總結一下對應用程序出現segment fault時的基礎和調試方法,知識來自debug hacks一書
環境,x86 32位linux
一.基礎
1.熟悉參數的傳遞方式。
在進入被調用函數之前,程序會按照參數,返回地址,fp指針(幀指針),被調用函數的局部變量,的次序壓棧。
源碼:
#include <stdio.h>
int fun(int a,char c)
{
printf("%d\n%c\n",a,c);
return a;
}
int main()
{
fun(1,'a');
return 0;
}
使用gdb調試該程序:

 在函數名前加上*號,程序遇到斷點時,會卡在函數匯編語言層次的開頭。如果不加*,會停在函數的第一句話。
函數在跳轉之前會把需要傳遞的變量和返回地址壓入棧,而剩余的變量由被調用函數壓棧。所以此時,sp指針指向的是返回地址,另一個我們知道棧是向下增長的,所以sp+4就是壓入的第2個參數(a),sp+8是壓入的第1個參數(c),如下圖。
在函數名前加上*號,程序遇到斷點時,會卡在函數匯編語言層次的開頭。如果不加*,會停在函數的第一句話。
函數在跳轉之前會把需要傳遞的變量和返回地址壓入棧,而剩余的變量由被調用函數壓棧。所以此時,sp指針指向的是返回地址,另一個我們知道棧是向下增長的,所以sp+4就是壓入的第2個參數(a),sp+8是壓入的第1個參數(c),如下圖。
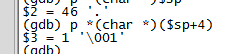
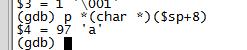 2.core文件的生成
一般linux系統默認是不生成core文件的,可以通過ulimit -c查看。如果顯示0,則調用ulimit -c unlimited 設置為沒有上限,當然也可以設置一個具體的值,單位為blocks。
注意:必須確保有權限在該目錄下生成core文件,因為我們很多工作的時候是將本地文件掛載到linux服務器上或者虛擬機上,如果不是有權限的用戶登錄的話,是不會在該目錄下生成core文件的,或者生成的core文件大小為0。
3.gdb的常用命令
可以查看我的上一篇總結。
二.調試實踐
1.棧溢出
源碼:
2.core文件的生成
一般linux系統默認是不生成core文件的,可以通過ulimit -c查看。如果顯示0,則調用ulimit -c unlimited 設置為沒有上限,當然也可以設置一個具體的值,單位為blocks。
注意:必須確保有權限在該目錄下生成core文件,因為我們很多工作的時候是將本地文件掛載到linux服務器上或者虛擬機上,如果不是有權限的用戶登錄的話,是不會在該目錄下生成core文件的,或者生成的core文件大小為0。
3.gdb的常用命令
可以查看我的上一篇總結。
二.調試實踐
1.棧溢出
源碼:
#include <stdio.h>
int fun()
{
int a = 10;
fun();
printf("%d\n",a);
return 1;
}
int main(int argc,char **argv)
{
fun();
return 0;
}
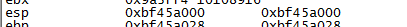 可以看到sp=0xbf45a000;
再查看各個段的大小,使用i files命令,雖然看不出哪個段是stack,ps:不知道為何無法上傳圖片。那我就打字了。
如下:
可以看到sp=0xbf45a000;
再查看各個段的大小,使用i files命令,雖然看不出哪個段是stack,ps:不知道為何無法上傳圖片。那我就打字了。
如下:
Local core dump file:
`/root/core', file type elf32-i386.
0x0084e000 - 0x0084e000 is load1
0x009a1000 - 0x009a1000 is load2
0x009a2000 - 0x009a4000 is load3
0x009a4000 - 0x009a5000 is load4
0x009a5000 - 0x009a8000 is load5
0x00d68000 - 0x00d69000 is load6
0x00d87000 - 0x00d87000 is load7
0x00da2000 - 0x00da3000 is load8
0x00da3000 - 0x00da4000 is load9
0x08048000 - 0x08048000 is load10
0x08049000 - 0x0804a000 is load11
0x0804a000 - 0x0804b000 is load12
0xb775e000 - 0xb775f000 is load13
0xb776d000 - 0xb776f000 is load14
0xbf45a000 - 0xbfe5a000 is load15
可以看出0xbf45a000 屬於段15,明顯已經位於了這個段的末尾,因為sp自減時並不檢查sp是否超過了范圍,當訪問時才會知道這個地址是否合法,所以可以確定是棧溢出。
很多大型的程序,當程序拋出段錯誤的信號時,會有處理程序接收這個信號,但是這個時候棧上已經沒有空間了,是不可能讓這個處理函數正常結束的,所以需要提前為這個函數申請好棧空間,確保能把當時的情形保留下來,可以使用sigaltstack函數在堆上申請備用棧。具體的用法請man一下
2.返回地址被修改
返回地址被修改的情況很多,根據之前的棧空間壓棧順序,如果被調用函數的局部數組越界就可以將返回地址覆蓋,導致段錯誤的發生,這是一種。重點是我們要怎麼知道發生了返回地址被修改,而且此時的局部變量也可能是不正確的,很難調試。一般來講如果發生返回地址被修改,bt中的信息會是這樣的。
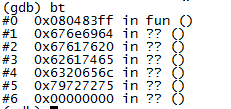
我們知道正常情況下,應該是顯示函數名稱而不是問號,(如果修改之後的地址還是指向某個函數的話,那就只能一步步查看下去,是否存在這麼一個調用順序)。此時是可以確定返回地址被修改了的。
具體將一個如果是數組越界導致的返回地址被修改的情形。
源碼:
#include <stdio.h>
#include <string.h>
char names[] = "book cat dog building vagetable curry";
void fun()
{
char buf[5];
strcpy(buf,names);
}
int main(int argc,char **argv)
{
fun();
return 0;
}
調試過程:首先查看當前運行在哪句話上。
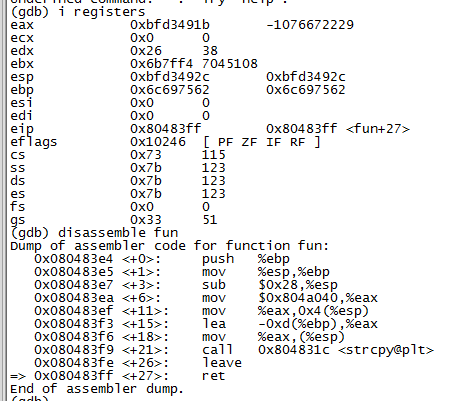
可以看出當前運行到了ret這句話,也就是返回,那麼看下sp中的值是多少。
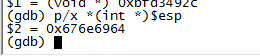
這步有些多余,就是堆棧信息中的下一幀地址。
因堆棧信息目前懷疑的是返回地址被修改,所以查看esp中的內容,先用字符串的形式查看裡面的內容

比較明顯可以看出現在堆棧中的信息就是book cat dog building vagetable curry 顯然是一個字符串,搜索這個字符串被引用的地方,可以發現就在源代碼的第8行,復制字符串時超出了數組的長度。
3.利用監視點檢測非法內存訪問
這個我在linux系統中無法復現出,因為越界之後的地址值是非法的,模擬出這個情況比較困難。所以這邊就語言描述下。
源程序:
int data[2]= {1,2};
int calc(void)
{
return -7;
}
int main()
{
int index = calc();
data[index] = 0x0a;
data[index+1] = 0x08;
printf("ssssss\n");
return 0;
}
錯誤發生在printf那句話中。通過查看堆棧找到main函數中的返回地址,而在這個返回地址之前的語句可能就導致了這個段錯誤,然後查看到之前的語句中有一句call跟蹤該語句,最終會跳轉到一個指針中的地址,而實際上這個指針中的地址就是0x08,也就是被程序中的語句所修改了,那麼重點就在怎麼確定是這句話導致的錯誤。
既然知道了這個指針所指向的地址,那麼就可以在這個地址值出設置監視點,當這個地址處的值被修改時gdb就會停住,運行時會發現就是printf的前一句話,也就是找到了原因所在。
4.雙重釋放指針導致的bug
這種錯誤我覺得可以設置監視點或者斷點的方式,利用gdb的腳本,打印出free時的堆棧信息,然後查看哪個地址有被多重釋放。
另一種方法是利用env MALLOC_CHECK_=1 ./a.out 來運行程序,但有的情況下不指定環境變量,在雙重釋放指針時也會打印出堆棧信息,反而加了環境變量沒有打印出堆棧信息。但個人覺得這只是說明原因是雙重釋放,還是堅持前一種方法,找到釋放的兩個位置,只保留一個釋放點。
5.死鎖
當造成死鎖時,先使用ps命令查看下線程狀態,如果狀態是S的話,就有可能說明是死鎖了。
這個時候再使用gdb attch上去,查看各個線程的堆棧,看卡在哪一個線程中。
然後再利用gdb設置斷點和腳本,打印出同一把鎖被操作的過程。下面看個例子
源碼:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
int cnt = 0;
void cnt_reset(void)
{
pthread_mutex_lock(&mutex);
cnt = 0;
pthread_mutex_unlock(&mutex);
}
void *th(void *p)
{
while(1){
pthread_mutex_lock(&mutex);
if(cnt > 2)
cnt_reset();
else
cnt++;
pthread_mutex_unlock(&mutex);
printf("%d\n",cnt);
sleep(1);
}
}
int main()
{
pthread_t id;
pthread_create(&id,0,th,0);
pthread_join(id,0);
return 0;
}
運行結果:
[root@ubuntu: deadlock]./a.out
1
2
3
發現程序不跑了,根據程序接下來應該打印出0。
[root@ubuntu: deadlock]ps -x | grep a.out
Warning: bad ps syntax, perhaps a bogus '-'? See http://procps.sf.net/faq.html
26418 pts/9 Sl+ 0:00 ./a.out
可以看出程序現在處於睡眠狀態,那麼使用gdb attch上去,查看是哪一個線程在睡眠或者說導致了死鎖。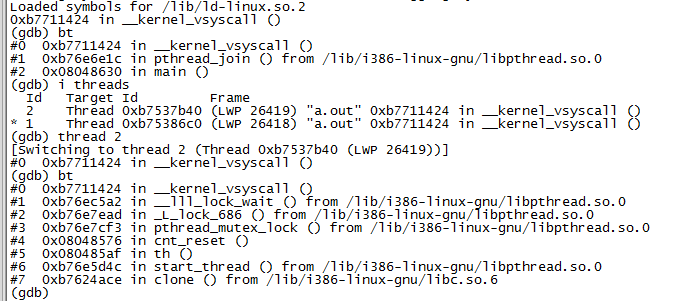
可以看出主線程是處在睡眠中,在等待子線程的結束,而子線程睡眠在了等待鎖的釋放上,那麼現在問題就在於為什麼鎖是在哪一步或者哪個線程先拿到了,而導致當前線程拿不到鎖。
使用gdb重新調試程序,並且在加鎖和釋放鎖的位置設置斷點,打印出堆棧,可以發現前面一直都是加鎖解鎖對應的,而在最後一對打印中兩個操作都是加鎖
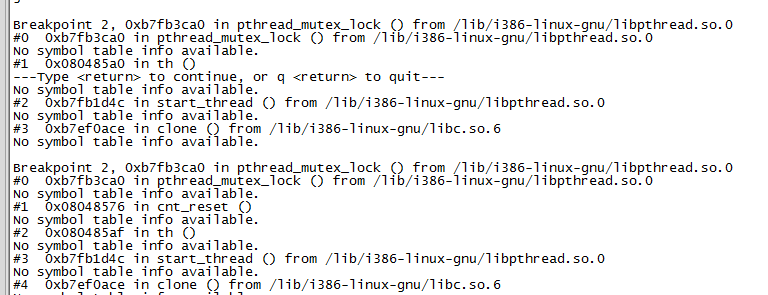
根據這個堆棧信息可以知道th函數先加了一次鎖,然後th函數本身調用了cnt_reset函數,該函數再一次加鎖導致了死鎖。
所以現在就找到原因了。
這是一個較為簡潔的例子,我在工作中遇到過一次較為麻煩的問題,如下:多線程之間對於一個數據結構的訪問,需要首先拿到保護該結構的鎖,問題出在了當某一個線程拿到鎖之後還沒有釋放鎖,該線程就被殺死了,而此時其他線程就再也無法獲取到該鎖,導致所有線程堵死。同樣通過上述方式可以找到原因。
6.死循環
這個情況我自己模仿書上的例子,創建了一個類似的例子
源碼:
#include <stdio.h>
int fun(char *p,int len)
{
while(len > 0){
int version = *(int *)p;
int msgtype = *(int *)(p+sizeof(int));
int length = *(int *)(p+sizeof(int)+sizeof(int));
/*do something*/
len = len - length;
p = p + length;
}
}
int main()
{
char p[100];
int len = 0;
int version = 1;
int type = 10;
int length = 0;
memset(p,0,100);
memcpy(p,&version ,4);
memcpy(&p[4],&type,4);
memcpy(&p[8],&length,4);
length = 10;
memcpy(&p[12],&version ,4);
memcpy(&p[16],&type,4);
memcpy(&p[20],&length,4);
fun(p,30);
return 0;
}
fun函數是用來解析消息的一個函數。有些類似於tcp,是基於流的方式來解析數據包。
但是現在在運行時發生了死循環。即執行程序之後就不會退出。
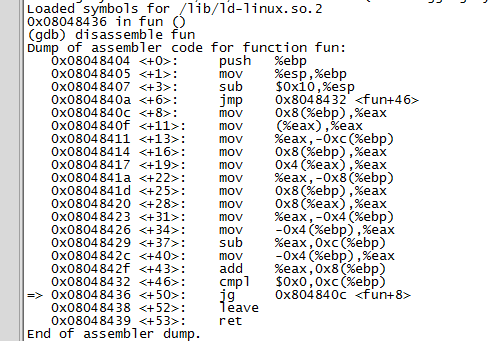
gdb attach上該進程之後,發現是在fun函數裡面,那麼查看源碼知道fun就只有一個循環。那麼現在使用debug版本的可執行程序,單步調試該程序。
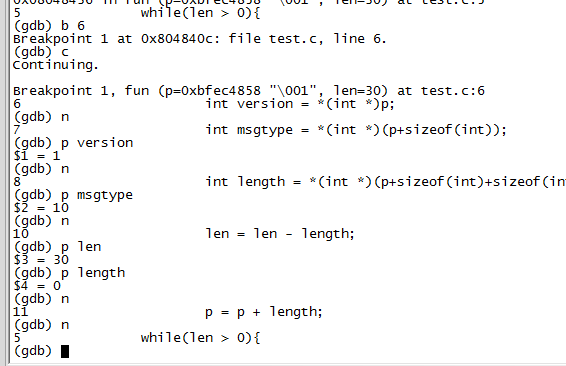
可以發現,消息體的長度一直為0,這個問題導致了,一直在解析同一個消息。那麼問題就確定了,發送的消息長度有問題,所以在函數中解析到長度字段時,應該比較長度字段至少大於多少。
三。總結
首先要熟練運用gdb中的各種工具,包括查看寄存器,堆棧,斷點,監視點和腳本等。
一般來講調試過程是,收集信息,包括現象和dump信息。分析dump信息,復現bug,修復bug。
棧溢出:結合sp和程序map信息。
返回地址被修改:堆棧異常基本屬於返回地址被修改,將sp中的內容打印出來,以各種方式打印,字符型或者十六進制等等。可能會發現比較眼熟的結果打印,比如明顯是一個字符串,這時候對錯誤的定位就很容易了。
非法內存訪問:某個跳轉地址是存放在一個指針中的,這個指針中的值被修改了,也就導致了後續的跳轉出現了非法。這個時候可以在這個指針上設置監視點,打印訪問該監視點時的堆棧。
雙重釋放:還是利用監視點或者斷點,確定哪兩次釋放。
死鎖:同上,確定哪兩步拿鎖沖突。
死循環:確定當前死循環位置,最好使用debug版本單步調試。