每個弱分類器的分類結果加權相加後,再用sign函數激活,得到最終分類結果。這裡的權就是alpha
alpha根據每個弱分類器的分類錯誤率算出,alpha = 0.5 * ln( (1-errorRate) / errorRate )
本算法中的弱分類器為單決策樹,在構建單決策樹時,會根據加權錯誤率來衡量其性能
被分錯的樣本權重高,權重計算:D[i] = D[i] * e^(-1 * alpha * label[i]) / sum(D)
在AdaBoost訓練過程中,每一次迭代都會更新D,D是AdaBoost與各弱分類器交互的地方
每一次迭代都會創建一個弱分類器,並存儲下來
當分類錯誤率很小,或者迭代次數夠了時,AdaBoos訓練結束
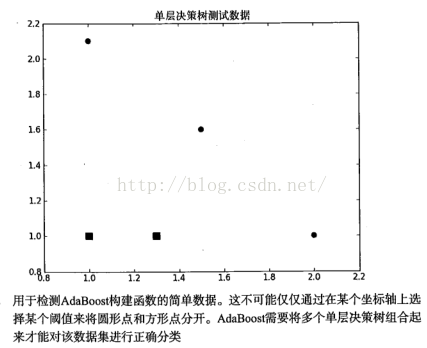
#include
#include
#include
#include
#include
#include
運行結果: