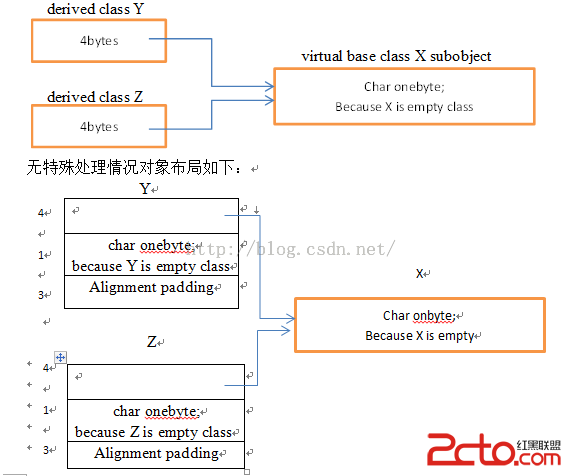
Repository Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others) Total Submission(s): 1750 Accepted Submission(s): 651 Problem Description When you go shopping, you can search in repository for avalible merchandises by the computers and internet. First you give the search system a name about something, then the system responds with the results. Now you are given a lot merchandise names in repository and some queries, and required to simulate the process. Input There is only one case. First there is an integer P (1<=P<=10000)representing the number of the merchanidse names in the repository. The next P lines each contain a string (it's length isn't beyond 20,and all the letters are lowercase).Then there is an integer Q(1<=Q<=100000) representing the number of the queries. The next Q lines each contains a string(the same limitation as foregoing descriptions) as the searching condition. Output For each query, you just output the number of the merchandises, whose names contain the search string as their substrings. Sample Input 20 ad ae af ag ah ai aj ak al ads add ade adf adg adh adi adj adk adl aes 5 b a d ad s Sample Output 0 20 11 11 2 Source 2009 Multi-University Training Contest 4 - Host by HDU Recommend gaojie 解題思路:字典樹第三彈,這一題要求我們找到輸入的詞是字典中多少個詞的子串,而不僅僅是其前綴,因此建樹的時候需要將詞典中詞分解成不同前綴加入到樹中,即是說將形如abc的詞拆成abc,bc,c,三種形式,這樣就相當於找輸入的詞是詞典中多少詞的前綴,需要注意的是,對於同一個詞分解出的多個前綴,如果他們之間有相同的話,這種前綴,只算作一種,即是說形如abca之類的詞,會分解出abca,a兩種前綴,但因為是同一個詞分解出來的,所以算作一種。判斷是否是同一個詞分解出來的需要給每個輸入的詞及其分解出的前綴加以相同的id進行編號。 [cpp] #include<cstdio> #include<cstring> #include<iostream> using namespace std; int ans,len; typedef struct TrieNode { int c,id; struct TrieNode *next[26]; TrieNode() { id=-1;//初始化每個節點的id為-1 c=0; memset(next,0,sizeof(next)); } }; TrieNode *root=NULL; void CreatTree(char s[],int num) { int i,len; len=strlen(s); TrieNode *p=root; TrieNode *temp; for(i=0;i<len;i++) { www.2cto.com if(p->next[s[i]-'a']==NULL) { temp=new TrieNode; p->next[s[i]-'a']=temp; } p=p->next[s[i]-'a']; if(p->id!=num)//如果分解出的詞的前綴與已經在之前分解的詞的前綴相同(id==num),那就不能算作一種新的前綴 p->c++; p->id=num;//對同一個詞分解出的詞,在樹上的各個節點給予相同id } } void Search(char s[],int d) { int i,j; TrieNode *p=root; for(i=0;i<d;i++) { if(p->next[s[i]-'a']) p=p->next[s[i]-'a']; else { ans=0;//如果輸入的詞不是詞典中任何詞及其分解出的詞的前綴,那這個詞就不是詞典中任何一個詞的子串 return; } } ans=p->c;//否則,在不同詞的分解的詞(重復的不算)中,輸出的詞是多少個詞的前綴就是所求答案 } void Delete(TrieNode *node) { int i; for(i=0;i<26;i++) { if(node->next[i]) Delete(node->next[i]); delete node->next[i]; node->next[i]=0; } } int main() { int i,j,m,n,len; char str[25],temp[25]; root=new TrieNode; scanf("%d",&n); memset(str,'\0',sizeof(str)); for(i=0;i<n;i++) { scanf("%s",&str); len=strlen(str); for(j=0;j<len;j++) { strncpy(temp,str+j,len-j);//將詞典中詞以不同前綴進行分解,並分別加入樹中 temp[len-j]='\0'; CreatTree(temp,i);//i用以判斷是否為詞典中同一個詞分解出來的 } memset(str,'\0',sizeof(str)); } scanf("%d",&m); for(i=0;i<m;i++) { www.2cto.com ans=0; scanf("%s",&str); len=strlen(str); Search(str,len); printf("%d\n",ans); } Delete(root); return 0; }