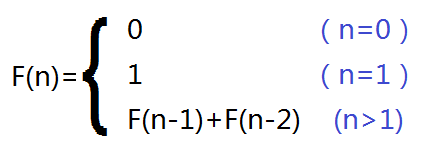給出兩個升序排列的n維整數數組,求這2n個數中的第n大數。(算法導論:Exercise 9.3-8)
筆試的時候有一個想法,但是寫的很草率,回來仔細想了下,把它寫出來。我想這個應該是別人已經做過的東西,但我也不知道怎麼查,第一次自己寫查找算法,在我這就把它叫做“順序存儲雙有序列的二分折疊查找算法”吧。其實這個算法好象沒什麼實際作用,有序列的查找嘛,計算量都不大。
算法描述太累贅了,就寫個基本思想吧:把每個數組尾部的指針向前移動n/2個數,然後比較這兩個數的大小,如果a中的大,就把這個數與b從尾部開始比較直到某個數小於它,這樣,第n個數肯定不在兩個指針後面,把兩個指針後面的數字個數加起來,作為count。n-count就是執行下次類似查找的n。主要工作量節省在每次跨n/2上。至於最後如何選擇第n個數,需要分析一下具體情況。
int search4n(int *a, int *b, int n)
{
int *p,*q,*p1,*q1,range;
p = a+n;
q = b+n;
if( a[0]>b[n-1] ) return a[0];
if( b[0]>a[n-1] ) return b[0];
while(n>1)
{
range = ( n+1 ) / 2;
p1 = p-range;
q1 = q-range;
if( *p1>*q1 ){
n -= range;
p = p1;
q--;
while( *q>*p1 ){
q--;
n--;
}
}
else{
n -= range;
q = q1;
p--;
while(*p>*q1){
p--;
n--;
}
}
}
if( n==0 ) return *p > *q ? *p : *q;
else if( n==1 ) return *(--p) > *(--q) ? *p : *q;
else return 0;
}
其實這個算法可以推而廣之到任意兩個有序列的第n大數查找,見下面。但是為了控制指針越界需要浪費一些判斷語句,其實有很多判斷語句只有在足夠接近邊界時候才起作用。這算法也可以推廣到鏈表,但似乎效率要低些。
int search4n(int *a, int *b, int an, int bn, int n)
{
int *p, *q, *p1, *q1, range;
p = a+an;
q = b+bn;
if( a[0]>b[bn-1] ) return n <= an ? a[an-n] : b[an+bn-n];
if( b[0]>a[an-1] ) return n <= bn ? b[bn-n] : a[an+bn-n];
while( n>1 ){
range = ( n+1 ) / 2;
p1 = p-range>a ? ( q==b ? p-n : p-range) : a;
if(q1==b && *q1>*(p-1)) return *(p-n);
q1 = q-range>b ? ( p==a ? q-n : q-range) : b;
if(p1==a && *p1>*(q-1)) return *(q-n);
if( *p1>*q1 ){
n -= (p-p1);
p = p1;
q--;
while( *q>*p && q>b ){
n--;
q--;
}
*q>*p ? q : q++;
}
else{
n -= (q-q1);
q = q1;
p--;
while( *p>*q && p>a ){
n--;
p--;
}
*p>*q ? p : p++;
}
}
if( n==0 ) return *p<*q ? *p : *q;
else if( n==1 ) return (p1==a || q1==b) ? ( p1==a ? *(--q) : *(--p) ) : ( *(--p)>*(--q) ? *p : *q );
else return 0;
}
算法復雜度:
時間復雜度,顯然最優狀況下,比較只需要常數次(如果比較次數不包括各種邊界條件的比較);最壞狀況下,比較主要在中間那個while雙循環,假設n對應的比較次數為f(n),則f(n)=1+k+f(n-[(n+1)/2]-k),其中1=<k<[(n+1)/2];f(1)=1;f(2)=2。則f(n)的最大值就是最差情況下的比較次數,我估計不出來,所以無法說它的平均算法復雜度了,但由f(n)的下降速度可以看出比較次數是介於log(n)和n之間的,究竟是多少數量級不太清楚,回頭再想想怎麼估計平均復雜度,應該是需要考慮k的分布。
空間復雜度,需要4個指針空間和1個整型變量空間,常數級。
我估計這個算法應該不是最優的,尤其對題目來說這種算法肯定不是最優的,因為求中位數的話可以更簡單,但它可以推廣到任意兩有序列的查找,也算是一種途徑。不過我覺得這個算法裡可能還有漏洞,只是我沒檢查出來,也該有優化的可能,以後再慢慢想吧。