C語言之霍夫曼編碼學習
?
1,霍夫曼編碼描述
哈夫曼樹─即最優二叉樹,帶權路徑長度最小的二叉樹,經常應用於數據壓縮。 在計算機信息處理中,“哈夫曼編碼”是一種一致性編碼法(又稱“熵編碼法”),用於數據的無損耗壓縮。這一術語是指使用一張特殊的編碼表將源字符(例如某文件中的一個符號)進行編碼。這張編碼表的特殊之處在於,它是根據每一個源字符出現的估算概率而建立起來的(出現概率高的字符使用較短的編碼,反之出現概率低的則使用較長的編碼,這便使編碼之後的字符串的平均期望長度降低,從而達到無損壓縮數據的目的)。這種方法是由David.A.Huffman發展起來的。 例如,在英文中,e的出現概率很高,而z的出現概率則最低。當利用哈夫曼編碼對一篇英文進行壓縮時,e極有可能用一個位(bit)來表示,而z則可能花去25個位(不是26)。用普通的表示方法時,每個英文字母均占用一個字節(byte),即8個位。二者相比,e使用了一般編碼的1/8的長度,z則使用了3倍多。若能實現對於英文中各個字母出現概率的較准確的估算,就可以大幅度提高無損壓縮的比例。
2,問題描述
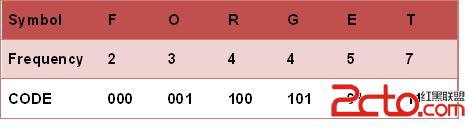
霍夫曼編碼前首先要統計每個字的字頻,即出現次數,例如:

1、將所有字母出現的次數以從小到大的順序排序,如上圖
2、每個字母都代表一個終端節點(葉節點),比較F.O.R.G.E.T五個字母中每個字母的出現頻率,將最小的兩個字母頻率相加合成一個新的節點。如上圖所示,發現F與O的頻率最小,故相加2+3=5,將F、O組成一個樹,F為左節點,O為右節點,(FO)為根節點,每個節點的取值為其出現頻率(FO的出現頻率為5)
3、比較5.R.G.E.T,發現R與G的頻率最小,故相加4+4=8,將RG組成一個新的節點
4、比較5.8.E.T,發現5與E的頻率最小,故相加5+5=10,因此將FO作為左節點,E作為右節點,FOE作為根節點
5、比較8.10.T,發現8與T的頻率最小,故相加8+7=15,將RG作為左節點,T作為右節點,RGT作為根節點
6、最後剩10.15,沒有可以比較的對象,相加10+15=25,FOE作為左節點,RGT作為右節點
根節點不取值,每個左子節點取值0,右子節點取值1,將每個字母從根節點開始遍歷,沿途的取值組成編碼:
首先選擇一個文本,統計每個字符出現的次數,組成以下數組:
typedef struct FrequencyTreeNode {
int freq;
char c;
struct FrequencyTreeNode *left;
struct FrequencyTreeNode *right;
} FrequencyTreeNodeStruct, *pFrequencyTreeNodeStruct;
然後將獲得的數組frequencies進行排序,按照freq由小到大的順序組成一個二叉查找樹,FrequencyTreeNodeStruct,從二叉查找樹中找到最小的節點,從樹中刪除,再取最小的節點,兩個子節點,組成一個新的樹,根節點c為0,freq為兩個子節點的和,加入frequencies中,並排序,重復該步驟,一直到frequencies中只有一個節點,則該節點為Huffman coding tree的根節點
以short類型按照前述的規則為每個字符編碼,爾後將文本翻譯為Huffman coding,再通過Huffman coding tree進行解碼,驗證編碼的正確性。
3,代碼實現
- #include
- #define n 5 //葉子數目
- #define m (2*n-1) //結點總數
- #define maxval 10000.0
- #define maxsize 100 //哈夫曼編碼的最大位數
-
-
- //定義結構體
- typedef struct FrequencyTreeNode {
- int freq;
- char c;
- struct FrequencyTreeNode *left;
- struct FrequencyTreeNode *right;
- } FrequencyTreeNodeStruct, *pFrequencyTreeNodeStruct;
-
-
- FrequencyTreeNodeStruct frequencies[MAXALPABETNUM];
-
-
- typedef struct
- {
- char bits[n]; //位串
- int start; //編碼在位串中的起始位置
- char ch; //字符
- }codetype;
-
-
- // 讀取文件內容,統計字符以及出現頻率
- void readTxtStatistics(char* fileName)
- {
- unsigned int nArray[52] = {0};
- unsigned int i, j;
- char szBuffer[MAXLINE];
- int k=0;
- // 讀取文件內容
- FILE* fp = fopen(fileName, );
- if (fp != NULL)
- { /*讀取文件內容,先統計字母以及出現次數*/
- while(fgets(szBuffer, MAXLINE, fp)!=NULL)
- {
- for(i = 0; i < strlen(szBuffer); i++)
- {
- if(szBuffer[i] <= 'Z' && szBuffer[i] >= 'A')
- {
- j = szBuffer[i] - 'A';
- }
- else if(szBuffer[i] <= 'z' && szBuffer[i] >= 'a')
- {
- j = szBuffer[i] - 'a' + 26;
- }
- else
- continue;
- nArray[j]++;
- }
- }
-
-
- // 然後賦值給frequencies數組
- for(i = 0, j = 'A'; i < 52; i++, j++)
- {
- if (nArray[i] >0)
- {
- /*****/
- frequencies[k].c=j;
- frequencies[k].freq=nArray[i];
- frequencies[k].left=NULL;
- frequencies[k].right=NULL;
- k++;
- printf(%c:%d\n, j, nArray[i]);
- }
- if(j == 'Z')
- j = 'a' - 1;
- }
- }
- }
-
-
- //建立哈夫曼樹
- void huffMan(frequencies tree[]){
- int i,j,p1,p2;//p1,p2分別記住每次合並時權值最小和次小的兩個根結點的下標
- float small1,small2,f;
- char c;
- for(i=0;i
- {
- tree[i].parent=0;
- tree[i].lchild=-1;
- tree[i].rchild=-1;
- tree[i].weight=0.0;
- }
- printf(【依次讀入前%d個結點的字符及權值(中間用空格隔開)】\n,n);
-
-
- //讀入前n個結點的字符及權值
- for(i=0;i
- {
- printf(輸入第%d個字符為和權值,i+1);
- scanf(%c %f,&c,&f);
- getchar();
- tree[i].ch=c;
- tree[i].weight=f;
- }
- //進行n-1次合並,產生n-1個新結點
- for(i=n;i
- {
- p1=0;p2=0;
- //maxval是float類型的最大值
- small1=maxval;small2=maxval;
- //選出兩個權值最小的根結點
- for(j=0;j
- {
- if(tree[j].parent==0)
- if(tree[j].weight
- {
- small2=small1; //改變最小權、次小權及對應的位置
- small1=tree[j].weight;
- p2=p1;
- p1=j;
- }
- else if(tree[j].weight
- {
- small2=tree[j].weight; //改變次小權及位置
- p2=j;
- }
- tree[p1].parent=i;
- tree[p2].parent=i;
- tree[i].lchild=p1; //最小權根結點是新結點的左孩子
- tree[i].rchild=p2; //次小權根結點是新結點的右孩子
- tree[i].weight=tree[p1].weight+tree[p2].weight;
- }
- }
- }
-
-
- //根據哈夫曼樹求出哈夫曼編碼,code[]為求出的哈夫曼編碼,tree[]為已知的哈夫曼樹
- void huffmancode(codetype code[],frequencies tree[])
- {
- int i,c,p;
- codetype cd; //緩沖變量
- for(i=0;i
- {
- cd.start=n;
- cd.ch=tree[i].ch;
- c=i; //從葉結點出發向上回溯
- p=tree[i].parent; //tree[p]是tree[i]的雙親
- while(p!=0)
- {
- cd.start--;
- if(tree[p].lchild==c)
- cd.bits[cd.start]='0'; //tree[i]是左子樹,生成代碼'0'
- else
- cd.bits[cd.start]='1'; //tree[i]是右子樹,生成代碼'1'
- c=p;
- p=tree[p].parent;
- }
- code[i]=cd; //第i+1個字符的編碼存入code[i]
- }
- }
-
-
-
-
- //根據哈夫曼樹解碼
- void decode(hufmtree tree[])
- {
- int i,j=0;
- char b[maxsize];
- char endflag='2'; //電文結束標志取2
- i=m-1; //從根結點開始往下搜索
- printf(輸入發送的編碼(以'2'為結束標志):);
- gets(b);
- printf(編碼後的字符為);
- while(b[j]!='2')
- {
- if(b[j]=='0')
- i=tree[i].lchild; //走向左子節點
- else
- i=tree[i].rchild; //走向右子節點
- if(tree[i].lchild==-1) //tree[i]是葉結點
- {
- printf(%c,tree[i].ch);
- i=m-1; //回到根結點
- }
- j++;
- }
- printf(\ );
- if(tree[i].lchild!=-1&&b[j]!='2') //文本讀完,但尚未到葉子結點
- printf(\ ERROR\n); //輸入文本有錯
- }
-
-
-
-
- void main()
- {
- printf(---------------—— 哈夫曼編碼實戰 ——\n);
- printf(總共有%d個字符\n,n);
- frequencies tree[m];
- codetype code[n];
- int i,j;//循環變量
- huffMan(tree);//建立哈夫曼樹
- huffmancode(code,tree);//根據哈夫曼樹求出哈夫曼編碼
- printf(【輸出每個字符的哈夫曼編碼】\n);
- for(i=0;i
- {
- printf(%c: ,code[i].ch);
- for(j=code[i].start;j
- printf(%c ,code[i].bits[j]);
- printf(\ );
- }
- printf(【讀入內容,並進行編碼】\n);
- // 開始編碼
- decode(tree);
- }