詳談C++中虛基類在派生類中的內存規劃。本站提示廣大學習愛好者:(詳談C++中虛基類在派生類中的內存規劃)文章只能為提供參考,不一定能成為您想要的結果。以下是詳談C++中虛基類在派生類中的內存規劃正文
明天重溫C++的知識,當看到虛基類這點的時分,那時分也沒有太過追查,就是知道虛基類是消弭了類承繼之間的二義性問題而已,可是很是獵奇,它是怎樣消弭的,內存規劃是怎樣分配的呢?於是就深化研討了一下,詳細的原理如下所示:
在C++中,obj是一個類的對象,p是指向obj的指針,該類外面有個數據成員mem,請問obj.mem和p->mem在完成和效率上有什麼不同。
答案是:只要一種狀況下才有嚴重差別,該狀況必需滿足以下3個條件:
(1)、obj 是一個虛擬承繼的派生類的對象
(2)、mem是從虛擬基類派生上去的成員
(3)、p是基類類型的指針
當這種狀況下,p->mem會比obj.mem多了兩個兩頭層。(也就是說在這種狀況下,p->mem比obj.mem要分明的慢)
WHY?
假如獵奇心比擬重的話,請往下看 :
1、虛基類的運用,和為多態而完成的虛函數不同,是為理解決多重承繼的二義性問題。
舉例如下:
class A
{
public:
int a;
};
class B : virtual public A
{
public:
int b;
};
class C :virtual public A
{
public:
int c;
};
class D : public B, public C
{
public:
int d;
};
下面這種菱形的承繼體系中,假如沒有virtual承繼,那麼D中就有兩個A的成員int a;承繼上去,運用的時分,就會有很多二義性。而加了virtual承繼,在D中就只要A的成員int a;的一份拷貝,該拷貝不是來自B,也不是來自C,而是一份獨自的拷貝,那麼,編譯器是怎樣完成的呢??
在答復這個問題之前,先想一下,sizeof(A),sizeof(B),sizeof(C),sizeof(D)是多少?(在32位x86的linux2.6上面,或許在vc2005上面)在linux2.6上面,後果如下:sizeof(A) = 4; sizeof(B) = 12; sizeof(C) = 12; sizeof(D) = 24;sizeof(B)為什麼是12呢,那是由於多了一個指針(這一點和虛函數的完成一樣),那個指針是干嘛的呢?
那麼sizeof(D)為什麼是24呢?那是由於除了承繼B中的b,C中的c,A中的a,和D自己的成員d之外,還承繼了B,C多出來的2個指針(B和C辨別有一個)。再強調一遍,D中的int a不是來自B也不是來自C,而是另外的一份從A直接靠過去的成員。
假如聲明了D的對象d: D d;
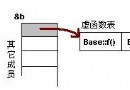
那麼d的內存規劃如下:
vb_ptr: 承繼自B的指針
int b: 承繼自B私有成員
vc_ptr:承繼自C的指針
int c: 承繼自C的共有成員
int d: D自己的私有成員
int a: 承繼自A的私有成員
那麼以下的用法會發作什麼事呢?
D dD; B *pb = &dD; pb->a;
下面說過,dD中的int a不是承繼自B的,也不是承繼自C的,那麼這個B中的pb->a又會怎樣知道指向的是dD內存中的第六項呢?
那就是指針vb_ptr的妙用了。原理如下:(其實g++3.4.3的完成愈加復雜,我不知道是出於什麼思索,而我這裡只說原理,所以把進程和內容復雜化了)
首先,vb_ptr指向一個整數的地址,外面放的整數是那個int a的間隔dD開端處的位移(在這裡vb_ptr指向的地址外面放的是20,以字節為單位)。編譯器是這樣做的:
首先,找到vb_ptr(這個不必找,由於在g++中,vb_ptr就是B*中的第一項,呵呵),然後獲得vb_ptr指向的地址的內容(這個例子是20),最後把這個內容與指針pb相加,就失掉pb->a的地址了。
所以說這種時分,用指針轉換多了兩個兩頭層才干找到基類的成員,而且是運轉時期。
由此也可以推知dD中的vb_ptr和vc_ptr的內容都是一樣的,都是指向同一個地址,該地址就放20(在本例中)
如下的語句呢:
A *pa = &dD; pa->a = 4;
這個語句不必轉換了,由於編譯器在編譯時期就知道他把A中的成員插在dD中的那個中央了(在本例中是末尾),所以這個語句中的運轉效率和dD.a是一樣的(至多也是差不多的)
這就是虛基類完成的根本原理。
留意的是:那些指針的地位和基類成員在派生類成員中的內存規劃是不確定的,也就是說規范外面沒有規則inta必需要放在最後,只不過g++編譯器的完成而已。c++規范大約只規則了這套機制的原理,至於詳細的完成,比方各成員的排放順序和優化,由各個編譯器廠商自己定~
非虛擬承繼:
在派生類對象裡,依照承繼聲明順序順次散布基類對象,最後是派生類數據成員。
若基類聲明了虛函數,則基類對象頭部有一個虛函數表指針,然後是基類數據成員。
在基類虛函數表中,順次是基類的虛函數,若某個函數被派生類override,則交換為派生類的函數。
派生類獨有的虛函數被加在第一個基類的虛函數表前面。
虛擬承繼:
在派生類對象裡,依照承繼聲明順序順次散布非虛基類對象,然後是派生類數據成員,最後是虛基類對象。
若基類聲明了虛函數,則基類對象頭部有一個虛函數表指針,然後是基類數據成員。
在基類虛函數表中,順次是基類的虛函數,若某個函數被派生類override,則交換為派生類的函數。
若直接從虛基類派生的類沒有非虛父類,且聲明了新的虛函數,則該派生類有自己的虛函數表,在該派生類頭部;否則派生類獨有的虛函數被加在第一個非虛基類的虛函數表前面。
直接從虛基類派生的類外部還有一個虛基類表指針(一個隱藏的“虛基類表指針”成員,指向一個虛基類表),在數據成員之前,非虛基類對象之後(若有的話)。
虛基類表中第一個值是該虛基類表到派生類起始地址的偏移;之後的值順次是該派生類的虛基類到該表地位的地址偏移(虛基類對象的地址與派生類的“虛基類表指針”之間的偏移量)。
關於虛函數表指針和虛基類表指針:
當單承繼且非虛承繼時:每個含有虛函數的表只要一個虛函數表,所以只需求一個虛表指針即可;
當多承繼且非虛承繼時:一個子類有幾個父類則會有幾個虛函數表,所以就有和父類個數相反的虛表指針來標識;
總之,事先非虛承繼時,不需求額定添加虛函數表指針。
當虛承繼時:無論是單虛承繼還是多虛承繼,需求有一個虛基類表來記載虛承繼關系,所以此時子類需求多一個虛基類表指針;而且只需求一個即可。
當虛承繼時能夠呈現一個類中持有多個虛函數表的狀況:無論是單虛承繼還是多虛承繼,
假如子類沒有結構函數和析構函數,且子類中的虛函數都是在父類中呈現的虛函數,這個時分不需求添加任何虛表指針;只需求像多承繼那個持有父類個數的虛表指針來標識即可;
假如子類中含有結構函數或許析構函數或二者都有,則在子類中只需每呈現一個父類中的虛函數則需求添加一個虛函數表指針來標識此類的虛函數表;
無論能否含有結構函數或許虛擬函數,只需承繼都是虛承繼且呈現了父類中沒有呈現的虛函數,則在子類中需求再添加一個徐函數表指針;假如其中有一個是非虛承繼,則依照最省空間的准繩,不需求添加虛函數表指針,由於這個時分可以和非虛基類共享一個虛函數表指針。
以上就是為大家帶來的詳談C++中虛基類在派生類中的內存規劃全部內容了,希望大家多多支持~