要將一個數組的所有元素向左旋轉k位,通常有三種算法:
算法1(分組交換):
若a長度大於b,將ab分成a0a1b,交換a0和b,得ba1a0,只需再交換a1 和a0。
若a長度小於b,將ab分成ab0b1,交換a和b0,得b0ab1,只需再交換a 和b1。
不斷將數組劃分和交換,直到不能再劃分為止。分組過程與求最大公約數很相似。
讀寫內存各 n到2*n次
算法2 (三次反轉)
利用ba=(br)r(ar)r=(arbr)r,先分別反轉a、b,最後再對所有元素進行一次反轉。
讀寫內存各約2*n次
算法3 (使用循環鏈)
假設 n、k的最大公約數為M,則所有序號為 (i + j*k) % n (0<= i < M, 0 <= j < n/M)的元素,構成M個循環鏈(i值相同的在同一個循環鏈上), 每個循環鏈上的元素移動到前一個元素的元素,就可以交換到最終結果上的位置,因而總共只要讀寫內存各n次。(比如: 1 2 3 4 5 6,左移2位, 1 3 5 和 2 4 6分別構成兩個循環鏈。)
事實上C++標准算法庫提供了現成的函數:rotate函數。按理說,幾種算法都比較簡單,編譯器的庫函數又是經過時間檢驗的,效率即使比手寫的差,也不會差太多。但如果對rotate函數進行測試的話,可能會發現標准庫的版本慢得可不是一點點。
對VC 2010,運行後面的測試程序,自定義函數(采用算法2)要用99ms,而std::rotate卻要1656ms。是庫的實現者不懂得用這個簡單的算法嗎?檢查下庫的源代碼,就會發現:標准算法庫中,對C++的三種迭代器(前向迭代器、雙向迭代器,隨機訪問迭代器),分別采用了上面三種算法。直接調用其內部的實現(std::_Rotat函數),重新測試下,可得到下面結果:
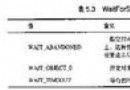
迭代器 前向(算法1) 雙向(算法2) 隨機訪問(算法3)
時間(ms) 46 99 1651
(使用GCC的,請用版本號低於4.5的進行測試)
從結果可以看出,效率是:算法1 > 算法2 >>> 算法3。
從理論上講,算法3只要讀寫內存各n次,應該是效率最高的算法。這在每次內存讀寫的開銷相差不大時成立。但實際上,由於硬件限制,CPU對內存的訪問采用分級緩存機制:一級緩存容量很小但訪問速度最快,存放程序的指令和最常用的數據,而二、三級緩存容量較大但訪問速度要慢很多。CPU是無法繞過緩存直接訪問內存數據(某些特殊指令可以不用一二三級緩存,但它也要用到其它專用緩存),對不在緩存中的數據,必須先載入到緩存中,這個操作是相當昂貴的。對大數組來說,不可能將所有數據都存放在緩存中,而對內存的不連續訪問,CPU對內存定位的開銷(各級緩存間數據的調整,反復移入或移出數據到緩存)是巨大的,這就造成了算法3的性能在該情況下非常差。測試發現,k = 3時,該算法的效率就已經相當差了。對小數組,盡管該算法讀寫次數少,但由於各種算法所用時間都很小,這種優勢很難體現出來。可以說,算法3在數學上是非常優美的,但是在實際應用中,是一種相當差的算法。
對算法的選擇,不應該忽視內存因素。在對隨機訪問迭代器版本的roate實現上犯這個錯誤的,可不僅僅是VC,還有著名的STL Port、GCC(GCC從4.5開始libstdc++改用算法1,並做了些優化),以及新興的libc++。(其它的編譯器/庫沒用過,也就沒有測試。)
另外,測試時發現VC 2010的一個bug:前向迭代器的實現版本,當k = 0時,程序直接掛了。
測試代碼:
rotate