思路一:尾地址判定法。常規的判斷方法是判斷兩鏈表的一個結點地址是否相同。具體做法是先遍歷list1, 保存最後一個結點的地址end1;再遍歷list2到最後一個結點,判斷地址是否等於end1。 時間復雜度為O(len1+len2), 空間復雜度為 O(1)。
思路二:hash地址法。通常若允許使用hash的話,能夠快速有效的解決。 這裡,我們遍歷list1, 將每個結點的地址hash;再遍歷list2,判斷結點地址是否出現在hash表中。時間復雜度為O(len1+len2), 空間復雜度為O(len1); 這裡,雖然時間復雜度未降低,同時增加了空間復雜度,但是卻能很好的解決第1個公共結點問題。算是一種補償。
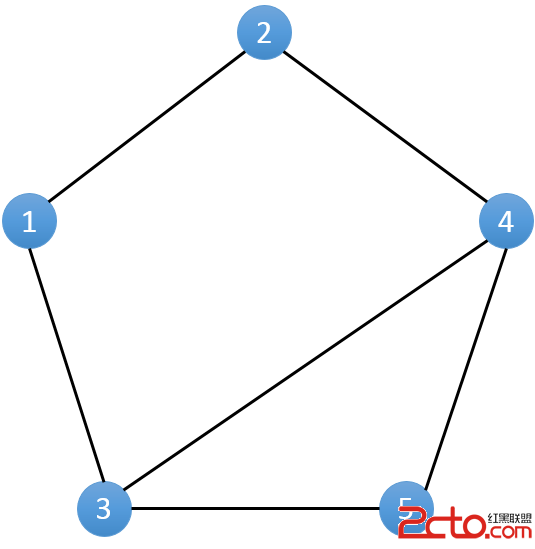
思路三:鏈接成環法。參考下面圖3。首先,先將第一個鏈表的最後一個結點鏈接到第二個結點的頭,然後判斷是否有環,若有環,則說明兩個鏈表存在公共結點。
思路一: 快慢指針法. 我們在用快fast, slow兩指針指向鏈表頭,fast指針一次跨兩步, slow指針一次跨一步,有環的條件為fast==slow != NULL 。
Node* cross_first(Node* h1, Node*(h1==NULL || h2==* p = s1 = (p->next !=++= p->* q = s2 = (q->next !=++= q->(p !=== prestep = static_cast<>(abs(s1-(s1>(prestep--= p->(prestep--= q->(p !== p->= q->思路三:鏈接成環法(也是求環的入口點的解法)。將鏈表1的尾結點鏈接到鏈表2的第一個結點,然後調用快慢指針法判斷是否有環。然後保存相遇點,同時slow指針從頭開始,步長為1遞增;fast指針從相遇點開始,步長為1遞增,他們再一次的相遇點,則是第一個公共結點。 數學推導如下: 先假設鏈表長 L, 入環前結點數 b, 環內結點 r, slow指針走了 s 步相遇, 相遇點為環內 x 步, 則 fast 指針走了 2s 步, 且相遇點前fast已近走了n(n>=1) 圈。 則有: snr
Node* cross_first_by_circle(Node* h1, Node*(h1 == NULL || h2 == NULL) * p =(p->next !== p->* holdh1 =->next =* fast ==(fast == NULL) * slow =(fast !== fast->= slow->->next =參考資料: http://www.cnblogs.com/gw811/archive/2012/10/28/2743182.html http://wenku.baidu.com/view/299c440cf78a6529647d536b.html 《劍指offer》
Node* backK(Node* head, (head == NULL || k <= ) * p =( i=; i<k-; ++(p->next == NULL) = p->* knode =(p->next !== p->= knode->歸納法證明: 若k=1: k-1 = 0, 兩個指針同步運行,成立。 若k=x; k-1 = x-1; 第一個指針繼續走 n-x步到達最後一個結點, 第二個指針走 (n-x) 步後,處於倒數 n-(n-x)=x 的位置,成立。 這裡的注意事項是: 若鏈表長度小於k怎麼辦? 輸入的是空鏈表怎麼辦?若輸入k=0, 則k-1步導致溢出怎麼辦?因此,寫好一個好的代碼是要考慮很多因素的。
insert_sort(Node* head,Node* end = (head == end) Node* piot = head-> Node* cur = (piot != cur = ( (cur!=piot) && (cur->datum<=piot-> cur = cur-> tmp = cur-> cur->datum = piot-> piot->datum = piot = piot-> bubble_sort(Node* head, Node* end = (head == end) Node* piot = Node* Node* change = (piot != cur = piot-> prev = change = (cur != (cur->datum < prev-> tmp = cur-> cur->datum = prev-> prev->datum = change = prev = cur = cur-> piot = piot-> ( !change ) }
對於交換指針來說,想下是好恐怖的一件事呀。其實不難,把結點交換的函數抽取出來,問題就簡單了
首先,我們要設計一下鏈表節點的交換函數 swap_point, 這個函數的聲明如下:
swap_point(Node** Node* preFirst, Node* Node* preSecond, Node*
然後,要考慮兩大種情況的組合:
對於頭結點問題,我們知道這是鏈表問題必須考慮的,我們在代碼中加個判斷語句,選擇性執行頭結點的更新就行。
對於first->next 是否等於 second ,大家畫圖下,就很好理解了:
接著,我們在插入排序中,在要交換的位置傳入合適的前向指針,就行,哈哈,代碼如下:
swap_point(Node** head, Node* preFirst, Node* first, Node* preSecond, Node* (head == NULL || *head == NULL || first == NULL || second == NULL) (first->next != Node* tmp = first-> first->next = second-> second->next = preSecond->next = } first->next = second-> second->next = (*head != preFirst->next =
*head =
insert_sort_point(Node** head, Node* end = (*head == end) Node* piot = (*head)-> Node* prepiot = * Node* cur = * Node* precur = * (piot != cur = * ((cur != piot) && (cur->datum<=piot-> precur = cur = cur-> prepiot = piot = piot-> }
經過測試,成立!
Node* insert_front(Node** head, (head == (*head == *head = } Node* p = p->next = * *head = * Node* insert_comp(Node** head, (head == Node* (*head == = *head = } = ((*head)->datum > } Node* p = * Node* n = (*head)-> ( n != NULL && n->datum < p = n = n-> p->next = ->next = }
delNode(Node** head, Node* (head == NULL || *head == NULL || n == (n->next != NULL){
Node* tmp = n-> n->datum = tmp-> n->next = tmp-> tmp = } (*head == n){
*head = }{
Node* p = * (p->next != p = p-> p->next = n = }
#include
#include <iostream>
Node* head1 = insert_comp (&head1, insert_comp (&head1, insert_comp (&head1, insert_comp (&head1, insert_comp (&head1, Node* head2 = insert_comp (&head1, insert_front(&head2, insert_front(&head2, cout << << cross_tail_compare (head1,head2) << cout << << cross_first (head1,head2)->datum << cout << << cross_first_by_circle (head1,head2)->datum << cout << << backK (head1,)->datum << Node* pp = (pp == cout << << } cout << << cout << << Node* head3 = insert_comp (&head3, insert_comp (&head3, Node* circin = insert_comp (&head3, insert_comp (&head3, Node* tail = insert_comp (&head3, tail->next = show(tail,tail-> pp = (pp == cout << << } cout << << }