"Giventwo log files, each with a billion usernames (each username appendedto the log file), find the usernames existing in both documents inthe most efficient manner. Use c/c++ code. If your code callspre-existing library functions, create each library function fromscratch. "
Requirement:C/C++.
Submission:Source code and a document to describe your solution.
上面是之前應聘一家公司的研發崗位時,遇到的一道題目,不知道自己做的對不對,覺得挺有趣的,在這裡總結一下思路跟代碼。
當時看到這個題目的第一個反應是使用哈希表解決,
決定使用哈希表後,便開始構思如何創建一個簡單而高效的哈希表,思路是這樣的,因為每個文件的用戶名大約是一億個,為每個用戶申請空間來存放ta對應的字符串是不可能的,但是我們可以這樣,先申請一塊連續的空間,然後將該空間上的每一位都置0。比如我們申請有1000位的連續空間,上面的每一位都置0,然後1000位大約也就125字節,每個字節有8位啊。就是這樣的,因為有大約一億個用戶,我們可以申請1×10位的空間,也就差不多12.5M的空間,將該空間作為哈希表的存儲空間源文件中是hashMap)。
接下來,我們將該空間上的每一位清零源文件中對應的函數是clr)),然後讀取第一個文件,將每個用戶名映射成一個具體的數字作為哈希碼,接著把哈希表上跟該數字對應的位上的值置1源文件中對應的函數是set)),就這樣,讀取完第一個文件的同時也將該文件上所有用戶名對應的哈希空間位置1無論是否重復,我們都置1)。
然後,我們讀取第二個文件,同樣的,先根據用戶名生成相應的哈希碼,然後呢,我們根據哈希碼查詢哈希表上對應的位是否是1,如果是的話,就說明該用戶名在第一個文件出現過,將ta打印到屏幕,然後繼續讀取用戶名,直至讀取完文件。
然後呢,然後就沒有然後啦,哈哈。這就是整個源文件的總體框架。
剛才說完總體框架,接下來就說一下具體的細節,其實比較難的是如何根據用戶名生成相應的哈希碼。
在這裡,我假設文件中的用戶名是包括了字母和數字的字符串,然後我所要做的就是將用戶名對應的字符串映射到一個確切的數字上,那麼應該怎麼做呢?
我想了很久,方案也是挺多的,考慮過將用戶名中的每個字符跟’A’偏移量相乘,然後生成相應的哈希碼,不過這樣子可能會造成不同的用戶名生成相同的哈希碼,所以拋棄了這個想法,也考慮過將每個字符跟’A’的偏移量的平方相加,可是也還是可能出現之前的那種錯誤,想了許久之後決定使用這樣的方案:
將用戶名放在一個字符數組中,然後讀取每個字符還有ta的下標,然後,如果字符是字母的話,就算出該字符跟’A’的偏移量,然後跟其下標+1相乘,如果該字符是數字0-9的話,就算出該數字,然後用該數字跟其下標+1相乘,最後將每個字符所得的乘積相加,就形成了該用戶名的哈希碼。在源文件中對應的函數是hash_code)。
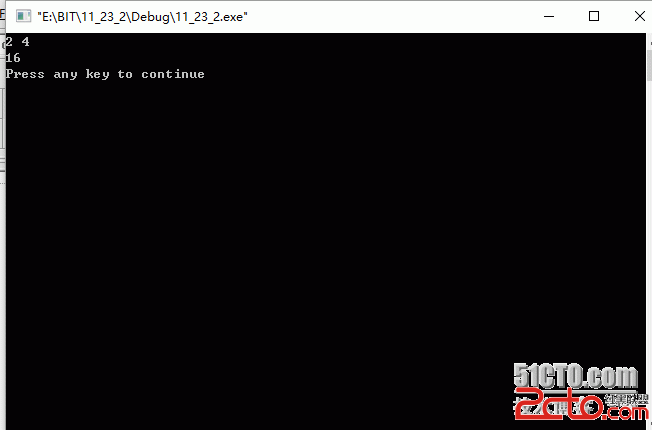
好了,整個方案的大概思路就是這樣,框架跟細節都寫出來了,源文件的編譯沒有問題,但是沒有用數據進行進行測試
#include "stdio.h"
#include "string.h"
#include "stdlib.h"
#define BITSPERWORD 32 //數組元素對應的位數
#define N 100000000 //要申請空間的位數
int hashMap[1 + N/BITSPERWORD];//哈希碼數組
//set 設置i對應的bit位為1
//clr 初始化所有的bit位為0
//test 測試i對應的bit為是否為1
void set(int i) { hashMap[i/32] |= (1<<(i % 32)); }
void clr() {memset(hashMap,0,sizeof(hashMap) * (1 + N/BITSPERWORD));}
int test(int i){ return hashMap[i/32] & (1<<(i %32 )); }
//hahs_code 用於生成用戶名的哈希碼
//mapFile用於將第一個文件中的用戶名映射到hash數組
//findUser用於查找同時存在於兩個文件的用戶名,並顯示到屏幕
void hash_code(char *src, int *hash);
void mapFile(char *fileName);
void findUser(char*fileName);
void main()
{
char filename1[40]; //用於輸入第一個文件名
char filename2[40]; //用於輸入第二個文件名
printf("請輸入第一個文件名:");
gets(filename1);
mapFile(filename1); //將第一個文件的用戶名映射到哈希表
printf("請輸入第二個文件名:");
gets(filename2);
findUser(filename2); //查找並打印相同的用戶名
getcgar();
return ;
}
void mapFile(char *fileName){
FILE *fp;
char str_user[80]; // 用於存放臨時用戶名
int hash = 0; //存放哈希碼
if((fp = fopen(fileName,"r")) == NULL){ //打開指定文件,如果文件不存在,退出
printf("文件不存在!!!\n");
exit(0);
}
while((fscanf(fp,"%s", str_user) )!= EOF){ //將用戶名讀入str_user
hash_code(str_user, &hash); //生成相應的哈希碼
set(hash); //將哈希碼對應的位置1
memset(str_user, '/0', sizeof(str_user)); //清空str_user,進入下一個循環
}
fclose(fp); //關閉文件
}
void findUser(char*fileName){
FILE *fp;
char str_user[80]; // 用於存放臨時用戶名
int hash = 0; //用於存放哈希碼
if((fp = fopen(fileName,"r")) == NULL){ //打開文件,如果文件不存在,退出
printf("文件不存在!!!\n");
exit(0);
}
while((fscanf(fp,"%s", str_user) )!= EOF){ //將用戶名讀入str_user
hash_code(str_user, &hash); //生成相應的哈希碼
if(1 == test(hash) ){ //如果哈希表中哈希碼對應的位是1,則說明該用
printf("該用戶名同時存在於兩個文件:%s\n", str_user); //戶名存在於之前的文件,將該用戶名打印到屏幕
}
memset(str_user, '/0', sizeof(str_user)); //清空str_user,進入下一個循環
}
fclose(fp);
}
void hash_code(char *src, int *hash){ //src是用戶名對應的字符數組,hash用來返回生成的哈希碼
char *p = src;
int index1 = 0; //index1用來存放字符在數組中的位置
int index2 = 0; //index2用來存放字符跟'A'的相對距離,或者跟'0'的相對距離,具體請看代碼或參照文檔
int sum = 0;
while(!p){
index1 += 1;
if((*p >= 'A'&& *p<= 'Z') || (*p >= 'a' && *p <= 'z')){
index2 = *p - 'A';
sum += index1 * index2;
}
else if(*p >= '0' && *p <= '9'){
index2 = *p -'0';
sum += index1 * index2;
}
*(++p);
}
*hash = sum;
return ;
} 在完成這道題之後,把自己的解決方案發給了對方,很快就收到對方的邀請,討論到具體待遇的時候覺得對方給出的條件沒有達到自己的預期,最後拒絕了。自己覺得挺失望的,有時候覺得做開發真的有點廉價,是自己的期望太高嗎?後來有點開始懷疑自己,呵呵
本文出自 “雨落孤林” 博客,請務必保留此出處http://coderlin.blog.51cto.com/7386328/1302480