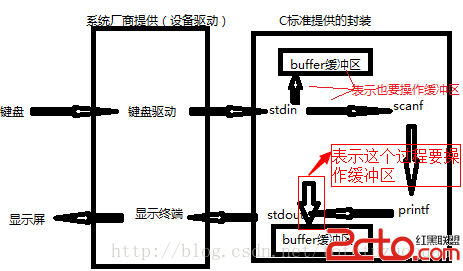
1. 基本函數
在C語言中取隨機數所需要的函數是:
int rand(void);
void srand (unsigned int n);
rand()函數和srand()函數被聲明在頭文件stdlib.h中,所以要使用這兩個函數必須包含該頭文件:
#include <stdlib.h>
2. 使用方法
rand()函數返回0到RAND_MAX之間的偽隨機數(pseudorandom)。RAND_MAX常量被定義在stdlib.h頭文件中。其值等於32767,或者更大。
srand()函數使用自變量n作為種子,用來初始化隨機數產生器。只要把相同的種子傳入srand(),然後調用rand()時,就會產生相同的隨機數序列。因此,我們可以把時間作為srand()函數的種子,就可以避免重復的發生。如果,調用rand()之前沒有先調用srand(),就和事先調用srand(1)所產生的結果一樣。
/* 例1:不指定種子的值 */
for (int i=; i<10; i++)
{
printf("%d ", rand()%10);
}
每次運行都將輸出:1 7 4 0 9 4 8 8 2 4
/* 例2:指定種子的值為1 */
srand(1);
for (int i=; i<10; i++)
{
printf("%d ", rand()%10);
}
每次運行都將輸出:1 7 4 0 9 4 8 8 2 4
例2的輸出結果與例1是完全一樣的。
/* 例3:指定種子的值為8 */
srand(8);
for (int i=; i<10; i++)
{
printf("%d ", rand()%10);
}
每次運行都將輸出:4 0 1 3 5 3 7 7 1 5
該程序取得的隨機值也是在[0,10)之間,與srand(1)所取得的值不同,但是每次運行程序的結果都相同。
/* 例4:指定種子值為現在的時間 */
srand((unsigned)time(NULL));
for (int i=; i<10; i++)
{
printf("%d ", rand()%10);
}
該程序每次運行結果都不一樣,因為每次啟動程序的時間都不同。另外需要注意的是,使用time()函數前必須包含頭文件time.h。
3. 注意事項
求一定范圍內的隨機數。
如要取[0,10)之間的隨機整數,需將rand()的返回值與10求模。
randnumber = rand() % 10;
那麼,如果取的值不是從0開始呢?你只需要記住一個通用的公式。
要取[a,b)之間的隨機整數(包括a,但不包括b),使用:
(rand() % (b - a)) + a
偽隨機浮點數。
要取得0~1之間的浮點數,可以用:
rand() / (double)(RAND_MAX)
如果想取更大范圍的隨機浮點數,比如0~100,可以采用如下方法:
rand() /((double)(RAND_MAX)/100)
其他情況,以此類推,這裡不作詳細說明。
當然,本文取偽隨機浮點數的方法只是用來說明函數的使用辦法,你可以采用更好的方法來實現。
舉個例子,假設我們要取得0~10之間的隨機整數(不含10本身):
大家可能很多次討論過隨機數在計算機中怎樣產生的問題,在這篇文章中,我會對這個問題進行更深入的探討,闡述我對這個問題的理解。
首先需要聲明的是,計算機不會產生絕對隨機的隨機數,計算機只能產生“偽隨機數”。其實絕對隨機的隨機數只是一種理想的隨機數,即使計算機怎樣發展,它也不會產生一串絕對隨機的隨機數。計算機只能生成相對的隨機數,即偽隨機數。
偽隨機數並不是假隨機數,這裡的“偽”是有規律的意思,就是計算機產生的偽隨機數既是隨機的又是有規律的。怎樣理解呢?產生的偽隨機數有時遵守一定的規律,有時不遵守任何規律;偽隨機數有一部分遵守一定的規律;另一部分不遵守任何規律。比如“世上沒有兩片形狀完全相同的樹葉”,這正是點到了事物的特性,即隨機性,但是每種樹的葉子都有近似的形狀,這正是事物的共性,即規律性。從這個角度講,你大概就會接受這樣的事實了:計算機只能產生偽隨機數而不能產生絕對隨機的隨機數。
那麼計算機中隨機數是怎樣產生的呢?有人可能會說,隨機數是由“隨機種子”產生的。沒錯,隨機種子是用來產生隨機數的一個數,在計算機中,這樣的一個“隨機種子”是一個無符號整形數。那麼隨機種子是從哪裡獲得的呢?
下面看這樣一個C程序:
//rand01.c
#include<dos.h>
static unsigned int RAND_SEED;
unsigned int random(void)
{
RAND_SEED=(RAND_SEED*123+59)%65536;
return(RAND_SEED);
}
void random_start(void)
{
int temp[2];
movedata(0x0040,0x006c,FP_SEG(temp),FP_OFF(temp),4);
RAND_SEED=temp[];
}
main()
{
unsigned int i,n;
random_start();
for(i=;i<10;i++)
printf("%u\t",random());
printf("\n");
}
這個程序(rand01.c)完整地闡述了隨機數產生的過程:
首先,主程序調用random_start()方法,random_start()方法中的這一句我很感興趣:
movedata(0x0040,0x006c,FP_SEG(temp),FP_OFF(temp),4);
這個函數用來移動內存數據,其中FP_SEG(far pointer to segment)是取temp數組段地址的函數,FP_OFF(far pointer to offset)是取temp數組相對地址的函數,movedata函數的作用是把位於0040:006CH存儲單元中的雙字放到數組temp的聲明的兩個存儲單元中。這樣可以通過temp數組把0040:006CH處的一個16位的數送給RAND_SEED。
random用來根據隨機種子RAND_SEED的值計算得出隨機數,其中這一句:
RAND_SEED = (RAND_SEED*123+59)%65536;
是用來計算隨機數的方法,隨機數的計算方法在不同的計算機中是不同的,即使在相同的計算機中安裝的不同的操作系統中也是不同的。我在linux和windows下分別試過,相同的隨機種子在這兩種操作系統中生成的隨機數是不同的,這說明它們的計算方法不同。
現在,我們明白隨機種子是從哪兒獲得的,而且知道隨機數是怎樣通過隨機種子計算出來的了。那麼,隨機種子為什麼要在內存的0040:006CH處取?0040:006CH處存放的是什麼?
學過《計算機組成原理與接口技術》這門課的人可能會記得在編制ROM BIOS時鐘中斷服務程序時會用到Intel 8253定時/計數器,它與Intel 8259中斷芯片的通信使得中斷服務程序得以運轉,主板每秒產生的18.2次中斷正是處理器根據定時/記數器值控制中斷芯片產生的。在我們計算機的主機板上都會有這樣一個定時/記數器用來計算當前系統時間,每過一個時鐘信號周期都會使記數器加一,而這個記數器的值存放在哪兒呢?沒錯,就在內存的0040:006CH處,其實這一段內存空間是這樣定義的:
TIMER_LOW DW ? ;地址為 0040:006CH
TIMER_HIGH DW ? ;地址為 0040:006EH
TIMER_OFT DB ? ;地址為 0040:0070H
時鐘中斷服務程序中,每當TIMER_LOW轉滿時,此時,記數器也會轉滿,記數器的值歸零,即TIMER_LOW處的16位二進制歸零,而TIMER_HIGH加一。rand01.c中的
movedata(0x0040,0x006c,FP_SEG(temp),FP_OFF(temp),4);
正是把TIMER_LOW和TIMER_HIGH兩個16位二進制數放進temp數組,再送往RAND_SEED,從而獲得了“隨機種子”。
現在,可以確定的一點是,隨機種子來自系統時鐘,確切地說,是來自計算機主板上的定時/計數器在內存中的記數值。這樣,我們總結一下前面的分析,並討論一下這些結論在程序中的應用:
1.隨機數是由隨機種子根據一定的計算方法計算出來的數值。所以,只要計算方法一定,隨機種子一定,那麼產生的隨機數就不會變。
看下面這個C++程序:
//rand02.cpp
#include <iostream>
#include <ctime>
using namespace std;
int main()
{
unsigned int seed = 5;
srand(seed);
unsigned int r = rand();
cout << r << endl;
}
在相同的平台環境下,編譯生成exe後,每次運行它,顯示的隨機數都是一樣的。這是因為在相同的編譯平台環境下,由隨機種子生成隨機數的計算方法都是一樣的,再加上隨機種子一樣,所以產生的隨機數就是一樣的。
2.只要用戶或第三方不設置隨機種子,那麼在默認情況下隨機種子來自系統時鐘(即定時/計數器的值)
看下面這個C++程序:
//rand03.cpp
#include <iostream>
#include <ctime>
using namespace std;
int main()
{
srand((unsigned)time(NULL));
unsigned int r = rand();
cout << r << endl;
return 0;
}
這裡用戶和其他程序沒有設定隨機種子,則使用系統定時/計數器的值做為隨機種子,所以,在相同的平台環境下,編譯生成exe後,每次運行它,顯示的隨機數會是偽隨機數,即每次運行顯示的結果會有不同。
3.建議:如果想在一個程序中生成隨機數序列,需要至多在生成隨機數之前設置一次隨機種子。
看下面這個用來生成一個隨機字符串的C++程序:
//rand04.cpp
#include<iostream>
#include<time.h>
using namespace std;
int main()
{
int rNum,m = 20;
char *ch = new char[m];
for ( int i = 0; i < m; i++ )
{
//大家看到了,隨機種子會隨著for循環在程序中設置多次
srand((unsigned)time(NULL));
rNum = 1+(int)((rand()/(double)RAND_MAX)*36); //求隨機值
switch (rNum)
{
case 1: ch[i]='a';
break ;
case 2: ch[i]='b';
break ;
case 3: ch[i]='c';
break ;
case 4: ch[i]='d';
break ;
case 5: ch[i]='e';
break ;
case 6: ch[i]='f';
break ;
case 7: ch[i]='g';
break ;
case 8: ch[i]='h';
break ;
case 9: ch[i]='i';
break ;
case 10: ch[i]='j';
break ;
case 11: ch[i]='k';
break ;
case 12: ch[i]='l';
break ;
case 13: ch[i]='m';
break ;
case 14: ch[i]='n';
break ;
case 15: ch[i]='o';
break ;
case 16: ch[i]='p';
break ;
case 17: ch[i]='q';
break ;
case 18: ch[i]='r';
break ;
case 19: ch[i]='s';
break ;
case 20: ch[i]='t';
break ;
case 21: ch[i]='u';
break ;
case 22: ch[i]='v';
break ;
case 23: ch[i]='w';
break ;
case 24: ch[i]='x';
break ;
case 25: ch[i]='y';
break ;
case 26: ch[i]='z';
break ;
case 27:ch[i]='0';
break;
case 28:ch[i]='1';
break;
case 29:ch[i]='2';
break;
case 30:ch[i]='3';
break;
case 31:ch[i]='4';
break;
case 32:ch[i]='5';
break;
case 33:ch[i]='6';
break;
case 34:ch[i]='7';
break;
case 35:ch[i]='8';
break;
case 36:ch[i]='9';
break;
}//end of switch
cout << ch[i];
}//end of for loop
cout << endl;
delete []ch;
return 0;
}
而運行結果顯示的隨機字符串的每一個字符都是一樣的,也就是說生成的字符序列不隨機,所以我們需要把srand((unsigned)time(NULL)); 從for循環中移出放在for語句前面,這樣可以生成隨機的字符序列,而且每次運行生成的字符序列會不同(呵呵,也有可能相同,不過出現這種情況的幾率太小了)。
如果你把srand((unsigned)time(NULL));改成srand(2);這樣雖然在一次運行中產生的字符序列是隨機的,但是每次運行時產生的隨機字符序列串是相同的。把srand這一句從程序中去掉也是這樣。
此外,你可能會遇到這種情況,在使用timer控件編制程序的時候會發現用相同的時間間隔生成的一組隨機數會顯得有規律,而由用戶按鍵command事件產生的一組隨機數卻顯得比較隨機,為什麼?根據我們上面的分析,你可以很快想出答案。這是因為timer是由計算機時鐘記數器精確控制時間間隔的控件,時間間隔相同,記數器前後的值之差相同,這樣時鐘取值就是呈線性規律的,所以隨機種子是呈線性規律的,生成的隨機數也是有規律的。而用戶按鍵事件產生隨機數確實更呈現隨機性,因為事件是由人按鍵引起的,而人不能保證嚴格的按鍵時間間隔,即使嚴格地去做,也不可能完全精確做到,只要時間間隔相差一微秒,記數器前後的值之差就不相同了,隨機種子的變化就失去了線性規律,那麼生成的隨機數就更沒有規律了,所以這樣生成的一組隨機數更隨機。這讓我想到了各種晚會的抽獎程序,如果用人來按鍵產生幸運觀眾的話,那就會很好的實現隨機性原則,結果就會更公正。
最後,我總結兩個要點:
1.計算機的偽隨機數是由隨機種子根據一定的計算方法計算出來的數值。所以,只要計算方法一定,隨機種子一定,那麼產生的隨機數就是固定的。
2.只要用戶或第三方不設置隨機種子,那麼在默認情況下隨機種子來自系統時鐘。
作者“brucema的博客”