前些時候學習編譯原理,同時也為 DocWizard 做詞法分析技術的准備,於是便想出了一種詞法分析內核。這個分析內核可以在不改變代碼的情況下分析不同的 DFA。
分析器的基本構造
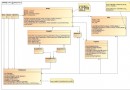
如圖一所示,腳本 Scripts 進入分析內核 ParsingKernel,分析內核根據 DFA 規則作詞法分析,生成單詞序列 WordsSequence。

圖一
其中的 DFA Rules 其實就是 DFA 中的狀態轉換規則。分析內核在工作時需要查閱規則表。只要更換這個規則表,就可以分析不同的詞法。
工作原理
例子程序中的 CStateChangeRule 代表一條轉換規則。它由如下三個數據構成:
當前狀態編號:int nCurState
下一個狀態編號:int nNextState
需要匹配的字符:CHAR_RANGE route[ROUTE_BUF_LEN]
內核在剛開始工作的時候,設定當前狀態為 0,然後對輸入字符串 pszLine 進行掃描。Route()函數根據當前需要處理的字符和當前狀態,計算出下一個狀態。Accept()函數負責接收一個單詞。
void CAjaxParserDlg::OnParse()
{
char *pszLine = " void CAjaxParserDlg::OnParse() +12.3 12.3 -12.3 -.12 +.12 .12 +12. -12. 12. .023 ";
int i=0, nLen, nState=0, nNext=-1, nStart;
nLen = strlen(pszLine);
while(i<nLen)
{
if(nState==0)
{
nStart = i;
}
nNext = Route(nState, *(pszLine+i));
Accept(nState, nNext, pszLine+nStart, i-nStart);
if(!(nState!=0 && nNext==0))
i++;
nState = nNext;
}
Accept(nState, 0, pszLine+nStart, i-nStart);
}
Route()函數是一個很重要的函數。它負責查閱 DFA 規則表,檢索當前狀態為 nCurState,並且接受字符 c 的規則。如果檢索到了,則返回下一個狀態的編號。例子程序中的實現代碼效率不高,因為它采用線性搜索。各位可以將其改為更快的搜索算法。
int CAjaxParserDlg::Route(int nCurState, BYTE c)
{
int i, nSize;
nSize = m_ruleArr.GetSize();
CStateChangeRule rule;
for(i=0; i<nSize; i++)
{
rule = m_ruleArr[i];
if(rule.nCurState==nCurState
&& InRoute(c, rule.route))
{
return rule.nNextState;
}
}
if(nCurState==0)
{
Logln("start state, cannot recognize char");
}
// return to state 0 the start state
return 0;
}
Accept()函數比較簡單,它負責接受分析得到的單詞。如果當前狀態是終止狀態,並且下一個狀態將要轉向狀態0,則說明現在已經是一個完整的單詞了,並且下一個字符將不屬於這個單詞。這個時候 Accept() 函數調用 Log() 將這個單詞輸出。在實際應用中,往往需要把單詞存放到一個單詞數組。
void CAjaxParserDlg::Accept(int nCurrent, int nNext, LPCTSTR pszLine, int nLen)
{
char psz[256];
if(nNext==0 && nCurrent!=0)
{
sprintf(psz, "Accept word(s:%d)[", nCurrent);
Log(psz);
strncpy(psz, pszLine, nLen);
psz[nLen] = 0;
Log(psz);
if(!(m_stateArr[nCurrent].nFlag&STATE_END))
{
Logln("]unrecogized char, can''t accept");
}
else
{
Logln("]");
}
}
}
規則表
分析內核賴以工作的“規則”采用 CStateChangeRule 來表示。例子程序中的規則表的初始化在 CAjaxParserDlg::OnInitDialog() 函數中。如下所示是一個規則的建立。
CStateChangeRule rule; rule.nCurState = 0;
rule.nNextState = 1;
rule.route[0].byStart = ''_''; rule.route[0].byEnd = ''_'';
rule.route[1].byStart = ''A''; rule.route[1].byEnd = ''Z'';
rule.route[2].byStart = ''a''; rule.route[2].byEnd = ''z'';
m_ruleArr.Add(rule);
rule.Clear();
例子程序中的DFA如圖二所示。
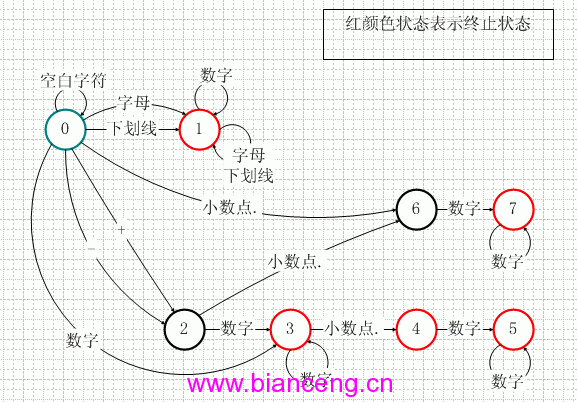
圖二
狀態屬性
當然除了規則以外,另一個重要的數據就是狀態的屬性,分析內核需要知道一個狀態是不是終止態。m_stateArr 記錄了所有的狀態的屬性。這個數組的下標代表狀態編號,數組元素的值是狀態屬性。
結束語
可能各位都知道,其實作詞法分析挺簡單的,但是語法分析十分的困難。據我所知,語法分析尚且不十分的形式化,也就是說理論並非十分完善。這將對構造語法分析器帶來困難。我做 DocWizard 的時候並沒有采用教科書上的語法分析方法,做的很麻煩,而且也不能保證正確。說實在的做得挺濫的。呵呵~~ 希望以後能做得好一些。
下一步我得好好的學習 lex 和 yacc 了。畢竟用它們來構造分析器還是挺輕松的。