本來說這一篇文章要把構造確定性狀態機和look ahead講完的,當我真正要寫的時候發現東西太多,只好分成兩篇了。上一篇文章說道一個基本的狀態機是如何構造出來的,但是根據第一篇文章的說法,這一次設計的文法是為了直接構造出語法樹服務的,所以必然在執行狀態機的時候就要獲得構造語法樹的一切信息。如果自己開發過類似的東西就會知道,類似LALR這種東西,你可以很容易的把整個字符串分析完判斷他是不是屬於這個LALR狀態機描述的這個集合,但是你卻不能拿到語法分析所走的路徑,也就是說你很難直接拿到那顆分析樹。沒有分析樹肯定是做不出語法樹的。因此我們得把一些信息插入到狀態機裡面,才能最終把分析樹(並不一定真的要表達成樹,像上一篇文章的“分析路徑”(其實就是分析樹的一種可能的表達形式)所確定的語法樹構造出來。
就像《構造正則表達式引擎》一般給狀態機添加信息的方法,就是把一些附加的數據加到狀態與狀態之間的跳轉箭頭裡面去。為了形象的表達這個事情,我就拿第一篇文章的四則運算式子來舉例。在這裡我為了大家方便,重復一下這個文法的內容(除去了語樹書聲明):
token NAME = "[a-zA-Z_]/w*";
token NUMBER = "/d+(./d+)";
token ADD = "/+";
token SUB = "-";
token MUL = "/*";
token DIV = "//";
token LEFT = "/(";
token RIGHT = "/)";
token COMMA = ",";
rule NumberExpression Number
= NUMBER : value;
rule FunctionExpression Call
= NAME : functionName "(" [ Exp : arguments { "," Exp : arguments } ] ")";
rule Expression Factor
= !Number | !Call;
rule Expression Term
= !Factor;
= Term : firstOperand "*" Factor : secondOperand as BinaryExpression with { binaryOperator = "Mul" };
= Term : firstOperand "/" Factor : secondOperand as BinaryExpression with { binaryOperator = "Div" };
rule Expression Exp
= !Term;
= Exp : firstOperand "+" Term : secondOperand as BinaryExpression with { binaryOperator = "Add" };
= Exp : firstOperand "-" Term : secondOperand as BinaryExpression with { binaryOperator = "Sub" };
那麼我們把這個文發轉成狀態機之後,要給跳轉加上什麼呢?從直覺上來說,跳轉的時候我們會有六種要干的事情:
1、Create:這個文法創建的語法樹節點是某個類型的(區別於在這一刻給這個問法創建一個返回什麼類型的語法樹節點)
2、Set:給創建的語法樹節點的某個成員變量設置一個指定的值
3、Assign:給創建的語法樹節點的某個成員變量設置這一次跳轉的符號產生的語法樹節點(譬如說Exp = Exp: firstOperand “+” Term: secondOperand,走Term的時候,一個語法樹節點就會被assign給那個叫做secondOperand的成員變量)
4、Using:使用這一次跳轉的符號產生的語法樹節點來做這次文法的返回值(譬如說Factor = !Number | !Caller這一條)
5、Shift:略
6、Reduce:略
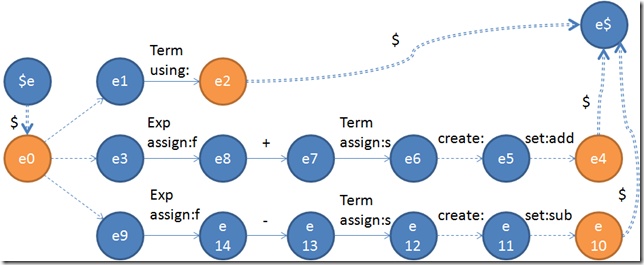
在這裡我們並沒有標記整個文法從哪一個非終結符開始,因為在實際過程中,其實分析師可以從任何一個文法開始的。譬如說寫IDE的時候,我們可能在某些情況下僅僅只需要分析一個表達式。所以考慮到每一個非終結符都有可能被用到,因此我們的“Token流開始”和“Token流結束”就會在每一個非終結符的狀態機中都出現。因此在第一步創建Epsilon PDA(下推自動機)的時候,就可以先直接生成。在這裡我們拿Exp做例子:
本欄目
面對這種狀態機,去除epsilon邊就不能跟處理正則表達式一樣簡單的去除了。首先,所有的終結狀態——也就是所有經過或者不經過epsilon邊之後,通過“Token流結束”符號連接到最後一個狀態的狀態,在這裡分別是e2、e6和e12——都是不能刪掉的。而且所有的“Token流開始”和“Token流結束”——也就是圖裡面的$轉換——是不能帶有信息的。所以我們就會看到e6後面的信息全部被移動到了e7->e6這條邊上面。由於create和set的流動性,我們這麼做對於狀態機的定義完全沒有影響。
到了這裡還沒完,因為這個狀態機還是有很多冗余的狀態的。譬如說e8和e14、e7和e13、e2和e6和e12實際上是可以合並的。合並的策略其實十分簡單:
1、如果我們有跳轉e0->e1和e0->e2,並且兩個跳轉所攜帶的token輸入和信息完全一致的話,那麼e1和e2就可以合並。
2、如果我們有跳轉e1->e0和e2->e0,並且兩個跳轉所攜帶的token輸入和信息完全一致的話,那麼e1和e2就可以合並。
所以對於e8和e14我們是完全可以合並的。那麼e7和e13怎麼辦呢?根據create和set的流動性,我們只要把這兩個東西挪到他的前面一個或者若干個跳轉去,那這兩個狀態就可以合並了。為了讓算法更加的簡單,我們遇到兩個跳轉類似的時候,總是先挪動create和set,然後再看看是不是真的可以合並。所以這一步處理完之後就會變成下面這個樣子:
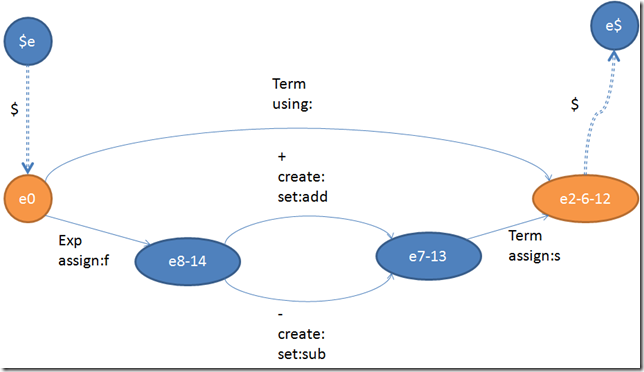
我們在不改變狀態機語義的情況下,把Exp的三個狀態機最終壓縮成了這個樣子。看過上一篇文章的同學們都知道,下一步就是要把所有的狀態機統統都連接起來了。關於在連接的時候如何具體操作轉換附帶的信息、以及做出一個確定性的下推狀態機的所有事情將在下一篇文章詳細解釋。