關鍵字 :
Pentium,處理器,單指令多數據流擴展指令,SSE,指令集
概要 :
隨著Intel Pentium III處理器的發布,給程序設計人員又帶來了許多新的特性。利用這些新特性,程序員可以為用戶創造出更好的產品. Pentium III和Pentium III Xeon(至強處理器)的許多新特性,可以使她能夠比Pentium II和Pentium II Xeon處理器有更快的運行速度,這些新特性包括一個處理器序列號(unique processor ID)和新增SSE處理器指令集,這些新的指令集就像Pentium II在經典Pentium的基礎上添加的MMX指令集.
1. 使用SSE
在具體描述了SSE指令集以後,讓我們看看怎樣才能在應用程序中使用他們呢.
1.1 匯編語言
傳統地,程序員希望能夠使用匯編語言來利用新處理器的新特性.通常這是必須的,因為高級的程序開發工具只有在處理器正式推出以後的某個適當的時間才會由新版本發布支持. Pentium III的情況也是這樣.現在,只有Intel的C/C++編譯器和Microsoft Macro Assembler(6.11d及以上版本)才認識新的SSE指令集.
這裡有一個矛盾的地方:如果用純匯編語言來寫一個大型的、復雜的應用程序是非常困難的,但是這樣寫出來的代碼執行速度又是最快的.
我們也可以使用SSE SDK(Software Developers Kit,軟件開發工具包)開發包,Intel在開發包中提供了兩種編程機制去使用SSE指令集:一個intrinsics庫和一個表示SSE定義的新數據類型的C++類.使用這些機制比單純用匯編語言簡單.這是很明顯的,因為這樣程序員再也不用由自己去管理SSE的寄存器了,可以很方便的創建出大型的應用程序.但是這種機制寫出的代碼又比用匯編語言寫的代碼執行速度慢了.圖6說明了這三種開發方法在程序執行速度和開發困難程度之間的矛盾.

圖六: 在不同開發環境下的程序執行速度和開發困難程度之間的矛盾
1.1.1 示例:乘法
假設有兩個128位的數a和b分別存儲在寄存器xmm1和xmm2中,他們的計算結果保存在寄存器xmm0中.用C語言嵌入匯編的代碼如下:
#include
...
_asm {
push esi;
push edi;
; a is loaded into xmm1
; b is loaded into xmm2
mov xmm0, xmm1;
mulps xmm0, xmm2;
; store result into c
pop edi;
pop esi;
}
...
圖7用圖表來表示了這種包裹乘法(packed multiplication)的計算
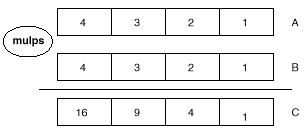
圖七:包裹乘法計算
1.2 Intrinsics庫
使用Intrinsics庫是第一種附加的編程機制.Intrinsics庫為C語言提供了一個使用SSE指令集的接口.所有的SSE指令在這個庫中都被包裝成了C函數.兩個包裹數據(packed data)相加的匯編指令是addps.相應的,在intrinsics庫中將兩個包裹數據相加的對應函數是_mm_add_ps.為了配合這些新增的函數,intrinsics庫還定義了一個新的數據類型(__m128)來表示128位長的數據,可以用來保存4個單精度浮點數.
要使用intrinsics庫,還需要在程序中包含(include)xmmintrin.h頭文件.
1.2.1 示例:乘法
假設有兩個128位數a和b,他們的計算結果將被保存在另一個128位數c中.a,b和c都是__m128數據.__m128是128位數據類型,已經在頭文件xmmintrin.h中定義了.函數_mm_set_ps功能是把他的4個參數按照第一個參數為最高位、最後一個參數為最低位的順序排列組合成一個128數.
#include
...
__m128 a, b, c;
a = _mm_set_ps(4, 3, 2, 1)
b = _mm_set_ps(4, 3, 2, 1)
c = _mm_set_ps(0, 0, 0, 0)
c = _mm_mul_ps(a, b);
...
1.3 C++
第二種附加的編程機制是使用C++語言.SSE SDK開發包提供了一個C++類:F32vec4,用來處理和表示一個128位的新數據類型.所有的新數據類型的操作都被封裝在這個類中了.在類的內部,他也是使用intrinsics庫的.
要使用這個C++類,,還必須在程序中包含(include)fvec.h頭文件.
1.3.1 示例:乘法
我們再次假設有兩個128位的數a和b,他們的計算結果放在另一個128位數c中.所有的數據都定義成F32vec4類.類的構造函數功能就相當於_mm_set_ps函數.
#include ...
F32vec4 a(4, 3, 2, 1), b(4, 3, 2, 1), c(0, 0, 0, 0);
...
c =a * b;
...
1.4 編譯器支持
前面已經說過,只有Intel的C\C++編譯器和Microsoft的Macro Assembler支持新的SSE指令集.Intel編譯器已經整合到Microsoft的Visual Studio集成開發環境中了.Visual Studio集成開發環境可以被配置成使用Intel的編譯器來編譯整個工程或者工程中的某個文件.
2. SSE指令詳細資料
在我們介紹SSE指令用法的例子以前,讓我們先來看看SSE指令集的所有指令列表.
Arithmetic Instructions(算術指令)
addps, addss
subps, subss
mulps, mulss
divps, divss
sqrtps, sqrtss
maxps, maxss
minps, minss
Logical Instructions(邏輯指令)
andps
andnps
orps
xorps
Compare Instructions(比較指令)
cmpps, cmpss
comiss
ucomiss
Shuffle Instructions(清洗指令)
shufps
unpchkps
unpcklps
Conversion Instructions(轉換指令)
cvtpi2ps, cvtpi2ss
cvtps2pi, cvtss2si
Data Movement Instructions(數據移動指令)
movaps
movups
movhps
movlps
movmskps
movss
State Management Instructions(狀態管理指令)
ldmxcsr
fxsave
stmxscr
fxstor
Cacheability Control Instructions(cache控制指令)
maskmovq
movntq
movntps
prefetch
sfence
Additional SIMD Integer Instructions(附加的SIMD整數指令)
pextrw
pinsrw
pmaxub, pmaxsw
pminub, pminsw
pmovmskb
pmulhuw
pshufw
3. 例子
在這一節,我們將介紹幾個例子來幫你理解Pentium III的SSE指令集應用.在每個例子中,我們都將介紹三種解決方案,分別使用匯編語言、intrinsics庫和C++類.附加例子將在下一部分的附加示例節中介紹.
3.1 包裹乘法
在前面我們已經用三種不同的開發機制介紹了兩個包裹數據的乘法計算,這三種機制分別是使用匯編語言、intrinsics庫和C++類來編寫.
3.2 比較操作
讓我們來考慮一下比較的事件.如果不使用SSE,我們每次只能對一對浮點數進行比較.使用了SSE以後,可以同時對4對浮點數進行比較.
在C和C++中比較4對浮點數,我們可以像下面一樣寫一個循環,把每次的比較放在循環裡面.另外我們還需要定義保存比較結果的變量.代碼可以類似於下面的例子.
float a[4], b[4]
int i, c[4];
// assume that a contains 4.5 6.7 2.3 and 1.2
// assume that b contains 4.3 6.9 2.0 and 1.5
for (i = 0;i < 4; i++ )
c[i] = a[i] < b[i];
// take action on comparison result
在SSE指令集中,比較指令是cmpps,她有兩個128位的操作數和一個選項參數.選項參數是用來指明指令比較類型的:是大於、小於、大於等於還是小於等於的比較.cmpps指令用來比較4對浮點數的大小,並將比較結果放在第一個操作數中.如果比較的結果是真,相對應的元素將被置為FFFFFFFF,如果為非,則被置為00000000.這個結果還可以被映射到一個普通的(8位或者16位)寄存器中,這個普通的寄存器用一個位來映射SSE寄存器的一個元素.我們可以從這個映射的寄存器來得到比較的結果.
下面舉例來說明cmpps指令的用法.
; assume that xmm0 contains 4.5 6.7 2.3 and 1.2
; assume that xmm1 contains 4.3 6.9 2.0 and 1.5
; compare for less than condition
cmpps xmm0, xmm1, 1;
; move result of comparison as a mask into eax
movmskps eax, xmm0;
; test eax against some value
test eax, 5;
; jump if true, to the given label
je match13
這個操作也可以用圖8的圖示來表示.
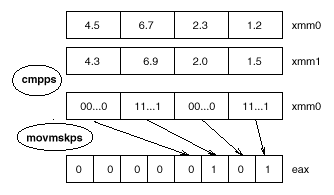
圖八 :比較運算
3.3 分支移除
通常,在程序中我們喜歡用下面的條件語句.
a =(a < b) ? c :d;
在上面的代碼中,比較操作影響著後面代碼的執行路徑.如果我們能夠移除條件判斷,程序將能執行的更快.下面的這段匯編代碼將比上面的代碼執行得更快,這不僅僅是因為下面的代碼是用匯編語言寫的,更重要的是這裡的分支判斷已經被移除了.
; assume that xmm0 stores a, xmm1 stores b
; assume that xmm3 stores c and xmm4 stores d
cmpps xmm0, xmm1, 1;
movaps xmm2, xmm0;
andps xmm0, xmm3;
andnps xmm2, xmm4;
orps xmm0, xmm2;
; xmm0 contains the result, which is either c or d