程的。每個httprequest一個進程,總共開幾十個進程,處理並發。多進程就意味著數據共享問題,就像我們多台機器的情況一樣。 這時候需要借助一個共享緩存進程來供其他的web服務進程來訪問獲取緩存。 這就是下面要說的 分布式緩存。
如果說兩三年前你不知memcached為何物,或許情有可原,那時候還流行自己寫windows service。但現在滿世界的NoSQL,MongoDB,Memcached,Redis,你再不知道的話,真該說多看看博客吧;看看新技術,你已經落後一個時代了。
上面提到的這個名詞都是玩緩存的主。NoSQL是個新技術,NoSQL DB現在很多種,MongoDB就是一種,MongoDB是介於傳統關系型數據庫和內存數據庫的雜交數據庫,現在也算是很熱門的數據庫。MemCached是著名的分布式緩存服務,而Redis(Remoting Dictionary Service),你懂了吧?!我們的緩存服務器可以用memcached或redis,Memcached是純內存的,重啟進程會丟失所有緩存,而redis可以把數據寫到硬盤裡,各有各的優點吧。Redis更適合存經過計算過的數據。而且Redis支持豐富的數據類型(list\set\hash\string),這要比memcached更靈活些。 他們都有.net的Driver,還有相關的Example和UnitTest,可以官網下載看看。
關於Redis的使用可以看代震軍大蝦的http://www.cnblogs.com/daizhj/archive/2011/02/21/1959511.html
隨著硬件的發展,內存的不斷增加,緩存的應用越來越多,現在各種NoSQL數據庫應用而生,我們也要緊跟腳步,學習新的理念。 希望上述文章會對你有幫助。