到目前為止,我們已經使用了 iostream 標准庫,它提供了 cin 和 cout 方法分別用於從標准輸入讀取流和向標准輸出寫入流。
本教程介紹如何從文件讀取流和向文件寫入流。
這就需要用到 C++ 中另一個標准庫 fstream,它定義了三個新的數據類型:

要在 C++ 中進行文件處理,必須在 C++ 源代碼文件中包含頭文件 和 。
打開文件
在從文件讀取信息或者向文件寫入信息之前,必須先打開文件。ofstream 和 fstream 對象都可以用來打開文件進行寫操作,如果只需要打開文件進行讀操作,則使用 ifstream 對象。
下面是 open() 函數的標准語法,open() 函數是 fstream、ifstream 和 ofstream 對象的一個成員。
void open(const char *filename, ios::openmode mode);
在這裡,open() 成員函數的第一參數指定要打開的文件的名稱和位置,第二個參數定義文件被打開的模式。
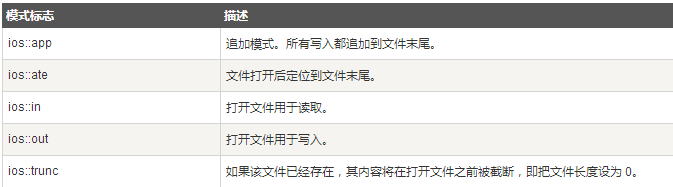
您可以把以上兩種或兩種以上的模式結合使用。
例如,如果您想要以寫入模式打開文件,並希望截斷文件,以防文件已存在,那麼您可以使用下面的語法:
ofstream outfile;
outfile.open("file.dat", ios::out | ios::trunc );
類似地,您如果想要打開一個文件用於讀寫,可以使用下面的語法:
fstream afile;
afile.open("file.dat", ios::out | ios::in );
關閉文件
當 C++ 程序終止時,它會自動關閉刷新所有流,釋放所有分配的內存,並關閉所有打開的文件。但程序員應該養成一個好習慣,在程序終止前關閉所有打開的文件。
下面是 close() 函數的標准語法,close() 函數是 fstream、ifstream 和 ofstream 對象的一個成員。
void close();
寫入文件
在 C++ 編程中,我們使用流插入運算符( << )向文件寫入信息,就像使用該運算符輸出信息到屏幕上一樣。
唯一不同的是,在這裡您使用的是 ofstream 或 fstream 對象,而不是 cout 對象。
讀取文件
在 C++ 編程中,我們使用流提取運算符( >> )從文件讀取信息,就像使用該運算符從鍵盤輸入信息一樣。
唯一不同的是,在這裡您使用的是 ifstream 或 fstream 對象,而不是 cin 對象。
讀取 & 寫入實例
下面的 C++ 程序以讀寫模式打開一個文件。
在向文件 afile.dat 寫入用戶輸入的信息之後,程序從文件讀取信息,並將其輸出到屏幕上:
#include
#include
using namespace std;
int main ()
{
char data[100];
// 以寫模式打開文件
ofstream outfile;
outfile.open("afile.dat");
cout << "Writing to the file" << endl;
cout << "Enter your name: ";
cin.getline(data, 100);
// 向文件寫入用戶輸入的數據
outfile << data << endl;
cout << "Enter your age: ";
cin >> data;
cin.ignore();
// 再次向文件寫入用戶輸入的數據
outfile << data << endl;
// 關閉打開的文件
outfile.close();
// 以讀模式打開文件
ifstream infile;
infile.open("afile.dat");
cout << "Reading from the file" << endl;
infile >> data;
// 在屏幕上寫入數據
cout << data << endl;
// 再次從文件讀取數據,並顯示它
infile >> data;
cout << data << endl;
// 關閉打開的文件
infile.close();
return 0;
}
當上面的代碼被編譯和執行時,它會產生下列輸入和輸出:
$./a.out Writing to the file Enter your name: Zara Enter your age: 9 Reading from the file Zara 9
上面的實例中使用了 cin 對象的附加函數,比如 getline()函數從外部讀取一行,ignore() 函數會忽略掉之前讀語句留下的多余字符。
文件位置指針
istream 和 ostream 都提供了用於重新定位文件位置指針的成員函數。
這些成員函數包括關於 istream 的 seekg(”seek get”)和關於 ostream 的 seekp(”seek put”)。
seekg 和 seekp 的參數通常是一個長整型。
第二個參數可以用於指定查找方向。
查找方向可以是 ios::beg(默認的,從流的開頭開始定位),也可以是 ios::cur(從流的當前位置開始定位),也可以是 ios::end(從流的末尾開始定位)。
文件位置指針是一個整數值,指定了從文件的起始位置到指針所在位置的字節數。
下面是關於定位 “get” 文件位置指針的實例:
// 定位到 fileObject 的第 n 個字節(假設是 ios::beg) fileObject.seekg( n ); // 把文件的讀指針從 fileObject 當前位置向後移 n 個字節 fileObject.seekg( n, ios::cur ); // 把文件的讀指針從 fileObject 末尾往回移 n 個字節 fileObject.seekg( n, ios::end ); // 定位到 fileObject 的末尾 fileObject.seekg( 0, ios::end );
異常是程序在執行期間產生的問題。
C++ 異常是指在程序運行時發生的特殊情況,比如嘗試除以零的操作。
異常提供了一種轉移程序控制權的方式。
C++ 異常處理涉及到三個關鍵字:try、catch、throw。
throw: 當問題出現時,程序會拋出一個異常。這是通過使用 throw 關鍵字來完成的。 catch: 在您想要處理問題的地方,通過異常處理程序捕獲異常。catch 關鍵字用於捕獲異常。 try: try 塊中的代碼標識將被激活的特定異常。它後面通常跟著一個或多個 catch 塊。
如果有一個塊拋出一個異常,捕獲異常的方法會使用 try 和 catch 關鍵字。
try 塊中放置可能拋出異常的代碼,try 塊中的代碼被稱為保護代碼。
使用 try/catch 語句的語法如下所示:
try
{
// 保護代碼
}catch( ExceptionName e1 )
{
// catch 塊
}catch( ExceptionName e2 )
{
// catch 塊
}catch( ExceptionName eN )
{
// catch 塊
}
如果 try 塊在不同的情境下會拋出不同的異常,這個時候可以嘗試羅列多個 catch 語句,用於捕獲不同類型的異常。
拋出異常
您可以使用 t**hrow 語句在代碼塊中的任何地方拋出異常**。
throw 語句的操作數可以是任意的表達式,表達式的結果的類型決定了拋出的異常的類型。
以下是嘗試除以零時拋出異常的實例:
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
捕獲異常
catch 塊跟在 try 塊後面,用於捕獲異常。
您可以指定想要捕捉的異常類型,這是由 catch 關鍵字後的括號內的異常聲明決定的。
try
{
// 保護代碼
}catch( ExceptionName e )
{
// 處理 ExceptionName 異常的代碼
}
上面的代碼會捕獲一個類型為 ExceptionName 的異常。
如果您想讓 catch 塊能夠處理 try 塊拋出的任何類型的異常,則必須在異常聲明的括號內使用省略號 …,如下所示:
try
{
// 保護代碼
}catch(...)
{
// 能處理任何異常的代碼
}
下面是一個實例,拋出一個除以零的異常,並在 catch 塊中捕獲該異常。
#include
using namespace std;
double division(int a, int b)
{
if( b == 0 )
{
throw "Division by zero condition!";
}
return (a/b);
}
int main ()
{
int x = 50;
int y = 0;
double z = 0;
try {
z = division(x, y);
cout << z << endl;
}catch (const char* msg) {
cerr << msg << endl;
}
return 0;
}
由於我們拋出了一個類型為 const char* 的異常,因此,當捕獲該異常時,我們必須在 catch 塊中使用 const char*。
當上面的代碼被編譯和執行時,它會產生下列結果:
Division by zero condition!
C++ 標准的異常
C++ 提供了一系列標准的異常,定義在 中,我們可以在程序中使用這些標准的異常。
它們是以父子類層次結構組織起來的,如下所示:
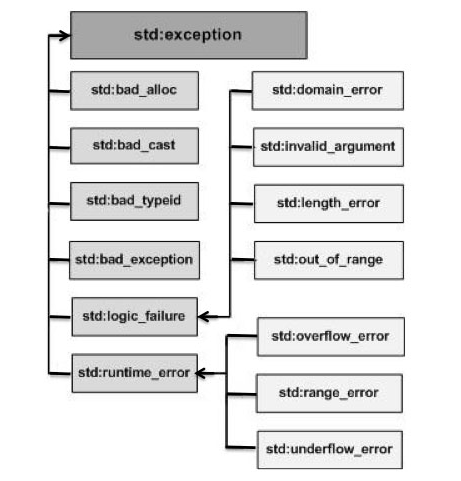
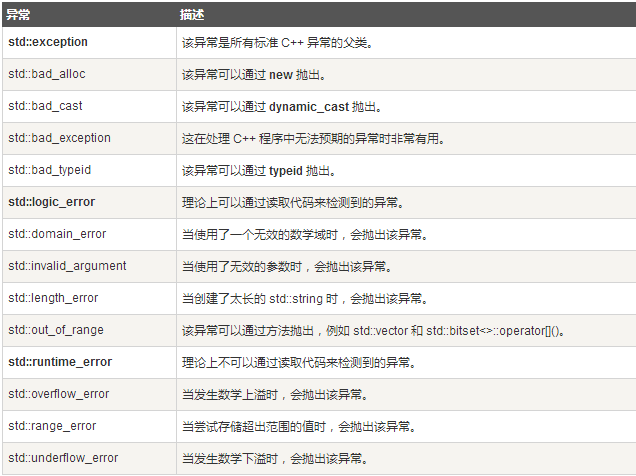
下表是對上面層次結構中出現的每個異常的說明:
定義新的異常
您可以通過繼承和重載 exception 類來定義新的異常。
下面的實例演示了如何使用 std::exception 類來實現自己的異常:
#include
#include
using namespace std;
struct MyException : public exception
{
const char * what () const throw ()
{
return "C++ Exception";
}
};
int main()
{
try
{
throw MyException();
}
catch(MyException& e)
{
std::cout << "MyException caught" << std::endl;
std::cout << e.what() << std::endl;
}
catch(std::exception& e)
{
//其他的錯誤
}
}
這將產生以下結果:
MyException caught
C++ Exception
在這裡,what() 是異常類提供的一個公共方法,它已被所有子異常類重載。
這將返回異常產生的原因。
C++ 動態內存
了解動態內存在 C++ 中是如何工作的是成為一名合格的 C++ 程序員必不可少的。C++ 程序中的內存分為兩個部分:
棧:在函數內部聲明的所有變量都將占用棧內存。 堆:這是程序中未使用的內存,在程序運行時可用於動態分配內存。
很多時候,您無法提前預知需要多少內存來存儲某個定義變量中的特定信息,所需內存的大小需要在運行時才能確定。
在 C++ 中,您可以使用特殊的運算符為給定類型的變量在運行時分配堆內的內存,這會返回所分配的空間地址。這種運算符即 new 運算符。
如果您不需要動態分配內存,可以使用 delete 運算符,刪除之前由 new 運算符分配的內存。
new 和 delete 運算符
下面是使用 new 運算符來為任意的數據類型動態分配內存的通用語法:
new data-type;
在這裡,data-type 可以是包括數組在內的任意內置的數據類型,也可以是包括類或結構在內的用戶自定義的任何數據類型。
讓我們先來看下內置的數據類型。
例如,我們可以定義一個指向 double 類型的指針,然後請求內存,該內存在執行時被分配。
我們可以按照下面的語句使用 new 運算符來完成這點:
double* pvalue = NULL; // 初始化為 null 的指針
pvalue = new double; // 為變量請求內存
如果自由存儲區已被用完,可能無法成功分配內存。
所以建議檢查 new 運算符是否返回 NULL 指針,並采取以下適當的操作:
double* pvalue = NULL;
if( !(pvalue = new double ))
{
cout << "Error: out of memory."
using namespace std;
int main ()
{
double* pvalue = NULL; // 初始化為 null 的指針
pvalue = new double; // 為變量請求內存
*pvalue = 29494.99; // 在分配的地址存儲值
cout << "Value of pvalue : " << *pvalue << endl;
delete pvalue; // 釋放內存
return 0;
}
當上面的代碼被編譯和執行時,它會產生下列結果:Value of pvalue : 29495數組的動態內存分配假設我們要為一個字符數組(一個有 20 個字符的字符串)分配內存,我們可以使用上面實例中的語法來為數組動態地分配內存,如下所示:char* pvalue = NULL; // 初始化為 null 的指針
pvalue = new char[20]; // 為變量請求內存要刪除我們剛才創建的數組,語句如下:delete [] pvalue; // 刪除 pvalue 所指向的數組下面是 new 操作符的通用語法,可以為多維數組分配內存,如下所示:
int ROW = 2;
int COL = 3;
double **pvalue = new double* [ROW]; // 為行分配內存
// 為列分配內存
for(int i = 0; i < COL; i++) {
pvalue[i] = new double[COL];
}釋放多維數組內存:for(int i = 0; i < COL; i++) {
delete[] pvalue[i];
}
delete [] pvalue; 對象的動態內存分配對象與簡單的數據類型沒有什麼不同。例如,請看下面的代碼,我們將使用一個對象數組來理清這一概念:
#include
using namespace std;
class Box
{
public:
Box() {
cout << "調用構造函數!" <如果要為一個包含四個 Box 對象的數組分配內存,構造函數將被調用 4 次,
同樣地,當刪除這些對象時,析構函數也將被調用相同的次數(4次)。當上面的代碼被編譯和執行時,它會產生下列結果:
調用構造函數! 調用構造函數! 調用構造函數! 調用構造函數! 調用析構函數! 調用析構函數! 調用析構函數!
調用析構函數!C++ 命名空間假設這樣一種情況,當一個班上有兩個名叫 Zara 的學生時,為了明確區分它們,我們在使用名字之外,不得不使用一些額外的信息,比如他們的家庭住址,或者他們父母的名字等等。同樣的情況也出現在 C++ 應用程序中。例如,您可能會寫一個名為 xyz() 的函數,在另一個可用的庫中也存在一個相同的函數 xyz()。這樣,編譯器就無法判斷您所使用的是哪一個 xyz() 函數。因此,引入了命名空間這個概念,專門用於解決上面的問題,它可作為附加信息來區分不同庫中相同名稱的函數、類、變量等。使用了命名空間即定義了上下文。本質上,命名空間就是定義了一個范圍。定義命名空間命名空間的定義使用關鍵字 namespace,後跟命名空間的名稱,如下所示:
namespace namespace_name {
// 代碼聲明
}為了調用帶有命名空間的函數或變量,需要在前面加上命名空間的名稱,如下所示:name::code; // code 可以是變量或函數讓我們來看看命名空間如何為變量或函數等實體定義范圍:#include
using namespace std;
// 第一個命名空間
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二個命名空間
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
int main ()
{
// 調用第一個命名空間中的函數
first_space::func();
// 調用第二個命名空間中的函數
second_space::func();
return 0;
}
當上面的代碼被編譯和執行時,它會產生下列結果:Inside first_space
Inside second_spaceusing 指令您可以使用 using namespace 指令,這樣在使用命名空間時就可以不用在前面加上命名空間的名稱。這個指令會告訴編譯器,後續的代碼將使用指定的命名空間中的名稱。
#include
using namespace std;
// 第一個命名空間
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
}
// 第二個命名空間
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
using namespace first_space;
int main ()
{
// 調用第一個命名空間中的函數
func();
return 0;
}
當上面的代碼被編譯和執行時,它會產生下列結果:Inside first_spaceusing 指令也可以用來指定命名空間中的特定項目。例如,如果您只打算使用 std 命名空間中的 cout 部分,您可以使用如下的語句:using std::cout;隨後的代碼中,在使用 cout 時就可以不用加上命名空間名稱作為前綴,但是 std 命名空間中的其他項目仍然需要加上命名空間名稱作為前綴,如下所示:
#include
using std::cout;
int main ()
{
cout << "std::endl is used with std!" << std::endl;
return 0;
}
當上面的代碼被編譯和執行時,它會產生下列結果:std::endl is used with std!using 指令引入的名稱遵循正常的范圍規則。名稱從使用 using 指令開始是可見的,直到該范圍結束。此時,在范圍以外定義的同名實體是隱藏的。不連續的命名空間命名空間可以定義在幾個不同的部分中,因此命名空間是由幾個單獨定義的部分組成的。一個命名空間的各個組成部分可以分散在多個文件中。所以,如果命名空間中的某個組成部分需要請求定義在另一個文件中的名稱,則仍然需要這裡寫代碼片聲明該名稱。下面的命名空間定義可以是定義一個新的命名空間,也可以是為已有的命名空間增加新的元素:
namespace namespace_name {
// 代碼聲明
}嵌套的命名空間命名空間可以嵌套,您可以在一個命名空間中定義另一個命名空間,如下所示:namespace namespace_name1 {
// 代碼聲明
namespace namespace_name2 {
// 代碼聲明
}
}您可以通過使用 :: 運算符來訪問嵌套的命名空間中的成員:// 訪問 namespace_name2 中的成員
using namespace namespace_name1::namespace_name2;
// 訪問 namespace:name1 中的成員
using namespace namespace_name1;在上面的語句中,如果使用的是 namespace_name1,那麼在該范圍內 namespace_name2 中的元素也是可用的,如下所示:#include
using namespace std;
// 第一個命名空間
namespace first_space{
void func(){
cout << "Inside first_space" << endl;
}
// 第二個命名空間
namespace second_space{
void func(){
cout << "Inside second_space" << endl;
}
}
}
using namespace first_space::second_space;
int main ()
{
// 調用第二個命名空間中的函數
func();
return 0;
}
當上面的代碼被編譯和執行時,它會產生下列結果:Inside second_space