最近在看knn算法,順便敲敲代碼。
knn屬於數據挖掘的分類算法。基本思想是在距離空間裡,如果一個樣本的最接近的k個鄰居裡,絕大多數屬於某個類別,則該樣本也屬於這個類別。俗話叫,“隨大流”。
簡單來說,KNN可以看成:有那麼一堆你已經知道分類的數據,然後當一個新的數據進入的時候,就開始跟訓練裡的每個點求距離,然後挑出離這個數據最近的K個點,看看這K個點屬於什麼類型,然後用少數服從多數的原則,給新數據歸類。
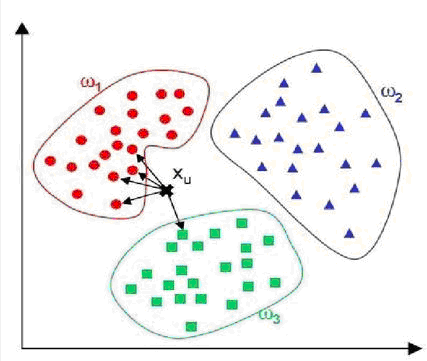
該算法的示意圖,簡單明了:
下面的算法步驟取自於百度文庫(文庫是一個好東西),代碼是參照這個思路實現的:

code:
1 #include<stdio.h>
2 #include<math.h>
3 #include<stdlib.h>
4
5 #define K 3 //近鄰數k
6 typedef float type;
7
8 //動態創建二維數組
9 type **createarray(int n,int m)
10 {
11 int i;
12 type **array;
13 array=(type **)malloc(n*sizeof(type *));
14 array[0]=(type *)malloc(n*m*sizeof(type));
15 for(i=1;i<n;i++) array[i]=array[i-1]+m;
16 return array;
17 }
18 //讀取數據,要求首行格式為 N=數據量,D=維數
19 void loaddata(int *n,int *d,type ***array,type ***karray)
20 {
21 int i,j;
22 FILE *fp;
23 if((fp=fopen("data.txt","r"))==NULL) fprintf(stderr,"can not open data.txt!\n");
24 if(fscanf(fp,"N=%d,D=%d",n,d)!=2) fprintf(stderr,"reading error!\n");
25 *array=createarray(*n,*d);
26 *karray=createarray(2,K);
27
28 for(i=0;i<*n;i++)
29 for(j=0;j<*d;j++)
30 fscanf(fp,"%f",&(*array)[i][j]); //讀取數據
31
32 for(i=0;i<2;i++)
33 for(j=0;j<K;j++)
34 (*karray)[i][j]=9999.0; //默認的最大值
35 if(fclose(fp)) fprintf(stderr,"can not close data.txt");
36 }
37 //計算歐氏距離
38 type computedistance(int n,type *avector,type *bvector)
39 {
40 int i;
41 type dist=0.0;
42 for(i=0;i<n;i++)
43 dist+=pow(avector[i]-bvector[i],2);
44 return sqrt(dist);
45 }
46 //冒泡排序
47 void bublesort(int n,type **a,int choice)
48 {
49 int i,j;
50 type k;
51 for(j=0;j<n;j++)
52 for(i=0;i<n-j-1;i++){
53 if(0==choice){
54 if(a[0][i]>a[0][i+1]){
55 k=a[0][i];
56 a[0][i]=a[0][i+1];
57 a[0][i+1]=k;
58 k=a[1][i];
59 a[1][i]=a[1][i+1];
60 a[1][i+1]=k;
61 }
62 }
63 else if(1==choice){
64 if(a[1][i]>a[1][i+1]){
65 k=a[0][i];
66 a[0][i]=a[0][i+1];
67 a[0][i+1]=k;
68 k=a[1][i];
69 a[1][i]=a[1][i+1];
70 a[1][i+1]=k;
71 }
72 }
73 }
74 }
75 //統計有序表中的元素個數
76 type orderedlist(int n,type *list)
77 {
78 int i,count=1,maxcount=1;
79 type value;
80 for(i=0;i<(n-1);i++) {
81 if(list[i]!=list[i+1]) {
82 //printf("count of %d is value %d\n",list[i],count);
83 if(count>maxcount){
84 maxcount=count;
85 value=list[i];
86 count=1;
87 }
88 }
89 else
90 count++;
91 }
92 if(count>maxcount){
93 maxcount=count;
94 value=list[n-1];
95 }
96 //printf("value %f has a Maxcount:%d\n",value,maxcount);
97 return value;
98 }
99
100 int main()
101 {
102 int i,j,k;
103 int D,N; //維度,數據量,標簽
104 type **array=NULL; //數據數組
105 type **karray=NULL; // K近鄰點的距離及其標簽
106 type *testdata; //測試數據
107 type dist,maxdist;
108
109 loaddata(&N,&D,&array,&karray);
110 testdata=(type *)malloc((D-1)*sizeof(type));
111 printf("input test data containing %d numbers:\n",D-1);
112 for(i=0;i<(D-1);i++) scanf("%f",&testdata[i]);
113
114 while(1){
115 for(i=0;i<K;i++){
116 if(K>N) exit(-1);
117 karray[0][i]=computedistance(D-1,testdata,array[i]);
118 karray[1][i]=array[i][D-1];
119 //printf("first karray:%6.2f %6.0f\n",karray[0][i],karray[1][i]);
120 }
121
122 bublesort(K,karray,0);
123 //for(i=0;i<K;i++) printf("after bublesort in first karray:%6.2f %6.0f\n",karray[0][i],karray[1][i]);
124 maxdist=karray[0][K-1]; //初始化k近鄰數組的距離最大值
125
126 for(i=K;i<N;i++){
127 dist=computedistance(D-1,testdata,array[i]);
128 if(dist<maxdist)
129 for(j=0;j<K;j++){
130 if(dist<karray[0][j]){
131 for(k=K-1;k>j;k--){ //j後元素復制到後一位,為插入做准備
132 karray[0][k]=karray[0][k-1];
133 karray[1][k]=karray[1][k-1];
134 }
135 karray[0][j]=dist; //插入到j位置
136 karray[1][j]=array[i][D-1];
137 //printf("i:%d karray:%6.2f %6.0f\n",i,karray[0][j],karray[1][j]);
138 break; //不比較karray後續元素
139 }
140 }
141 maxdist=karray[0][K-1];
142 //printf("i:%d maxdist:%6.2f\n",i,maxdist);
143 }
144 //for(i=0;i<K;i++) printf("karray:%6.2f %6.0f\n",karray[0][i],karray[1][i]);
145 bublesort(K,karray,1);
146 //for(i=0;i<K;i++) printf("after bublesort in karray:%6.2f %6.0f\n",karray[0][i],karray[1][i]);
147 printf("\nThe data has a tag: %.0f\n\n",orderedlist(K,karray[1]));
148
149 printf("input test data containing %d numbers:\n",D-1);
150 for(i=0;i<(D-1);i++) scanf("%f",&testdata[i]);
151 }
152 return 0;
153 }
實驗:
訓練數據data.txt:
N=6,D=9
1.0 1.1 1.2 2.1 0.3 2.3 1.4 0.5 1
1.7 1.2 1.4 2.0 0.2 2.5 1.2 0.8 1
1.2 1.8 1.6 2.5 0.1 2.2 1.8 0.2 1
1.9 2.1 6.2 1.1 0.9 3.3 2.4 5.5 0
1.0 0.8 1.6 2.1 0.2 2.3 1.6 0.5 1
1.6 2.1 5.2 1.1 0.8 3.6 2.4 4.5 0
預測數據:
1.0 1.1 1.2 2.1 0.3 2.3 1.4 0.5
1.7 1.2 1.4 2.0 0.2 2.5 1.2 0.8
1.2 1.8 1.6 2.5 0.1 2.2 1.8 0.2
1.9 2.1 6.2 1.1 0.9 3.3 2.4 5.5
1.0 0.8 1.6 2.1 0.2 2.3 1.6 0.5
1.6 2.1 5.2 1.1 0.8 3.6 2.4 4.5
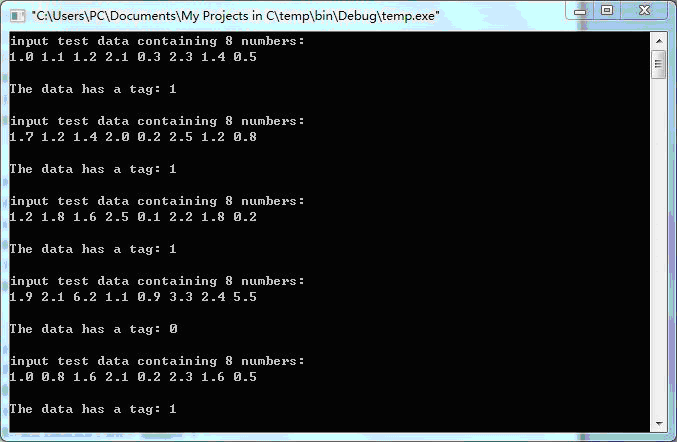
程序測試的結果:
1.0 1.1 1.2 2.1 0.3 2.3 1.4 0.5 類別為: 1
1.7 1.2 1.4 2.0 0.2 2.5 1.2 0.8 類別為: 1
1.2 1.8 1.6 2.5 0.1 2.2 1.8 0.2 類別為: 1
1.9 2.1 6.2 1.1 0.9 3.3 2.4 5.5 類別為: 0
1.0 0.8 1.6 2.1 0.2 2.3 1.6 0.5 類別為: 1
1.6 2.1 5.2 1.1 0.8 3.6 2.4 4.5 類別為: 0
實驗截圖: