shared memory在之前的博文有些介紹,這部分會專門講解其內容。在global Memory部分,數據對齊和連續是很重要的話題,當使用L1的時候,對齊問題可以忽略,但是非連續的獲取內存依然會降低性能。依賴於算法本質,某些情況下,非連續訪問是不可避免的。使用shared memory是另一種提高性能的方式。
GPU上的memory有兩種:
· On-board memory
· On-chip memory
global memory就是一塊很大的on-board memory,並且有很高的latency。而shared memory正好相反,是一塊很小,低延遲的on-chip memory,比global memory擁有高得多的帶寬。我們可以把他當做可編程的cache,其主要作用有:
· An intra-block thread communication channel 線程間交流通道
· A program-managed cache for global memory data可編程cache
· Scratch pad memory for transforming data to improve global memory access patterns
本文主要涉及兩個例子作解釋:reduction kernel,matrix transpose kernel。
shared memory(SMEM)是GPU的重要組成之一。物理上,每個SM包含一個當前正在執行的block中所有thread共享的低延遲的內存池。SMEM使得同一個block中的thread能夠相互合作,重用on-chip數據,並且能夠顯著減少kernel需要的global memory帶寬。由於APP可以直接顯式的操作SMEM的內容,所以又被稱為可編程緩存。
由於shared memory和L1要比L2和global memory更接近SM,shared memory的延遲比global memory低20到30倍,帶寬大約高10倍。
__shared__。
下面這句話靜態的聲明了一個2D的浮點型數組:
__shared__ float tile[size_y][size_x];
如果在kernel中聲明的話,其作用域就是kernel內,否則是對所有kernel有效。如果shared Memory的大小在編譯器未知的話,可以使用extern關鍵字修飾,例如下面聲明一個未知大小的1D數組:
extern __shared__ int tile[];
由於其大小在編譯器未知,我們需要在每個kernel調用時,動態的分配其shared memory,也就是最開始提及的第三個參數:
kernel<<<grid, block, isize * sizeof(int)>>>(...)
應該注意到,只有1D數組才能這樣動態使用。
之前博文對latency和bandwidth有了充足的研究,而shared memory能夠用來隱藏由於latency和bandwidth對性能的影響。下面將解釋shared memory的組織方式,以便研究其對性能的影響。
為了獲得高帶寬,shared Memory被分成32(對應warp中的thread)個相等大小的內存塊,他們可以被同時訪問。不同的CC版本,shared memory以不同的模式映射到不同的塊(稍後詳解)。如果warp訪問shared Memory,對於每個bank只訪問不多於一個內存地址,那麼只需要一次內存傳輸就可以了,否則需要多次傳輸,因此會降低內存帶寬的使用。
當多個地址請求落在同一個bank中就會發生bank conflict,從而導致請求多次執行。硬件會把這類請求分散到盡可能多的沒有conflict的那些傳輸操作 裡面,降低有效帶寬的因素是被分散到的傳輸操作個數。
warp有三種典型的獲取shared memory的模式:
· Parallel access:多個地址分散在多個bank。
· Serial access:多個地址落在同一個bank。
· Broadcast access:一個地址讀操作落在一個bank。
Parallel access是最通常的模式,這個模式一般暗示,一些(也可能是全部)地址請求能夠被一次傳輸解決。理想情況是,獲取無conflict的shared memory的時,每個地址都在落在不同的bank中。
Serial access是最壞的模式,如果warp中的32個thread都訪問了同一個bank中的不同位置,那就是32次單獨的請求,而不是同時訪問了。
Broadcast access也是只執行一次傳輸,然後傳輸結果會廣播給所有發出請求的thread。這樣的話就會導致帶寬利用率低。
下圖是最優情況的訪問圖示:
· Conflict-free broadcast access if threads access the same address within a bank
· Bank conflict access if threads access different addresses within a bank
· 4 bytes for devices of CC 2.x
· 8 bytes for devices of CC3.x
對於Fermi,一個bank是4bytes。每個bank的帶寬是32bits每兩個cycle。連續的32位字映射到連續的bank中,也就是說,bank的索引和shared memory地址的映射關系如下:
bank index = (byte address ÷ 4 bytes/bank) % 32 banks
下圖是Fermi的地址映射關系,注意到,bank中每個地址相差32,相鄰的word分到不同的bank中以便使warp能夠獲得更多的並行獲取內存操作(獲取連續內存時,連續地址分配到了不同bank中)。
bank index = (byte address ÷ 8 bytes/bank) % 32 banks
這裡,如果兩個thread訪問同一個64-bit中的任意一個兩個相鄰word(1byte)也不會導致bank conflict,因為一次64-bit(bank帶寬64bit/cycle)的讀就可以滿足請求了。也就是說,同等情況下,64-bit模式一般比32-bit模式更少碰到bank conflict。
下圖是64-bit的關系圖。盡管word0和word32都在bank0中,同時讀這兩個word也不會導致bank conflict(64-bit/cycle):
cudaError_t cudaDeviceGetSharedMemConfig(cudaSharedMemConfig *pConfig);
返回結果放在pConfig中,其結果可以是下面兩種:
cudaSharedMemBankSizeFourByte
cudaSharedMemBankSizeEightByte
可以使用下面的API來設置bank的大小:
cudaError_t cudaDeviceSetSharedMemConfig(cudaSharedMemConfig config);
bank的配置參數如下三種:
cudaSharedMemBankSizeDefault
cudaSharedMemBankSizeFourByte
cudaSharedMemBankSizeEightByte
在其啟動不同的kernel之間修改bank配置會有一個隱式的device同步。修改shared memory的bank大小不會增加shared memory的利用或者影響kernel的Occupancy,但是對性能是一個主要的影響因素。一個大的bank會產生較高的帶寬,但是鑒於不同的access pattern,可能導致更多的bank conflict。
因為shared Memory可以被同一個block中的不同的thread同時訪問,當同一個地址的值被多個thread修改就導致了inter-thread conflict,所以我們需要同步操作。CUDA提供了兩類block內部的同步操作,即:
· Barriers
· Memory fences
對於barrier,所有thread會等待其他thread到達barrier point;對於Memory fence,所有thread會阻塞到所有修改Memory的操作對其他thread可見,下面解釋下CUDA需要同步的主要原因:weakly-ordered。
現代內存架構有非常寬松的內存模式,也就是意味著,Memory的獲取不必按照程序中的順序來執行。CUDA采用了一種叫做weakly-ordered Memory model來獲取更激進的編譯器優化。
GPU thread寫數據到不同的Memory的順序(比如shared Memory,global Memory,page-locked host memory或者另一個device上的Memory)同樣沒必要跟程序裡面順序呢相同。一個thread的讀操作的順序對其他thread可見時也可能與實際上執行寫操作的thread順序不一致。
為了顯式的強制程序以一個確切的順序運行,就需要用到fence和barrier。他們也是唯一能保證kernel對Memory有正確的行為的操作。
同步操作在我們之前的文章中也提到過不少,比如下面這個:
void __syncthreads();
__syncthreads就是作為一個barrier point起作用,block中的thread必須等待所有thread都到達這個point後才能繼續下一步。這也保證了所有在這個point之前獲取global Memory和shared Memory的操作對同一個block中所有thread可見。__syncthreads被用來協作同一個block中的thread。當一些thread獲取Memory相同的地址時,就會導致潛在的問題(讀後寫,寫後讀,寫後寫)從而引起未定義行為狀態,此時就可以使用__syncthreads來避免這種情況。
使用__syncthreads要相當小心,只有在所有thread都會到達這個point時才可以調用這個同步,顯而易見,如果同一個block中的某些thread永遠都到達該點,那麼程序將一直等下去,下面代碼就是一種錯誤的使用方式:
if (threadID % 2 == 0) {
__syncthreads();
} else {
__syncthreads();
}
這種方式保證了任何在fence之前的Memory寫操作對fence之後thread都可見,也就是,fence之前寫完了,fence之後其它thread就都知道這塊Memory寫後的值了。fence的設置范圍比較廣,分為:block,grid和system。
可以通過下面的API來設置fence:
void __threadfence_block();
看名字就知道,這個函數是對應的block范圍,也就是保證同一個block中thread在fence之前寫完的值對block中其它的thread可見,不同於barrier,該function不需要所有的thread都執行。
下面是grid范圍的API,作用同理block范圍,把上面的block換成grid就是了:
void __threadfence();
下面是system的,其范圍針對整個系統,包括device和host:
void __threadfence_system();
聲明一個使用global Memory或者shared Memory的變量,用volatile修飾符來修飾該變量的話,會組織編譯器做一個該變量的cache的優化,使用該修飾符後,編譯器就會認為該變量可能在某一時刻被別的thread改變,如果使用cache優化的話,得到的值就缺乏時效,因此使用volatile強制每次都到global 或者shared Memory中去讀取其絕對有效值。
該部分會試驗一些使用shared Memory的例子,包括以下幾個方面:
· 方陣vs矩陣數組
· Row-major vs column-major access
· 靜態vs動態shared Memory聲明
· 全局vs局部shared Memory
· Memory padding vs no Memory padding
我們在設計使用shared Memory的時候應該關注下面的信息:
· Mapping data elements across Memory banks
· Mapping from thread index to shared Memory offset
搞明白這兩點,就可以掌握shared Memory的使用了,從而構建出牛逼的代碼。
下圖展示了一個每一維度有32個元素並以row-major存儲在shared Memory,圖的最上方是該矩陣實際的一維存儲圖示,下方的邏輯的二維shared Memory:
__shared__ int tile[N][N];
可以使用下面的方式來數據,相鄰的thread獲取相鄰的word:
tile[threadIdx.y][threadIdx.x]
tile[threadIdx.x][threadIdx.y]
上面兩種方式哪個更好呢?這就需要注意thread和bank的映射關系了,我們最希望看到的是,同一個warp中的thread獲取的是不同的bank。同一個warp中的thread可以使用連續的threadIdx.x來確定。不同bank中的元素同樣是連續存儲的,以word大小作為偏移。因此次,最好是讓連續的thread(由連續的threadIdx.x確定)獲取shared Memory中連續的地址,由此得知,
tile[threadIdx.y][threadIdx.x]應該展現出更好的性能以及更少的bank conflict。
假設我們的grid有2D的block(32,32),定義如下:
#define BDIMX 32 #define BDIMY 32 dim3 block(BDIMX,BDIMY); dim3 grid(1,1);
我們對這個kernel有如下兩個操作:
· 將thread索引以row-major寫到2D的shared Memory數組中。
· 從shared Memory中讀取這些值並寫入到global Memory中。
kernel代碼:
__global__ void setRowReadRow(int *out) {
// static shared memory
__shared__ int tile[BDIMY][BDIMX];
// 因為block只有一個
unsigned int idx = threadIdx.y * blockDim.x + threadIdx.x;
// shared memory store operation
tile[threadIdx.y][threadIdx.x] = idx;
// 這裡同步是為了使下面shared Memory的獲取以row-major執行
//若有的線程未完成,而其他線程已經在讀shared Memory。。。
__syncthreads();
// shared memory load operation
out[idx] = tile[threadIdx.y][threadIdx.x] ;
}
觀察代碼可知,我們有三個內存操作:
· 向shared Memory存數據
· 從shared Memor取數據
· 向global Memory存數據
因為在同一個warp中的thread使用連續的threadIdx.x來檢索title,該kernel是沒有bank conflict的。如果交換上述代碼threadIdx.y和threadIdx.x的位置,就變成了column-major的順序。每個shared Memory的讀寫都會導致Fermi上32-way的bank conflict或者在Kepler上16-way的bank conflict。
__global__ void setColReadCol(int *out) {
// static shared memor
__shared__ int tile[BDIMX][BDIMY];
// mapping from thread index to global memory index
unsigned int idx = threadIdx.y * blockDim.x + threadIdx.x;
// shared memory store operation
tile[threadIdx.x][threadIdx.y] = idx;
// wait for all threads to complete
__syncthreads();
// shared memory load operation
out[idx] = tile[threadIdx.x][threadIdx.y];
}
編譯運行:
$ nvcc checkSmemSquare.cu –o smemSquare $ nvprof ./smemSquare
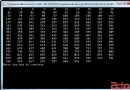
在Tesla K40c(4-byte模式)上的結果如下,正如我們所想的,row-major表現要出色:
./smemSquare at device 0 of Tesla K40c with Bank Mode:4-byte <<< grid (1,1) block (32,32)>> Time(%) Time Calls Avg Min Max Name 13.25% 2.6880us 1 2.6880us 2.6880us 2.6880us setColReadCol(int*) 11.36% 2.3040us 1 2.3040us 2.3040us 2.3040us setRowReadRow(int*)
然後使用nvprof的下面的兩個參數來衡量相應的bank-conflict:
shared_load_transactions_per_request
shared_store_transactions_per_request
結果如下,row-major只有一次transaction:
Kernel:setColReadCol (int*) 1 shared_load_transactions_per_request 16.000000 1 shared_store_transactions_per_request 16.000000 Kernel:setRowReadRow(int*) 1 shared_load_transactions_per_request 1.000000 1 shared_store_transactions_per_request 1.000000 Writing Row-Major and Reading Column-Major
本節的kernel實現以row-major寫shared Memory,以Column-major讀shared Memory,下圖指明了這兩種操作的實現:
__global__ void setRowReadCol(int *out) {
// static shared memory
__shared__ int tile[BDIMY][BDIMX];
// mapping from thread index to global memory index
unsigned int idx = threadIdx.y * blockDim.x + threadIdx.x;
// shared memory store operation
tile[threadIdx.y][threadIdx.x] = idx;
// wait for all threads to complete
__syncthreads();
// shared memory load operation
out[idx] = tile[threadIdx.x][threadIdx.y];
}
查看nvprof結果:
Kernel:setRowReadCol (int*) 1 shared_load_transactions_per_request 16.000000 1 shared_store_transactions_per_request 1.000000
寫操作是沒有conflict的,讀操作則引起了一個16次的transaction。
正如前文所說,我們可以全局范圍的動態聲明shared Memory,也可以在kernel內部動態聲明一個局部范圍的shared Memory。注意,動態聲明必須是未確定大小一維數組,因此,我們就需要重新計算索引。因為我們將要以row-major寫,以colu-major讀,所以就需要保持下面兩個索引值:
· row_idx:1D row-major 內存的偏移
· col_idx:1D column-major內存偏移
kernel代碼:
__global__ void setRowReadColDyn(int *out) {
// dynamic shared memory
extern __shared__ int tile[];
// mapping from thread index to global memory index
unsigned int row_idx = threadIdx.y * blockDim.x + threadIdx.x;
unsigned int col_idx = threadIdx.x * blockDim.y + threadIdx.y;
// shared memory store operation
tile[row_idx] = row_idx;
// wait for all threads to complete
__syncthreads();
// shared memory load operation
out[row_idx] = tile[col_idx];
}
kernel調用時配置的shared Memory:
setRowReadColDyn<<<grid, block, BDIMX * BDIMY * sizeof(int)>>>(d_C);
查看transaction:
Kernel: setRowReadColDyn(int*) 1 shared_load_transactions_per_request 16.000000 1 shared_store_transactions_per_request 1.000000
該結果和之前的例子相同,不過這裡使用的是動態聲明。
直接看kernel代碼:
__global__ void setRowReadColPad(int *out) {
// static shared memory
__shared__ int tile[BDIMY][BDIMX+IPAD];
// mapping from thread index to global memory offset
unsigned int idx = threadIdx.y * blockDim.x + threadIdx.x;
// shared memory store operation
tile[threadIdx.y][threadIdx.x] = idx;
// wait for all threads to complete
__syncthreads();
// shared memory load operation
out[idx] = tile[threadIdx.x][threadIdx.y];
}
改代碼是setRowReadCol的翻版,查看結果:
Kernel: setRowReadColPad(int*) 1 shared_load_transactions_per_request 1.000000 1 shared_store_transactions_per_request 1.000000
正如期望的那樣,load的bank_conflict已經消失。在Fermi上,只需要加上一列就可以解決bank-conflict,但是在Kepler上卻不一定,這取決於2D shared Memory的大小,因此對於8-byte模式,可能需要多次試驗才能得到正確結果。
參考書《professional cuda c programming》