概述
C/C++最被人诟病的,可能是沒有一個內存垃圾回收器(確切是說沒有一個標准的垃圾回收器)。本文討論的內容要點是,在C/C++中實現一個最袖珍的、功能受限的垃圾回收器。這個垃圾回收器區別於其他垃圾回收器的主要特征是:
1. 袖珍但具實用性。整個垃圾回收器代碼行數100行左右(不含空白行),相當小巧。相對而言,它的功能也受到一定的限制。但是它在很多關鍵的場合恰恰非常有用。該垃圾回收器以實用作為首要目標,已經成為我和身邊一些同事編程的重要工具。
2. 高性能。區別於其他垃圾回收器的是這個袖珍的垃圾回收器非但不會導致性能的下降,反而提高了程序的時間性能(分配的速度加快)和空間性能(所占內存空間比正常的malloc/new少)。而這也是實用的重要指標。
本文算法並不復雜。技術上的東西,很多點明了就沒有什麼了,也許重要的意義是在於其首創性。其實,boost[1]提供的pool組件也在試圖提供類似功能的自動內存回收能力。但是實現相對復雜且低效(基於經典的mempool技術[2])。
現在,你也許急著想看看,這個垃圾回收器長什麼樣了。閒話少敘,那就讓我們就開始一步步把謎底揭開吧。
思路
理解該垃圾回收器的關鍵點在於,是在於理解它的目標:為一個復雜的局部過程(算法)提供自動內存回收的能力。
所謂局部過程(算法),是指那些算法復雜性較高,但在程序運行期所占的時間又比較短暫的過程[3]。例如:搜索引擎的搜索過程、讀盤/存盤過程、顯示(繪制)過程等等。通常這些過程可能需要申請很多內存,而且內存分配操作的入口點很多(就是調用new的地方很多),如果每調用一次new就要考慮應該在什麼地方delete就徒然浪費我們寶貴的腦力,使得我們無法把全力精力集中在算法本身的設計上。也許就是在這種情形下,C/C++程序員特別羨慕那些具備垃圾回收器的語言。相對而言,如果算法復雜性不高的話,我們的程序員完全有能力控制好new/delete的匹配關系。並且,這種“一切皆在我掌控之中”的感覺給了我們安全感[4]和滿足感。
因此,這個垃圾回收器的重心並不是要提供一個理論上功能完備的內存自動回收機制。它只是針對復雜性較高的局部過程(算法),為他們提供最實效的內存管理手段。從局部過程的一開始,你就只管去申請、使用內存,等到整個算法完成之後,這個過程申請的大部分內存(需要作為算法結果保留的例外),無論它是在算法的那個步驟申請的,均在這個結束點上由垃圾回收器自動銷毀。我們畫個示意圖:
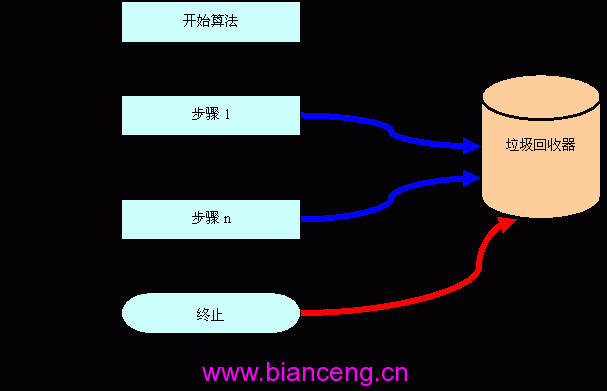
圖 1
規格
我們將該垃圾回收器命名為AutoFreeAlloc。它的接口很簡單,僅涉及兩個概念:Alloc、Clear。
typedef void (*FnDestructor)(void* pThis);
class AutoFreeAlloc
{
public:
~AutoFreeAlloc(); // 析構函數。自動調用Clear釋放內存
void* Alloc(size_t cb); // 類似於malloc(cb)
void* Alloc(size_t cb, FnDestructor fn); // 申請內存並指定析構函數
void Clear(); // 析構並釋放所有分配的對象
};
為了方便,提供輔助的New操作(上一篇中已經簡單介紹實現了),大體如下:
template <class Type, class AllocType>
Type* New(AllocType& alloc); // 類似於new Type
template <class Type, class ArgType1, class AllocType>
Type* New(ArgType1 arg1, AllocType& alloc); // 類似於new Type(arg1)
template <class Type, class AllocType>
Type* NewArray(size_t count, AllocType& alloc);// 類似於new Type[count]
使用樣例:
AutoFreeAlloc alloc;
int* intArray = (int*)alloc.Alloc(sizeof(int)*count);
int* intArray2 = NewArray<int>(count, alloc);
* obj = New<MyClass>(alloc);
MyClass* objWithArg = New<MyClass>(arg1, alloc);
MyClass* objArray = NewArray<MyClass>(count, alloc);
// …
// 現在,不能再訪問intArray, obj, objWithArg, objArray等數據了。
內存管理機制
class AutoFreeAlloc
{
public:
enum { BlockSize = 2048 };
private:
struct _MemBlock
{
_MemBlock* pPrev;
char buffer[BlockSize];
};
enum { HeaderSize = sizeof(_MemBlock) - BlockSize };
char* m_begin;
char* m_end;
};
AutoFreeAlloc類與內存管理相關的變量只有兩個:m_begin、m_end。單從變量定義來看,基本上很難看明白。但是有了下面這張示意圖就容易理解多了:

圖 2
整個AutoFreeAlloc申請的內存,通過_MemBlock構成鏈表。只要獲得了鏈表的頭,就可以遍歷整個內存鏈,釋放所有申請的內存了。而鏈表的頭(圖中標為_ChainHeader),可以通過m_begin計算得到:
_MemBlock* AutoFreeAlloc::_ChainHeader() const
{
return (_MemBlock*)(m_begin - HeaderSize);
}
為了使得_ChainHeader初始值為null,構造函數我們這樣寫:
AutoFreeAlloc::AutoFreeAlloc()
{
m_begin = m_end = (char*)HeaderSize;
}
★ 下面我們考慮內存分配過程。Alloc過程主要會有三種情況,具體代碼為:
void* AutoFreeAlloc::Alloc(size_t cb)
{
if (m_end – m_begin < cb)
{
if (cb >= BlockSize)
{
_MemBlock* pHeader = _ChainHeader();
_MemBlock* pNew = (_MemBlock*)m_alloc.allocate(HeaderSize + cb);
if (pHeader)
{
pNew->pPrev = pHeader->pPrev;
pHeader->pPrev = pNew;
}
else
{
m_end = m_begin = pNew->buffer;
pNew->pPrev = NULL;
}
return pNew->buffer; }
else
{
_MemBlock* pNew = (_MemBlock*)malloc(sizeof(_MemBlock));
pNew->pPrev = _ChainHeader();
m_begin = pNew->buffer;
m_end = m_begin + BlockSize;
}
}
return m_end -= cb;
}
1. 最簡單的情況,是當前_MemBlock還有足夠的自由內存(free memory),即:
m_end – m_begin >= cb
此時,只需要將m_end前移cb字節就可以了。我們畫個示意圖如下:

圖 3
2. 在當前的_MemBlock的自由內存(free memory)不足的情況下,我們就需要申請一個新的_MemBlock以供使用[5]。申請新的_MemBlock,我們又會遇到兩種情況:
a) 申請的字節數(即cb)小於一個_MemBlock所能夠提供的內存(即BlockSize)。
這種情況下,我們只需要將該_MemBlock作為新的當前_MemBlock掛到鏈表中,剩下的工作就和情形1完全類似。示意圖如下:

圖 4
b) 而在內存申請的字節數(即cb)大於或等於一個Block的字節數時,我們需要申請可使用內存超過正常長度(BlockSize)的_MemBlock。這個新生成的_MemBlock全部內存被用戶申請。故此,我們只需要修改_ChainHeader的pPrev指針,改為指向這一塊新申請的_MemBlock即可。m_begin、m_end保持不變(當前的_MemBlock還是當前的_MemBlock)。如圖:

圖 5
★ 下面我們考慮內存釋放(Clear)過程。這個過程就是遍歷_MemBlock釋放所有的_MemBlock的過程,非常簡單。代碼如下:
void AutoFreeAlloc::Clear()
{
_MemBlock* pHeader = _ChainHeader();
while (pHeader)
{
_MemBlock* pTemp = pHeader->pPrev;
free(pHeader);
pHeader = pTemp;
}
m_begin = m_end = (char*)HeaderSize;
}
自動析構過程
我們知道,C++以及其他面向對象語言為對象引入了構造、析構過程。這是一個了不起的發明。因為只有這樣,才能夠保證對象從一開始產生以來(剛new出來),到對象銷毀這整個過程,它的數據都處於完備狀態,是自洽的。
我們知道,C++以及其他面向對象語言為對象引入了構造、析構過程。這是一個了不起的發明。因為只有這樣,才能夠保證對象從一開始產生以來(剛new出來),到對象銷毀這整個過程,它的數據都處於完備狀態,是自洽的。
由於垃圾回收器負責對象的回收,它自然不止需要關注對象申請的內存的釋放,同時也需要保證,在對象銷毀之前它的析構過程被調用。上文我們為了關注內存管理過程,把自動析構過程需要的代碼均去除了。為了支持自動析構,AutoFreeAlloc類增加了以下成員:
class AutoFreeAlloc
{
struct _DestroyNode
{
_DestroyNode* pPrev;
FnDestructor fnDestroy;
};
_DestroyNode* m_destroyChain;
};
如果一個類存在析構,則它需要在Alloc內存的同時指定析構函數。代碼如下:
void* AutoFreeAlloc::Alloc(size_t cb, FnDestructor fn)
{
_DestroyNode* pNode = (_DestroyNode*)Alloc(sizeof(_DestroyNode) + cb);
pNode->fnDestroy = fn;
pNode->pPrev = m_destroyChain;
m_destroyChain = pNode;
return pNode + 1;
}
只要通過該Alloc函數申請的內存,我們在Clear中就可以調用相應的析構。當然,Clear函數需要補充自動析構相關的代碼:
void AutoFreeAlloc::Clear()
{
while (m_destroyChain)
{
m_destroyChain->fnDestroy(m_destroyChain + 1);
m_destroyChain = m_destroyChain->pPrev;
}
// 以下是原先正常的內存釋放過程…
}
時間性能分析
![]() void* AutoFreeAlloc::Alloc(size_t cb);
void* AutoFreeAlloc::Alloc(size_t cb);
OOP技術帶來一個內存上的問題是,對象粒度越來越細了,對象基本上都是小對象。這就對內存管理的性能提出了很高的要求。
如果我們以對象大小平均為32字節計算的話,每2048/32 = 64操作中,只有一次操作滿足m_end – m_begin < cb的條件。也就是說,在通常情況(63/64 = 98.4%的概率)下,Alloc操作只需要一個減法操作就完成內存分配。
我說這是世界上最快速的內存分配算法,也許你對此仍然抱有懷疑態度。但是可以肯定的一點是,要突破它的性能極限我覺得已經很難很難了。
![]() void AutoFreeAlloc::Clear();
void AutoFreeAlloc::Clear();
一般內存管理器通常一次內存分配操作就需調用相應的一次Free操作。但是AutoFreeAlloc不針對每一個Alloc進行釋放,而是針對每一個_MemBlock。仍假設對象平均大小為32字節的話,也就是相當於把64次Alloc操作合並,為其提供一次相應的Free過程。
★ 結論:AutoFreeAlloc在時間上的性能,大約比普通的malloc/free的快64倍。
空間性能分析
我們知道,一般內存管理器為了將用戶申請的內存塊管理起來,除了用戶需要的cb字節內存外,通常額外還提供一個內存塊的頭結構,通過這個頭結構將內存串連成為一個鏈表。一般來講,這個頭結構至少有兩項(可能還不止),示意如下:
struct MemHeader
{
MemHeader* pPrev;
size_t cb;
};
仍然假設平均Alloc一次的內存為32字節。則一次malloc分配過程,就會浪費8/32 = 25%的內存。並且由於大量的小對象存在,整個內存中的碎片(指那些自由但無法被使用的內存)將特別嚴重。
而AutoFreeAlloc的Alloc沒有如何額外開銷。整個AutoFreeAlloc,只有在將_MemBlock串為鏈表的有一個額外的pPrev指針,加上_MemBlock是malloc出來的,有額外的8字節開銷。總計浪費(4+8)/2048 = 0.6%的內存,幾乎可以忽略不計。
後記
AutoFreeAlloc於2004-5-21開發,只有100行的代碼量。但是,這個組件獲得了空前的成功,它的應用范圍逐步擴大,超過了我最初實現這個組件時的預計。
我漸漸冷靜下來,考慮這其中蘊涵的道理。我逐步領會到了,它的成功之處,不是它在時間、空間性能的高效,而是在於它幫助C++程序員解決了最大的難題——內存管理。雖然,這個解決方案並不是完整的。
AutoFreeAlloc是一個切入點,從它身上,讓我明白了C++的new/delete的不合理;STL引入的allocator是一個切入點,從它身上,讓我明白了內存管理有很強的區域性,在不同的區域(局部過程)中對allocator的需求卻又不盡相同。
我們前文也提到了一個例子:一個文檔打開,編輯,直到文檔被最終關閉,這個完成算不算局部過程呢?在AutoFreeAlloc解決的問題域來看,顯然我們無法認為它是一個局部過程。但是,從其他allocator角度來講,是否就有可能把它作為一個局部過程了呢?
正是考慮到AutoFreeAlloc的缺陷,我們需要一個功能更強的垃圾回收器。這就是我們下一次需要討論的組件了。
最後,仍然需要明確的一點時。我們很難也不需要實現一個象Java、C#那樣的垃圾回收器。提供一個具備特定的內存管理能力的allocator才是正道。
[1] 請參考boost官方網站http://www.boost.org/。
[2] mempool技術是一個很成熟的內存管理技術,被sgi-stl、boost等C++庫實現者采用。
[3] 真正是否要把一個過程定義為局部過程,完全取決於設計者本身。例如,一個文檔打開,編輯,直到文檔被最終關閉,這個完成算不算局部過程呢?在大部分情況下我們認為它不是一個局部過程,但是下回我們將專門討論是否有可能,以及應該如何將它作為一個局部過程。
[4] 那些提供了垃圾回收器的語言的使用者,顯然也有應用了垃圾回收器的煩惱。例如C#在調用非管制代碼(如調用Win32 api)時,這些問題變得突出,一個疏忽就留下潛在隱患。這與C/C++程序員遺憾語言沒有垃圾回收器的感覺類似。
[5] 當前的_MemBlock的自由內存很可能還是有的,但是不足cb字節。此時我們說這裡有內存碎片(memory piece):這些碎片盡管沒有人使用,但是我們把它棄而不用。
附加說明:
本文所描述的AutoFreeAlloc組件,完整代碼可在WINX庫(http://sourceforge.net/projects/winx)中找到。你也可以通過以下鏈接在線浏覽:
AutoFreeAlloc完整源代碼:http://winx.cvs.sourceforge.net/winx/stdext/include/stdext/memory/AutoFreeAlloc.h?view=markup
另外, 這篇文章寫的時間較早,其規格雖然與現在的AutoFreeAlloc一樣,但成員函數名改了:
Alloc -> allocate
Clear -> clear
之所以這樣,是因為AutoFreeAlloc被納入stdext庫(這個庫可獨立於winx界面庫,是winx界面庫的基礎)。stdext庫的命名風格盡量與STL的命名習慣一致。