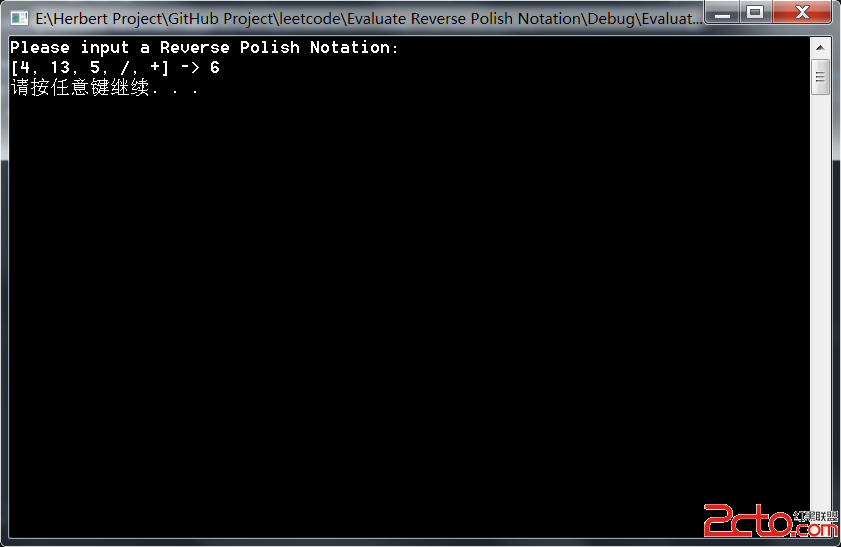
printf()函數參數格式詳解
printf的格式控制的完整格式:
% - 0 m.n l或h 格式字符
下面對組成格式說明的各項加以說明:
①%:表示格式說明的起始符號,不可缺少。
②-:有-表示左對齊輸出,如省略表示右對齊輸出。
③0:有0表示指定空位填0,如省略表示指定空位不填。
④m.n:m指域寬,即對應的輸出項在輸出設備上所占的字符數。N指精度。用於說明輸出的實型數的小數位數。為指定n時,隱含的精度為n=6位。
⑤l或h:l對整型指long型,對實型指double型。h用於將整型的格式字符修正為short型。
——————————————————————————————————————-
格式字符
格式字符用以指定輸出項的數據類型和輸出格式。
①d格式:用來輸出十進制整數。有以下幾種用法:
%d:按整型數據的實際長度輸出。
%md:m為指定的輸出字段的寬度。如果數據的位數小於m,則左端補以空格,若大於m,則按實際位數輸出。
%ld:輸出長整型數據。
②o格式:以無符號八進制形式輸出整數。對長整型可以用"%lo"格式輸出。同樣也可以指定字段寬度用“%mo”格式輸出。
例:
main()
{ int a = -1;
printf("%d, %o", a, a);
}
運行結果:-1,177777
程序解析:-1在內存單元中(以補碼形式存放)為(1111111111111111)2,轉換為八進制數為(177777)8.
③x格式:以無符號十六進制形式輸出整數。對長整型可以用"%lx"格式輸出。同樣也可以指定字段寬度用"%mx"格式輸出。
④u格式:以無符號十進制形式輸出整數。對長整型可以用"%lu"格式輸出。同樣也可以指定字段寬度用“%mu”格式輸出。
⑤c格式:輸出一個字符。
⑥s格式:用來輸出一個串。有幾中用法
%s:例如:printf("%s", "CHINA")輸出"CHINA"字符串(不包括雙引號)。
%ms:輸出的字符串占m列,如字符串本身長度大於m,則突破獲m的限制,將字符串全部輸出。若串長小於m,則左補空格。
%-ms:如果串長小於m,則在m列范圍內,字符串向左靠,右補空格。
%m.ns:輸出占m列,但只取字符串中左端n個字符。這n個字符輸出在m列的右側,左補空格。
%-m.ns:其中m、n含義同上,n個字符輸出在m列范圍的左側,右補空格。如果n>m,則自動取n值,即保證n個字符正常輸出。
⑦f格式:用來輸出實數(包括單、雙精度),以小數形式輸出。有以下幾種用法:
%f:不指定寬度,整數部分全部輸出並輸出6位小數。
%m.nf:輸出共占m列,其中有n位小數,如數值寬度小於m左端補空格。
%-m.nf:輸出共占n列,其中有n位小數,如數值寬度小於m右端補空格。
⑧e格式:以指數形式輸出實數。可用以下形式:
%e:數字部分(又稱尾數)輸出6位小數,指數部分占5位或4位。
%m.ne和%-m.ne:m、n和“-”字符含義與前相同。此處n指數據的數字部分的小數位數,m表示整個輸出數據所占的寬度。
⑨g格式:自動選f格式或e格式中較短的一種輸出,且不輸出無意義的零。
——————————————————————————————————————-
關於printf函數的進一步說明:
如果想輸出字符"%",則應該在“格式控制”字符串中用連續兩個%表示,如:
printf("%f%%", 1.0/3);
輸出0.333333%.
——————————————————————————————————————-
對於單精度數,使用%f格式符輸出時,僅前7位是有效數字,小數6位。
對於雙精度數,使用%lf格式符輸出時,前16位是有效數字,小數6位。
*/
/*
STL中map用法詳解
Map是STL的一個關聯容器,它提供一對一(其中第一個可以稱為關鍵字,每個關鍵字只能在map中出現一次,第二個可能稱為該關鍵字的值)的數據處理能力,由於這個特性,它完成有可能在我們處理一對一數據的時候,在編程上提供快速通道。這裡說下map內部數據的組織,map內部自建一顆紅黑樹(一種非嚴格意義上的平衡二叉樹),這顆樹具有對數據自動排序的功能,所以在map內部所有的數據都是有序的,後邊我們會見識到有序的好處。
下面舉例說明什麼是一對一的數據映射。比如一個班級中,每個學生的學號跟他的姓名就存在著一一映射的關系,這個模型用map可能輕易描述,很明顯學號用int描述,姓名用字符串描述(本篇文章中不用char *來描述字符串,而是采用STL中string來描述),下面給出map描述代碼:
Map<int, string> mapStudent;
1. map的構造函數
map共提供了6個構造函數,這塊涉及到內存分配器這些東西,略過不表,在下面我們將接觸到一些map的構造方法,這裡要說下的就是,我們通常用如下方法構造一個map:
Map<int, string> mapStudent;
2. 數據的插入
在構造map容器後,我們就可以往裡面插入數據了。這裡講三種插入數據的方法:
第一種:用insert函數插入pair數據,下面舉例說明(以下代碼雖然是隨手寫的,應該可以在VC和GCC下編譯通過,大家可以運行下看什麼效果,在VC下請加入這條語句,屏蔽4786警告 #pragma warning (disable:4786) )
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
第二種:用insert函數插入value_type數據,下面舉例說明
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(map<int, string>::value_type (1, “student_one”));
mapStudent.insert(map<int, string>::value_type (2, “student_two”));
mapStudent.insert(map<int, string>::value_type (3, “student_three”));
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
第三種:用數組方式插入數據,下面舉例說明
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent[1] = “student_one”;
mapStudent[2] = “student_two”;
mapStudent[3] = “student_three”;
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
以上三種用法,雖然都可以實現數據的插入,但是它們是有區別的,當然了第一種和第二種在效果上是完成一樣的,用insert函數插入數據,在數據的插入上涉及到集合的唯一性這個概念,即當map中有這個關鍵字時,insert操作是插入數據不了的,但是用數組方式就不同了,它可以覆蓋以前該關鍵字對應的值,用程序說明
mapStudent.insert(map<int, string>::value_type (1, “student_one”));
mapStudent.insert(map<int, string>::value_type (1, “student_two”));
上面這兩條語句執行後,map中1這個關鍵字對應的值是“student_one”,第二條語句並沒有生效,那麼這就涉及到我們怎麼知道insert語句是否插入成功的問題了,可以用pair來獲得是否插入成功,程序如下
Pair<map<int, string>::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(map<int, string>::value_type (1, “student_one”));
我們通過pair的第二個變量來知道是否插入成功,它的第一個變量返回的是一個map的迭代器,如果插入成功的話Insert_Pair.second應該是true的,否則為false.
下面給出完成代碼,演示插入成功與否問題
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
Pair<map<int, string>::iterator, bool> Insert_Pair;
Insert_Pair = mapStudent.insert(pair<int, string>(1, “student_one”));
If(Insert_Pair.second == true)
{
Cout<<”Insert Successfully”<<endl;
}
Else
{
Cout<<”Insert Failure”<<endl;
}
Insert_Pair = mapStudent.insert(pair<int, string>(1, “student_two”));
If(Insert_Pair.second == true)
{
Cout<<”Insert Successfully”<<endl;
}
Else
{
Cout<<”Insert Failure”<<endl;
}
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
大家可以用如下程序,看下用數組插入在數據覆蓋上的效果
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent[1] = “student_one”;
mapStudent[1] = “student_two”;
mapStudent[2] = “student_three”;
map<int, string>::iterator iter;
for(iter = mapStudent.begin(); iter != mapStudent.end(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
3. map的大小
在往map裡面插入了數據,我們怎麼知道當前已經插入了多少數據呢,可以用size函數,用法如下:
Int nSize = mapStudent.size();
4. 數據的遍歷
這裡也提供三種方法,對map進行遍歷
第一種:應用前向迭代器,上面舉例程序中到處都是了,略過不表
第二種:應用反相迭代器,下面舉例說明,要體會效果,請自個動手運行程序
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
map<int, string>::reverse_iterator iter;
for(iter = mapStudent.rbegin(); iter != mapStudent.rend(); iter++)
{
Cout<<iter->first<<” ”<<iter->second<<end;
}
}
第三種:用數組方式,程序說明如下
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
int nSize = mapStudent.size()
//此處有誤,應該是 for(int nIndex = 1; nIndex <= nSize; nIndex++)
//by rainfish
for(int nIndex = 0; nIndex < nSize; nIndex++)
{
Cout<<mapStudent[nIndex]<<end;
}
}
5. 數據的查找(包括判定這個關鍵字是否在map中出現)
在這裡我們將體會,map在數據插入時保證有序的好處。
要判定一個數據(關鍵字)是否在map中出現的方法比較多,這裡標題雖然是數據的查找,在這裡將穿插著大量的map基本用法。
這裡給出三種數據查找方法
第一種:用count函數來判定關鍵字是否出現,其缺點是無法定位數據出現位置,由於map的特性,一對一的映射關系,就決定了count函數的返回值只有兩個,要麼是0,要麼是1,出現的情況,當然是返回1了
第二種:用find函數來定位數據出現位置,它返回的一個迭代器,當數據出現時,它返回數據所在位置的迭代器,如果map中沒有要查找的數據,它返回的迭代器等於end函數返回的迭代器,程序說明
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
map<int, string>::iterator iter;
iter = mapStudent.find(1);
if(iter != mapStudent.end())
{
Cout<<”Find, the value is ”<<iter->second<<endl;
}
Else
{
Cout<<”Do not Find”<<endl;
}
}
第三種:這個方法用來判定數據是否出現,是顯得笨了點,但是,我打算在這裡講解
Lower_bound函數用法,這個函數用來返回要查找關鍵字的下界(是一個迭代器)
Upper_bound函數用法,這個函數用來返回要查找關鍵字的上界(是一個迭代器)
例如:map中已經插入了1,2,3,4的話,如果lower_bound(2)的話,返回的2,而upper-bound(2)的話,返回的就是3
Equal_range函數返回一個pair,pair裡面第一個變量是Lower_bound返回的迭代器,pair裡面第二個迭代器是Upper_bound返回的迭代器,如果這兩個迭代器相等的話,則說明map中不出現這個關鍵字,程序說明
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent[1] = “student_one”;
mapStudent[3] = “student_three”;
mapStudent[5] = “student_five”;
map<int, string>::iterator iter;
iter = mapStudent.lower_bound(2);
{
//返回的是下界3的迭代器
Cout<<iter->second<<endl;
}
iter = mapStudent.lower_bound(3);
{
//返回的是下界3的迭代器
Cout<<iter->second<<endl;
}
iter = mapStudent.upper_bound(2);
{
//返回的是上界3的迭代器
Cout<<iter->second<<endl;
}
iter = mapStudent.upper_bound(3);
{
//返回的是上界5的迭代器
Cout<<iter->second<<endl;
}
Pair<map<int, string>::iterator, map<int, string>::iterator> mapPair;
mapPair = mapStudent.equal_range(2);
if(mapPair.first == mapPair.second)
{
cout<<”Do not Find”<<endl;
}
Else
{
Cout<<”Find”<<endl;
}
mapPair = mapStudent.equal_range(3);
if(mapPair.first == mapPair.second)
{
cout<<”Do not Find”<<endl;
}
Else
{
Cout<<”Find”<<endl;
}
}
6. 數據的清空與判空
清空map中的數據可以用clear()函數,判定map中是否有數據可以用empty()函數,它返回true則說明是空map
7. 數據的刪除
這裡要用到erase函數,它有三個重載了的函數,下面在例子中詳細說明它們的用法
#include <map>
#include <string>
#include <iostream>
Using namespace std;
Int main()
{
Map<int, string> mapStudent;
mapStudent.insert(pair<int, string>(1, “student_one”));
mapStudent.insert(pair<int, string>(2, “student_two”));
mapStudent.insert(pair<int, string>(3, “student_three”));
//如果你要演示輸出效果,請選擇以下的一種,你看到的效果會比較好
//如果要刪除1,用迭代器刪除
map<int, string>::iterator iter;
iter = mapStudent.find(1);
mapStudent.erase(iter);
//如果要刪除1,用關鍵字刪除
Int n = mapStudent.erase(1);//如果刪除了會返回1,否則返回0
//用迭代器,成片的刪除
//一下代碼把整個map清空
mapStudent.earse(mapStudent.begin(), mapStudent.end());
//成片刪除要注意的是,也是STL的特性,刪除區間是一個前閉後開的集合
//自個加上遍歷代碼,打印輸出吧
}
8. 其他一些函數用法
這裡有swap,key_comp,value_comp,get_allocator等函數,感覺到這些函數在編程用的不是很多,略過不表,有興趣的話可以自個研究
9. 排序
這裡要講的是一點比較高深的用法了,排序問題,STL中默認是采用小於號來排序的,以上代碼在排序上是不存在任何問題的,因為上面的關鍵字是int型,它本身支持小於號運算,在一些特殊情況,比如關鍵字是一個結構體,涉及到排序就會出現問題,因為它沒有小於號操作,insert等函數在編譯的時候過不去,下面給出兩個方法解決這個問題
第一種:小於號重載,程序舉例 #include <map>
#include <string>
Using namespace std;
Typedef struct tagStudentInfo
{
Int nID;
String strName;
}StudentInfo, *PStudentInfo; //學生信息
Int main()
{
int nSize;
//用學生信息映射分數
map<StudentInfo, int>mapStudent;
map<StudentInfo, int>::iterator iter;
StudentInfo studentInfo;
studentInfo.nID = 1;
studentInfo.strName = “student_one”;
mapStudent.insert(pair<StudentInfo, int>(studentInfo, 90));
studentInfo.nID = 2;
studentInfo.strName = “student_two”;
mapStudent.insert(pair<StudentInfo, int>(studentInfo, 80));
for (iter=mapStudent.begin(); iter!=mapStudent.end(); iter++)
cout<<iter->first.nID<<endl<<iter->first.strName<<endl<<iter->second<<endl;
}
以上程序是無法編譯通過的,只要重載小於號,就OK了,如下:
Typedef struct tagStudentInfo
{
Int nID;
String strName;
Bool operator < (tagStudentInfo const& _A) const
{
//這個函數指定排序策略,按nID排序,如果nID相等的話,按strName排序
If(nID < _A.nID) return true;
If(nID == _A.nID) return strName.compare(_A.strName) < 0;
Return false;
}
}StudentInfo, *PStudentInfo; //學生信息
第二種:仿函數的應用,這個時候結構體中沒有直接的小於號重載,程序說明
#include <map>
#include <string>
Using namespace std;
Typedef struct tagStudentInfo
{
Int nID;
String strName;
}StudentInfo, *PStudentInfo; //學生信息
Classs sort
{
Public:
Bool operator() (StudentInfo const &_A, StudentInfo const &_B) const
{
If(_A.nID < _B.nID) return true;
If(_A.nID == _B.nID) return _A.strName.compare(_B.strName) < 0;
Return false;
}
};
Int main()
{
//用學生信息映射分數
Map<StudentInfo, int, sort>mapStudent;
StudentInfo studentInfo;
studentInfo.nID = 1;
studentInfo.strName = “student_one”;
mapStudent.insert(pair<StudentInfo, int>(studentInfo, 90));
studentInfo.nID = 2;
studentInfo.strName = “student_two”;
mapStudent.insert(pair<StudentInfo, int>(studentInfo, 80));
}
10. 另外
由於STL是一個統一的整體,map的很多用法都和STL中其它的東西結合在一起,比如在排序上,這裡默認用的是小於號,即less<>,如果要從大到小排序呢,這裡涉及到的東西很多,在此無法一一加以說明。
還要說明的是,map中由於它內部有序,由紅黑樹保證,因此很多函數執行的時間復雜度都是log2N的,如果用map函數可以實現的功能,而STL Algorithm也可以完成該功能,建議用map自帶函數,效率高一些。
下面說下,map在空間上的特性,否則,估計你用起來會有時候表現的比較郁悶,由於map的每個數據對應紅黑樹上的一個節點,這個節點在不保存你的數據時,是占用16個字節的,一個父節點指針,左右孩子指針,還有一個枚舉值(標示紅黑的,相當於平衡二叉樹中的平衡因子),我想大家應該知道,這些地方很費內存了吧,不說了……
*/
/*深入理解sizeof
最近在論壇裡總有人問關於sizeof的問題,並且本人對這個問題也一直沒有得到很好的解決,索性今天對它來個較為詳細的總結,同時結合strlen進行比較,如果能對大家有點點幫助,這是我最大的欣慰了。
一、好首先看看sizeof和strlen在MSDN上的定義:
首先看一MSDN上如何對sizeof進行定義的:
sizeof Operator
sizeof expression
The sizeof keyword gives the amount of storage, in bytes, associated with a variable or a type
(including aggregate types). This keyword returns a value of type size_t.
The expression is either an identifier or a type-cast expression (a type specifier
enclosed in parentheses).
When applied to a structure type or variable, sizeof returns the actual size, which may include
padding bytes inserted for alignment. When applied to a statically dimensioned array, sizeof
returns the size of the entire array. The sizeof operator cannot return the size of dynamically
allocated arrays or external arrays.
然後再看一下對strlen是如何定義的:
strlen
Get the length of a string.
Routine Required Header:
strlen <string.h>
size_t strlen( const char *string );
Parameter
string:Null-terminated string
Libraries
All versions of the C run-time libraries.
Return Value
Each of these functions returns the number of characters in string, excluding the terminal
NULL. No return value is reserved to indicate an error.
Remarks
Each of these functions returns the number of characters in string, not including the
terminating null character. wcslen is a wide-character version of strlen; the argument of
wcslen is a wide-character string. wcslen and strlen behave identically otherwise.
二、由幾個例子說開去。
第一個例子:
char* ss = "0123456789";
sizeof(ss) 結果 4 ===》ss是指向字符串常量的字符指針
sizeof(*ss) 結果 1 ===》*ss是第一個字符
char ss[] = "0123456789";
sizeof(ss) 結果 11 ===》ss是數組,計算到\\\\\\\\0位置,因此是10+1
sizeof(*ss) 結果 1 ===》*ss是第一個字符
char ss[100] = "0123456789";
sizeof(ss) 結果是100 ===》ss表示在內存中的大小 100×1
strlen(ss) 結果是10 ===》strlen是個函數內部實現是用一個循環計算到\\\\\\\\0為止之前
int ss[100] = "0123456789";
sizeof(ss) 結果 400 ===》ss表示再內存中的大小 100×4
strlen(ss) 錯誤 ===》strlen的參數只能是char* 且必須是以\\\\\\\'\\\\\\\'結尾的
char q[]="abc";
char p[]="a\\\\\\\\n";
sizeof(q),sizeof(p),strlen(q),strlen(p);
結果是 4 3 3 2
第二個例子:
class X
{
int i;
int j;
char k;
};
X x;
cout<<sizeof(X)<<endl; 結果 12 ===》內存補齊
cout<<sizeof(x)<<endl; 結果 12 同上
第三個例子:
char szPath[MAX_PATH]
如果在函數內這樣定義,那麼sizeof(szPath)將會是MAX_PATH,但是將szPath作為虛參聲明時(void fun(char szPath[MAX_PATH])),sizeof(szPath)卻會是4(指針大小)
三、sizeof深入理解。
1.sizeof操作符的結果類型是size_t,它在頭文件中typedef為unsigned int類型。該類型保證能容納實現所建立的最大對象的字節大小。
2.sizeof是算符,strlen是函數。
3.sizeof可以用類型做參數,strlen只能用char*做參數,且必須是以\\\\\\\'\\\\\\\'\\\\\\\\0\\\\\\\'\\\\\\\'結尾的。sizeof還可以用函數做參數,比如:
short f();
printf("%d\\\\\\\\n", sizeof(f()));
輸出的結果是sizeof(short),即2.
4.數組做sizeof的參數不退化,傳遞給strlen就退化為指針了。
5.大部分編譯程序 在編譯的時候就把sizeof計算過了 是類型或是變量的長度這就是sizeof(x)可以用來定義數組維數的原因
char str[20]="0123456789";
int a=strlen(str); //a=10;
int b=sizeof(str); //而b=20;
6.strlen的結果要在運行的時候才能計算出來,時用來計算字符串的長度,不是類型占內存的大小。
7.sizeof後如果是類型必須加括弧,如果是變量名可以不加括弧。這是因為sizeof是個操作符不是個函數。
8.當適用了於一個結構類型時或變量, sizeof 返回實際的大小, 當適用一靜態地空間數組, sizeof 歸還全部數組的尺 寸。 sizeof 操作符不能返回動態地被分派了的數組或外部的數組的尺寸
9.數組作為參數傳給函數時傳的是指針而不是數組,傳遞的是數組的首地址,如:
fun(char [8])
fun(char [])
都等價於 fun(char *) 在C++裡傳遞數組永遠都是傳遞指向數組首元素的指針,編譯器不知道數組的大小如果想在函數內知道數組的大小, 需要這樣做:進入函數後用memcpy拷貝出來,長度由另一個形參傳進去
fun(unsiged char *p1, int len)
{
unsigned char* buf = new unsigned char[len+1]
memcpy(buf, p1, len);
}
有關內容見: C++ PRIMER?
10.計算結構變量的大小就必須討論數據對齊問題。為了CPU存取的速度最快(這同CPU取數操作有關,詳細的介紹可以參考一些計算機原理方面的書),C++在處理數據時經常把結構變量中的成員的大小按照4或8的倍數計算,這就叫數據對齊(data alignment)。這樣做可能會浪費一些內存,但理論上速度快了。當然這樣的設置會在讀寫一些別的應用程序生成的數據文件或交換數據時帶來不便。MS VC++中的對齊設定,有時候sizeof得到的與實際不等。一般在VC++中加上#pragma pack(n)的設定即可。或者如果要按字節存儲,而不進行數據對齊,可以在Options對話框中修改Advanced compiler頁中的Data alignment為按字節對齊。
11.sizeof操作符不能用於函數類型,不完全類型或位字段。不完全類型指具有未知存儲大小的數據類型,如未知存儲大小的數組類型、未知內容的結構或聯合類型、void類型等。如sizeof(max)若此時變量max定義為int max(),sizeof(char_v) 若此時char_v定義為char char_v [MAX]且MAX未知,sizeof(void)都不是正確形式
四、結束語
sizeof使用場合。
1.sizeof操作符的一個主要用途是與存儲分配和I/O系統那樣的例程進行通信。例如:
void *malloc(size_t size),
size_t fread(void * ptr,size_t size,size_t nmemb,FILE * stream)。
2.用它可以看看一類型的對象在內存中所占的單元字節。
void * memset(void * s,int c,sizeof(s))
3.在動態分配一對象時,可以讓系統知道要分配多少內存。
4.便於一些類型的擴充,在windows中就有很多結構內型就有一個專用的字段是用來放該類型的字節大小。
5.由於操作數的字節數在實現時可能出現變化,建議在涉及到操作數字節大小時用sizeof來代替常量計算。
6.如果操作數是函數中的數組形參或函數類型的形參,sizeof給出其指針的大小。
*/