一、標准IO的效率
對比以下四個程序的用戶CPU、系統CPU與時鐘時間對比
程序1:系統IO
程序2:標准IO getc版本
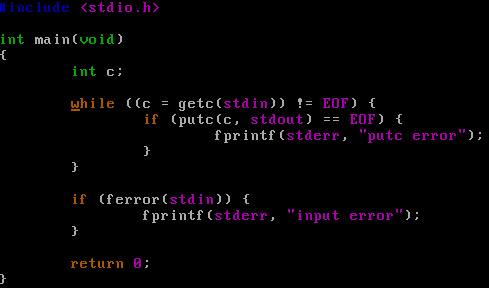
程序3:標准IO fgets版本
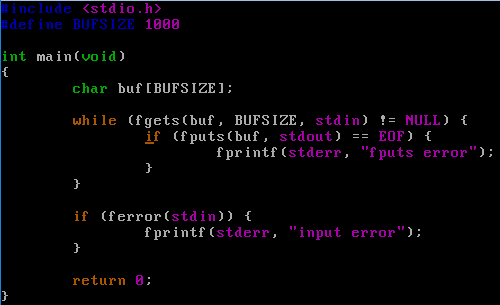
結果:
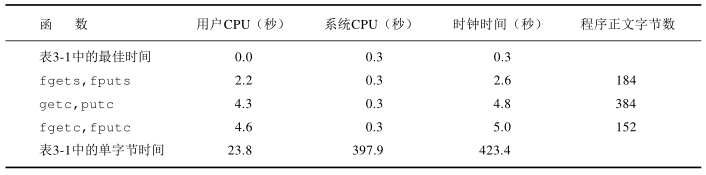
【注:該表截取自APUE,上表中"表3-1中的最佳時間即《程序1》","表3-1中的單字節時間指的是《程序1》中BUFSIZE為1時運行時間結果",fgetc/fputc版本程序這裡沒放出】
對於三個標准IO版本的每一個其用戶CPU時間都大於最佳read版本,因為每次讀一個字符版本中有一個要執行150萬次的循環,而在每次讀一行的版本中有一個要執行30000次的循環。而在read版本中,其循環只需執行180次。因為系統CPU時間都相同,所以用戶CPU時間的差別造成了時鐘時間的差別。系統CPU時間相同的原因是所有這些程序對內核提出的讀寫請求數相同。
上表中最後一列是每個main函數的文本空間字節數(由c編譯產生的機器指令)。從中可見getc/putc版本在文本空間做了大量宏替換,所以它所需的指令數超過了調用fgetc/fputc函數所用的指令數。從用戶CPU時間看getc/putc版本與fgetc/fputc版本在此次測試中並沒有多大的差別。
使用每次一行IO的版本其速度大約是每次一個字符版本的兩倍(包括用戶CPU時間和時鐘時間)。如果fgets/fputs函數用getc/putc實現則可以預計fgets版本的時間會與getc版本相接近。可以預料每次一行的版本會更慢一些,因為除了現存的60000次函數調用外還需增加3百萬次宏調用。而在本測試中每次一行參數是用memccoy實現的,為了提高效率memccpy函數用匯編寫。
【重點】fgetc版本與程序1 BUFSIZE=1的版本要快得多,兩者都用了約3百萬次函數調用,造成速度差距這麼大的原因在於《程序1》執行了3百萬次函數調用這也執行了3百萬次系統調用,而fgetc版本雖然執行了3百萬次函數調用但是只引起了360次系統調用。系統調用與普通的函數調用相比是很耗時間的。
二、二進制IO
為了可以讀取二進制文件我們可以通過getc/putc實現的,但是這樣必須循環整個結構。而fputs/fgets在遇到null字符時就結束,在結構中可能含有null字節,所以不能使用fgets/fputs。綜上所以提供了下面兩個函數以執行二進制IO操作
#include <stdio.h> size_t fread(void *ptr, size_t size, size_t nobj, FILE *fp); size_t fwrite(const char *ptr, size_t size, size_t nobj, FILE *fp); 返回值:讀或寫的對象數
常見的用法:
float data[10];
if (fwrite(&data[2], sizeof(float), 4, fp) != 4) {
fprintf(stderr, "fwrite error");
}
其中,指定size為每個數組元素的長度,nobj為欲寫的元素數。
讀或寫一個結構。例:
struct {
short count;
long total;
char name[NAMESIZE];
} item;
if (fwrite(&item, sizeof(item), 1, fp) != 1) {
fprintf(stderr, "fwrite error");
}
對於讀,如果出錯或到達文件尾,則fread返回的數字可能少於nobj。這時應該調用ferro+feof判斷是哪種情況。對於寫如果返回之小於nobj則出錯。
使用二進制IO的限制是只能用於讀已寫在同一系統上的數據。但是現在很多異構系統通過網絡連接在一起,通常會在一個系統上讀取另外一個系統上的數據,這樣的話這兩個函數就不能工作了,原因:
三、 定位流
有兩種方式可以定位標准IO流。
需要移植到非UNIX系統上運行的程序應使用fgetpos和fsetpos。
#include <stdio.h> long ftell(FILE *fp); 返回值:成功則為當前位置相對於文件首的偏移字節數,出錯為-1L int fseek(FILE *fp, long offset, int whence); 返回值:成功為0,出錯為非0 void rewind(FILE *fp);
對於一個二進制文件,其位置指示是從文件起始位置開始度量並以字節為單位的。ftell用於二進制文件時,其返回值就是這種字節位置。為了用fseek定位一個二進制文件,必須指定一個字節offset,以及解釋這種位移量的方式。whence與lseek函數相同:SEEK_SET表示從文件的起始位置開始,SEEK_CUR表示從當前位置,SEEK_END表示從文件的尾端。
對於文本文件,它們的文件當前位置可能不以簡單的字節位移量來度量。在非UNIX系統中可能以不同的格式存放文本文件,為了定位一個文本文件,whence一定要是SEEK_SET,而且offset只能有兩種值:0(表示反繞文件到其起始位置),或者是對該文件的ftell所返回的值。使用rewind函數也可以將一個流設置到文件的起始位置。
#include <stdio.h> int fgetpos(FILE *fp, fpos_t *pos); int fsetpos(FILE *fp, const fpos_t *pos); 返回值:成功為0,出錯非0
fgetpos將當前位置存入pos指向的對象中。在以後調用fsetpos時,可以使用此值將流重定向至該位置。
四、 格式化IO
1. 格式化輸出
#incldue <stdio.h> in printf(const char *format, ...);
返回值:成功則為輸出字符數,出錯為負值
int fprintf(FILE *fp, const char *format, ...);
返回值:成功則為輸出字符數,出錯為負值
int sprintf(char *buf, const char *format, ...);
返回值:存入數組的字符數
sprintf將格式化的字符送入數組buf中。sprintf在該數組的尾端自動加一個null字節,但該字節不包含在返回值中。sprintf有可能會使buf指向的緩存溢出。
printf族的三種變體類似於上面的三種,只不過是可變參數變成了arg
#include<stdarg.h> #include<stdio.h> int vprintf(const char * f o r m a t, va_list arg) ; int vfprintf(FILE *f p, const char * f o r m a t, va_list arg) ; 兩個函數返回:若成功則為輸出字符數,若輸出出錯則為負值 int vsprintf(char *b u f, const char * f o r m a t, va_list arg) ; 返回:存入數組的字符數
2. 格式化輸入
三個scanf函數:
#include <stdio.h> int scanf(const char *format, ...); int fscanf(FILE *fp, const char *format, ...); int sscanf(const char *buf, const char *format, ...);
五、實現細節
在UNIX中標准IO最終都要調用系統IO。每個IO流都有一個與其關聯的文件描述符,可以用fileno獲取該流對應的文件描述符。
#include <stdio.h> int fileno(FILE *fp); 返回值:與流相關聯的文件描述符
為了了解所使用的系統中標准IO的實現最好從stdio.h頭文件開始。
【注:原書中下面有一個案例這裡沒有放出】
六、臨時文件
標准IO庫提供了兩個函數以幫助創建臨時文件
#include <stdio.h> char *tmpnam(char *ptr); 返回值:指向一唯一路徑名的指針 FILE *tmpfile(void); 返回值:成功則為文件指針,出錯為NULL
tmpnam產生一個與現在文件名(改文件名不是指ptr!該函數用來產生一個唯一文件)不同的一個有效路徑名字符串。每次調用它時,它都產生一個不同的路徑名,最多調用次數是TMP_MAX。TMP_MAX定義在<stdio.h>中
若ptr是NULL,則所產生的路徑名存放在一個靜態區中,指向該靜態區的指針作為函數值返回。下一次再調用tmpnam時會重寫該靜態區。(這意味著如果我們調用此函數多次,而且想保存路徑名,那我們應該保存該路徑名的副本而不是指針的副本) 如果ptr不是NULL,則認為它指向長度至少是L_tmpnam個字符的數組。(常數L_tmpnam定義在<stdio.h>中)所產生的路徑名存放在該數組中,ptr也作為函數值返回。
tmpfile創建一個臨時二進制文件。在關閉該文件或程序結束時會自動刪除這種文件。
tempnam是tmpnam的一個變體,它允許調用者為所產生的路徑名指定目錄和前綴。
#include <stdio.h> char *tempnam(const char *directory, const char *prefix); 返回值:指向一唯一路徑名的指針
對於目錄有四種不同的選擇:(優先級從高至低)
(1) 如果定義了環境變量TMPDIR,則用其作為目錄。
(2) 如果參數directory非NULL,則用其作為目錄。
(3) 將<stdio.h>中的字符串P_tmpdir用作為目錄。
(4) 將本地目錄,通常是/tmp用作為目錄。
如果prefix非NULL,則它通常是最多包含5個字符的字符串,用其作為文件名的前幾個字符。
該函數調用malloc函數分配動態存儲區,用其存放所構造的路徑名。當不再使用該路徑名時就可釋放次存儲區。